次世代要求スケジューラ(NGQP、バージョン3.8.0以降)
スケジューラは、可能な限り迅速にデータを取得するためのクエリ実行プランを作成します。 SQLiteバージョン3.8.0では、スケジューラーは、より速く、より良く動作するように根本的にやり直されました。
クエリが1つのテーブルに対して行われる場合、最適化は簡単です。 クエリが多くのテーブルを結合する場合、実行可能なオプションは千通りあります。 計画者は、不完全な情報に基づいて、これらのオプションのどれが最も効果的に機能するかを決定する必要があります。
SQLiteは、ネストされたループを使用して複数のテーブルを結合するクエリを実行します。テーブルごとに1つ(条件にORまたはINが含まれている場合は追加のループもあります)。 ループは、1つ以上のインデックスを使用するか、テーブルのフルクロールを実行できます。 したがって、計画は2つのタスクで構成されます。
1)ネストサイクルの順序を選択します。
2)各サイクルのインデックスを選択します。
最初のタスクは、2番目のタスクよりもはるかに複雑です。 テーブルの走査順序を選択した後、インデックスの選択は、原則としてすでに簡単です。
SQLiteクエリプランナーは「安定」しています。つまり、次の条件を満たしていれば、同じプランを選択します。
1)データベーススキーマはインデックスに関して変更されていません。
2)ANALYZEを超えていません。
3)SQLITE_ENABLE_STAT3オプションが設定されていません。
4)SQLiteバージョンは変更されていません。
これは、テスト中にクエリが「正常に」動作する場合、同じバージョンのSQLiteの戦闘システムで「正常に」動作することを意味します。 「大規模」データベースは、通常、インデックス統計を常に更新するため、このような保証はしません。
3.8.0より前のバージョンのSQLiteは、複雑なクエリではうまく機能しませんでした。 そのような「難しいケース」の例: Transaction Processing Performance Councilの 「TPC-H Q8」。 このクエリでは、8つのテーブルが結合されています。
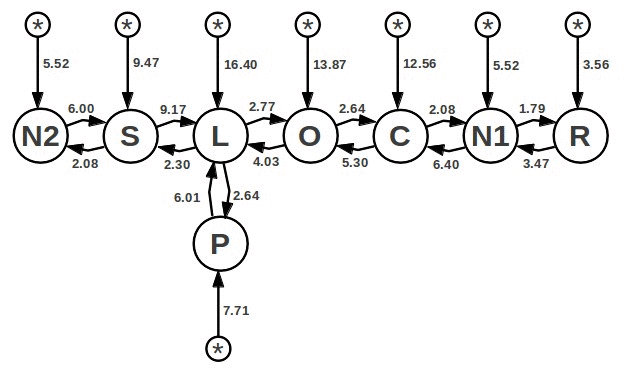
この図では、円はFROMクエリからのテーブルを意味します。 円を結ぶ円弧上に、各サイクルの実行のおおよその「コスト」が書き込まれます。これは、アークの発生元のサイクルが特定のサイクルの外部にあるという仮定に基づいています。 たとえば、サイクルLにサイクルSを投資すると、コストは2.30です。 そして、サイクルLをSに入れると、コストは9.17です。
「コスト」は対数であり、サイクルをネストする場合、それらの値は加算されずに乗算されます。 SサイクルをLに埋め込むことによる6.87の利点は、LがSに埋め込まれている場合よりもSがLに埋め込まれている場合の方がクエリが963倍高速であることを意味します。
アスタリスク付きの円は、依存関係なしでサイクルを実行する価格を示します。 したがって、グラフは双方向であり、計画の問題の解決策は、各頂点を1回バイパスして、最小コストのルートを見つけることです。
実際にはコストの見積もりは常に概算であり、1桁ではなく、さまざまな動作のいくつかの「重み」によって提示されるため、問題のこの説明は単純化されています。 たとえば、「開始」の重みには、自動インデックスを作成する時間が置かれます。 すべてのクエリがこのようなグラフの形式で表されるわけではありません。 クエリにORDER BYが含まれる場合、追加のソートを回避するためにインデックスを使用すると便利です。 などなど。 しかし、TPC-H Q8の場合を考えると、これらの困難はすべて理解のために除外されます。
バージョン3.8.0より前では、SQLiteはヒューリスティックな "Nearest Neighbor"、 "BS"を使用していました。 この場合、グラフの唯一の走査は、最小コストのアークに沿って行われます。 奇妙なことに、これは多くの場合にうまく機能します。 そして、それは高速に動作します。 しかし、残念ながら、「TPC-H Q8」の場合、この方法では36.92のR-N1-N2-SCOLPルートが選択されます。 このレコードは、Rが外部サイクルであり、N1がその中に埋め込まれていることを意味します。実際には、最適なルートはPLOC-N1-RS-N2です。 そのコストは27.38で、その差は取るに足らないようですが、これらが対数値であることを忘れないでください。 したがって、最適なパフォーマンスは750倍速く実行されます。 ソリューションは、すべてのルートの完全な列挙で構成されますが、このような列挙の実行時間は、サイクル数の階乗に比例します。
新しいPlannerは、新しいヒューリスティックを使用して、「N Nearest Neighbors」列のルートを見つけます。 アルゴリズムは、最小コストで単一のネイバーを選択する代わりに、N個のパスを導きます。 N = 4と仮定します。次に、TPC-H Q8で次の最適なルートが選択されます。
R(コスト:3.56)
N1(コスト:5.52)
N2(コスト:5.52)
P(コスト:7.71)
次に、各ルートについて、最小コストで次のステップを選択します。
R-N1(コスト:7.03)
R-N2(コスト:9.08)
N2-N1(コスト:11.04)
RP(コスト:11.27)
第三段階:
R-N1-N2(コスト:12.55)
R-N1-C(コスト:13.43)
R-N1-P(コスト:14.74)
R-N2-S(コスト:15.08)
等 テーブルの数に応じて、合計で8つのステップが可能です。 Kサイクルの一般的な場合、計算時間はO(K * N)であり、O(2 ^ K)にはほど遠いです。
しかし、使用する価値のあるNの値は何ですか? たぶんN = K?
実際には、「N Nearest Neighbors」はN = 10のTPC-H Q8の最適なバージョンを見つけます。現在、SQLiteには次の定数が縫い付けられています。N= 1の単純なクエリ、N = 5のクエリ2サイクルを超えるすべてのクエリ。 おそらく、これらの定数は将来変更されるでしょう。
SQLite 3.8.0にアップグレードすると、一部のクエリの実行が遅くなる場合があります。
ANALYZEを完了!
新しいスケジューラは、インデックスによって収集される統計に強く結び付けられています。
部分インデックス (バージョン3.8.0以降の部分インデックス)
部分インデックスを使用すると、インデックスから一部のレコードを除外する条件を指定できます。 「クラシック」な使用方法:
CREATE INDEX po_parent ON purchaseorder(parent_po) WHERE parent_po IS NOT NULL;
空のparent_poを持たないエントリのみがpo_parentインデックスに含まれます 。 テーブル内にparent_poが空のレコードが多数ある場合、インデックスにはこれらのレコードがまったく含まれないため、リソースを大幅に節約できます。
トリッキーな使用方法。 人々がチームに分かれているとします。 各チームには、チームに含まれるリーダーがいます。 例:
CREATE TABLE person( person_id INTEGER PRIMARY KEY, team_id INTEGER REFERENCES team, is_team_leader BOOLEAN, -- );
チームにリーダーが1人しかいないことを保証するにはどうすればよいですか? (team_id、is_team_leader)によって一意のインデックスを作成することは不可能です。 彼はチームに複数の「非リーダー」を含めることを許可しないので。 解決策は、部分インデックスを作成することです。
CREATE UNIQUE INDEX team_leader ON person(team_id) WHERE is_team_leader;
このインデックスは、チームリーダーをすばやく見つけるのに役立ちます。
SELECT person_id FROM person WHERE is_team_leader AND team_id=?1;
同時に、チームに2人目のリーダーを追加することはできません。
メモリマッピングを使用した入出力 (メモリマップドI / O、バージョン3.7.17以降)
SQLiteは「仮想環境」で実行されます。 読み取りファイル、ロックなどでオペレーティングシステムの「外の世界」を隠す特別な呼び出しテーブルを使用します。バージョン3.7.17より前では、データの読み取りと書き込みは環境のxRead ()およびxWrite ()呼び出しを使用していました。 これらの呼び出しは通常、オペレーティングシステムの「ファイルから読み取る」および「ファイルに書き込む」API呼び出しに変換されます。 バージョン3.7.17から、SQLiteは通常のI / Oの代わりにメモリマップI / Oを使用できます(新しい呼び出し: xFetch ()およびxUnfetch ())。
データを正常に読み取る場合、SQLteはバッファーを割り当て、システムにページごとにデータを読み取るように要求します。 この場合、データは常にメモリにコピーされます。 メモリマッピングを使用する場合、SQLiteはメモリロケーションポインタを取得します。 ファイルが既にダウンロードされている場合、コピーは行われないため、生産性が向上します(最大
ただし、欠点もあります。 ディスクとのメモリ同期はシステムによって即座に実行されるため、バッファオーバーフローエラーはすぐにデータベースを破壊します。 しかし、これは悲しいことではありません。 悪いニュースは、新しいスキーマのI / OエラーがSQLiteによって「キャッチ」されないことです。 代わりに、アプリケーションは終了のシグナルを受け取ります(Windowsシステムでの動作は私には不明です-誰かがコメントに書いているかもしれません)。
また、特定の作業スキームでは、パフォーマンスが低下する可能性もあります。
マップされたI / Oを有効にするには、次のコマンドを使用します。
PRAGMA mmap_size=268435456;
この値は、データベースごとのメモリバッファの最大サイズを設定します。 無効にする:
PRAGMA mmap_size=0;
それがすべてのニュースです。 レビューが役に立つことを願っています。 SQLite の詳細なリリース履歴については、ここをクリックしてください 。
PS。 最新のマネージャーを使用して、SQLiteデータベースを管理します。