 私がRubyコミュニティで過ごしたほとんどの時間、悪名高いGILは私にとってダークホースのままでした。 この記事では、GILをよりよく理解する方法について説明します。
私がRubyコミュニティで過ごしたほとんどの時間、悪名高いGILは私にとってダークホースのままでした。 この記事では、GILをよりよく理解する方法について説明します。
GILについて最初に聞いたのは、GILの仕組みや目的とはまったく関係ありませんでした。 私が聞いたのは、GILが同時実行性を制限するために悪いこと、またはコードをスレッドセーフにするために良いということだけです。 時が来て、マルチスレッドプログラミングに慣れ、すべてが実際にはより複雑であることに気付きました。
GILがどのように機能するかを技術的な観点から知りたいと思いました。 GILに関する仕様やドキュメントはありません。 これは基本的にMRI(MatzのRuby実装)の機能です。 MRI開発チームは、GILがどのように機能し、何を保証するかについては何も述べていません。
しかし、私は自分自身に先んじています。
GILについてまったく知らない場合は、簡単な説明を以下に示します。
MRIにはGIL(グローバルインタープリターロック)と呼ばれるものがあります。 そのおかげで、マルチスレッド環境では、ある時点で、Rubyコードを1つのスレッドでのみ実行できます。
たとえば、8コアプロセッサで8つのスレッドを実行している場合、一度に実行できるスレッドは1つだけです。 GILは、データの整合性を損なう可能性のある条件の競合を防ぐように設計されています。 微妙な点もありますが、本質は次のとおりです。
2008年の並列処理はイリヤグリゴリックによるRubyの神話の記事から、GILの一般的な理解を得ました。 これは単なる一般的な理解であり、技術的な問題に対処する助けにはなりません。 特に、GILがRubyの特定の操作のスレッドセーフを保証するかどうかを知りたいです。 例を挙げましょう。
配列へのアイテムの追加はスレッドセーフではありません
Rubyでは、スレッドセーフはほとんどありません。 たとえば、配列に要素を追加する
array = [] 5.times.map do Thread.new do 1000.times do array << nil end end end.each(&:join) puts array.size
この例では、5つのスレッドのそれぞれが同じ配列に1000回
nil
追加します。 結果として、配列には5,000個の要素が必要です。
$ ruby pushing_nil.rb 5000 $ jruby pushing_nil.rb 4446 $ rbx pushing_nil.rb 3088
=(
このような単純な例でも、スレッドセーフではない操作に直面しています。 何が起こっているのかを理解します。
MRIを使用してコードを実行すると、正しい結果が得られることに注意してください( このコンテキストでは、おそらく「期待」という言葉を好むでしょう-約Per ) 。しかし、JRubyとRubiniusはそうではありません。 コードを再度実行すると、状況が繰り返され、JRubyとRubiniusが他の(まだ正しくない)結果を出します。
結果の違いは、GILの存在によるものです。 MRIにはGILがあるため、5つのスレッドが並行して動作するという事実にもかかわらず、常に1つだけがアクティブになります。 つまり、ここでは真の並列性は観察されません。 JRubyとRubiniusにはGILがないため、5つのスレッドが並列に動作する場合、利用可能なカーネル間で実際に並列化され、スレッドセーフでないコードを実行すると、データの整合性に違反する可能性があります。
同時スレッドがデータの整合性を損なう理由
これはどのようにできますか? Rubyはこれを許可しないだろうと思いましたか? 技術的にどのように可能か見てみましょう。
MRI、JRuby、Rubiniusのいずれの場合でも、Rubyは別の言語で実装されています。MRIはC、JRubyはJava、RubiniusはRubyとC ++で記述されています。 したがって、Rubyで単一の操作(たとえば、
array << nil
)を実行すると、その実装が数十行または数百行のコードで構成されることが判明する場合があります。 以下は、MRIの
Array#<<
実装です。
VALUE rb_ary_push(VALUE ary, VALUE item) { long idx = RARRAY_LEN(ary); ary_ensure_room_for_push(ary, 1); RARRAY_ASET(ary, idx, item); ARY_SET_LEN(ary, idx + 1); return ary; }
少なくとも4つの異なる操作があることに注意してください。
- 現在の配列の長さを取得する
- 別のアイテムのメモリを確認する
- 配列にアイテムを追加する
- 配列の長さを古い値+ 1に割り当てる
それぞれが他の機能を参照します。 並列ストリームがデータの整合性をどのように破壊するかを示すために、これらの詳細に注目します。 線形のステップバイステップのコード実行に慣れています-シングルスレッド環境では、Cの短い関数を見て、コード実行順序を簡単に追跡できます。
しかし、複数のスレッドを扱っている場合、これを行うことはできません。 2つのスレッドがある場合、それらは関数コードの異なる部分を実行でき、コード実行の2つのチェーンに従う必要があります。
さらに、スレッドは共有メモリを使用するため、データを同時に変更できます。 スレッドの1つは別のスレッドを中断し、一般データを変更します。その後、他のスレッドは、データが変更されたことを認識せずに実行を続けます。 これが、一部のRuby実装が単に配列に
nil
を追加するだけで予期しない結果を生成する理由です。 この状況は、以下で説明する状況と似ています。
最初は、システムは次の状態にあります。

2つのスレッドがあり、それぞれが関数の実行を開始しようとしています。 手順1〜4を、上記のMRIの
Array#<<
実装の擬似コードとします。 以下は、イベントの可能な展開です(最初の瞬間、フローAはアクティブです)。
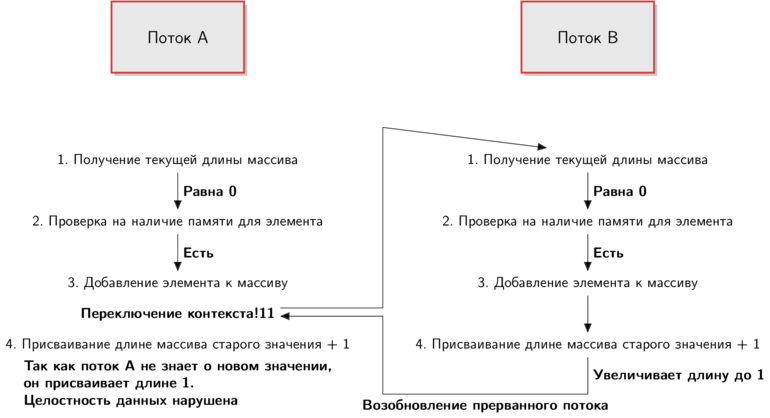
何が起こっているのかを理解するには、矢印に従ってください。 各ストリームの観点から物事の状態を反映した碑文を追加しました。
これは、考えられるシナリオの1つにすぎません。
スレッドAは機能コードの実行を開始しますが、キューがステップ3に進むと、コンテキストが切り替わります。 スレッドAが一時停止し、スレッドBがターンします。スレッドBはすべての機能コードを実行し、要素を追加して配列の長さを増やします。
その後、スレッドAは停止したポイントから正確に再開します。これは、配列の長さを増やす直前に発生しました。 スレッドAは配列の長さを
1
ます。 しかし、ストリームBはすでにデータを変更しています。
繰り返しますが、スレッドBは配列の長さを
1
に設定します。その後、両方のスレッドが配列に要素を追加したにもかかわらず、スレッドAも
1
割り当てます。 データの整合性が壊れています。
そして、私はRubyに頼っていました
上記のシナリオは、JRubyとRubiniusの場合に見たように、誤った結果につながる可能性があります。 しかし、JRubyとRubiniusでは、これらの実装ではスレッドが実際に並行して動作できるため、さらに複雑です。 図では、一方のスレッドが他方のスレッドの実行中に一時停止しますが、真の並行性の場合、両方のスレッドが同時に実行できます。
JRubyまたはRubiniusを使用して上記の例を数回実行すると、結果が常に異なることがわかります。 コンテキストの切り替えは予測不能です。 それは遅かれ早かれ起こるかもしれないし、全く起こらないかもしれない。 次のセクションでこのトピックに触れます。
なぜRubyはこの狂気から私たちを守らないのですか? 他の言語の基礎となるデータ構造がスレッドセーフではないのと同じ理由で、これは高すぎます。 Rubyの実装には、スレッドセーフなデータ構造が含まれている場合がありますが、これにはコードをさらに遅くするオーバーヘッドが必要になります。 したがって、スレッドセーフの負担はプログラマーに移りました。
GILの実装の技術的な詳細についてはまだ触れていませんが、主要な質問は未解決のままです。MRIでコードを実行しても正しい結果が得られるのはなぜですか?
この質問が私がこの記事を書いた理由でした。 GILの一般的な理解は答えを提供しません:常に1つのスレッドのみがRubyコードを実行できることは明らかです。 しかし、関数の途中でコンテキストの切り替えを行うことはできますか?
しかし、最初に...
プランナーを責める
コンテキストの切り替えは、OSスケジューラのタスクです。 上記のすべての実装では、1つのネイティブスレッドが1つのRubyスレッドに対応しています。 OSは、使用可能なすべてのリソース(CPU時間など)をキャプチャするスレッドがないことを確認する必要があるため、各スレッドがリソースにアクセスできるようにスケジュールを実装します。
ストリームの場合、これは一時停止して再開することを意味します。 各スレッドはプロセッサー時間を受け取り、その後、中断され、次のスレッドはリソースへのアクセスを受け取ります。 時間が来ると、フローが再開されます。
これはOSの観点からは効果的ですが、ランダム性を導入し、プログラムの正確性についての見方を再考する動機を与えます。 たとえば、
Array#<<
実行する場合、スレッドはいつでも停止でき、別のスレッドは同じコードを並列に実行して、一般データを変更できることに注意してください。
解決策? アトミック操作を使用する
スレッドが間違った場所で中断されないようにしたい場合は、アトミック操作を使用して、完了が中断されないようにします。 このため、この例では、手順3でストリームが中断されることはなく、最終的に手順4でデータの整合性を侵害しません。
アトミック操作を使用する最も簡単な方法は、ブロッキングに頼ることです。 次のコードは、Mutexのおかげで、MRI、JRuby、Rubiniusで同じ予測可能な結果を生成します。
array = [] mutex = Mutex.new 5.times.map do Thread.new do mutex.synchronize do 1000.times do array << nil end end end end.each(&:join) puts array.size
いずれかのスレッドが
mutex.synchronize
ブロックの実行を開始すると、他のスレッドは同じコードの実行を開始する前にブロックの完了を待機するように強制されます。 アトミック操作を使用すると、コンテキストスイッチがブロック内で発生した場合、他のスレッドがそれを入力して一般データを変更することはできません。 スケジューラはこれに気付き、フローを再度切り替えます。 これで、コードはスレッドセーフになりました。
GILもロックです
ロックを使用してアトミック操作を作成し、スレッドの安全性を確保する方法を説明しました。 GILもロックですが、コードをスレッドセーフにしますか? GILは
array << nil
をアトミック操作に変換しますか?
翻訳者はコメントや建設的な批判を喜んで聞きます。