例を挙げましょう。数字を子音文字でエンコードする場合、各単語または文は整数に対応します。 通常、次のエンコード方法が選択されます:1-p、2-d、3-t、4-h、5-p、6-sh、7-s、8-c、9th(9は「たくさん」だからです)。 それから、「私の良き友」という言葉は番号219513に対応します。しかし、これはやや不便です。 219513.数字自体は非常に抽象的であり、他の同様の抽象数字と簡単に混同される可能性があるため、これは非常に魅力的です。
ニーモニックに関する多くの情報があります。ここでは、車輪を再発明するのではなく、テキスト選択の可能性を使用しようとしました。
念のため、ウィキペディアの定義は次のとおりです:ニーモニック(ギリシャ語、暗記の技術)、ニーモニック-必要な情報の記憶を促進し、関連付け(接続)を形成することで記憶量を増やす特別な手法と方法のセット。 視覚的、聴覚的、または運動感覚的な表現を持つ概念と表現で抽象的なオブジェクトと事実を置き換え、オブジェクトをさまざまなタイプのメモリ内の既存の情報に関連付けて、暗記を簡素化します。
この場合、数字の抽象的なセットをテキストのパッセージと一致させると、画像で埋められ、覚えやすくなります。 すでに述べたように、アイデアはこのテキストを自動的にピックアップすることです。 これらはすべてよく知られたものであり、発明するつもりはまったくありません。ニーモニック自体に興味がある人には教科書を読むことをお勧めします[1]。
最初の文字コーディング
元のアイデアは、学校のカリキュラムの詩的な部分から引用符を選択しようとすることでした。引用符は、特定の車番号、つまり文字three_numerals-two_文字(地域コードのない通常の番号)のランダムなシーケンスに対応します。 最初の文字が最初の単語を生成し、3桁のそれぞれが子音によってエンコードされ、それぞれが単語を生成し、最後の2文字がさらに2単語であると想定されました。 さらに、ロシアの車番号には文字を含めることはできません。a、b、c、e、n、t、m、o、k、p、y、xの12文字のみが使用されます。 ユージン・オネーギン、ポルタヴァ、ルスランとリュドミラ、ロミオとジュリエット+クリロフのable話:いくつかの主要な詩が撮影されました。 分析中に、これらの作品からの引用が選択される1000個の乱数が生成されます
次のスクリプトが作成されました。
#!/usr/bin/php <?php $path="school/"; $letters = array("", "", "", "", "", "", "", "", "", "", "", ""); $numbers = array("", "", "", "", "", "", "", "", "", ""); // ( array_rand , , ) function rn($a) { return $a[rand(0, count($a)-1)]; } // function getmax($handle, $required) { $result=array(); $max = 0; $queue = array(); fseek($handle, 0); while (($buffer = fgets($handle, 4096)) !== false) { $words=explode(" ", $buffer); for ($j=0;$j<count($words); $j++) { // $w = mb_strtolower(trim($words[$j], " \t.,\n\r0123456789:-!;?"), "UTF-8"); if (!$w) continue; $queue[]=$w; $avail = min(count($required), count($queue)); $match = $avail; for ($k=0;$k<$avail;$k++) { if (mb_strpos($queue[$k], $required[$k], 0, "UTF-8")!==0) { $match = $k; break; } } if ($max<$match) $max=$match; if ($match===count($required)) { $result[]=array_splice($queue, 0, $match); return array($max, $result); } if (count($queue)>=count($required)) array_shift($queue); } } return array($max, $result); } $plates = array(); for ($i=0;$i<1000;$i++) $plates[]=array(rn($letters), rn($numbers), rn($numbers), rn($numbers), rn($letters), rn($letters)); $files=scandir($path); for ($i=0;$i<count($files);$i++) { if (is_dir($path.$files[$i])) continue; $handle = @fopen($path.$files[$i], "r"); if ($handle) { $cnt=array(0,0,0,0,0,0,0); $max = 0; $avg = 0; $best = array(); for ($j=0;$j<count($plates);$j++) { list($c, $seq) = getmax($handle, $plates[$j]); if (($max && $max<$c) || !$max) { $max = $c; $best=array(implode("", $plates[$j])=>$seq);} else if ($max===$c) $best[implode("", $plates[$j])]=$seq; $cnt[$c] += 1; $avg += $c; } $avg/=count($plates); print $files[$i]."\t".$avg; for ($j=0;$j<count($cnt);$j++) print "\t".$cnt[$j]; print "\n"; print_r($best); fclose($handle); } }
コードに少しコメントを付けると、すべての着信ワードがキューに追加され、選択されたシーケンスの長さ以下になります。 最大一致の長さが記憶されます。 したがって、テキストを使用してエンコードできる最初からの文字の最大数がわかります。
結果は次のとおりです。
| 役職 | 平均 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ボリューム |
| クリロフのF話 | 2.434 | 0 | 35 | 530 | 403 | 30 | 2 | 0 | 83Kb |
| ユージン・オネーギン | 3.237 | 0 | 0 | 120 | 549 | 306 | 24 | 1 | 1.1 Mb |
| ポルタバ | 2.507 | 0 | 17 | 510 | 424 | 47 | 2 | 0 | 85Kb |
| ロミオとジュリエット | 2.821 | 0 | 36 | 239 | 598 | 122 | 5 | 0 | 219Kb |
| ルスランとリュドミラ | 2.617 | 0 | 68 | 359 | 469 | 97 | 6 | 1 | 138Kb |
これらの結果は私を喜ばせなかったと言えます。1000のうち2つの数字だけが引用を拾うことが判明しました。 次の2つの引用符を見てみましょう:m052rk-“ mine”。 彼らは、中毒になった魂をJしています。 o817vs-「炎症を起こしたルスランから突然隠れた。」 これらのフレーズの論理は確かに存在しますが、不完全性と断片化により、暗記は単純すぎません。 それにもかかわらず、テストでは、これらのテキストに基づいてさえ、ほとんどの場合、3文字のシーケンスを生成することがわかりました。
もちろん、私は興味を持ちました:テキストが大きくなるとどうなりますか? おそらく、より多くのフラグメントが表示され、そこからすでに選択することができます。 次のテストのために、私はモシュコフの図書館から選択しました:聖書の翻訳の聖書の2つの聖書、すべての主要なボードレールの詩、すべてのドストエフスキーの小説、「ホビット、またはそこと背中」、詩のすべてのプーシキンの小説、すべてのシェークスピアの小説、すべてのトルストイの小説 次の結果が得られました。
| 役職 | 平均 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ボリューム |
| 旧約聖書 | 3.09 | 0 | 0 | 188 | 557 | 235 | 17 | 3 | 1.1 Mb |
| 新約聖書 | 3.126 | 0 | 13 | 180 | 498 | 289 | 17 | 3 | 1.5 Mb |
| ドストエフスキー | 4.053 | 0 | 0 | 10 | 206 | 526 | 237 | 21 | 15 Mb |
| トールキン | 3.12 | 0 | 10 | 148 | 581 | 234 | 27 | 0 | 807Kb |
| プーシキン | 3.234 | 0 | 0 | 114 | 565 | 295 | 25 | 1 | 1.2 Mb |
| ボードレール | 2.943 | 0 | 4 | 231 | 594 | 160 | 11 | 0 | 461Kb |
| シェークスピア | 4.489 | 0 | 0 | 0 | 49 | 474 | 416 | 61 | 64 Mb |
| トルストイ | 3.96 | 0 | 0 | 8 | 236 | 555 | 190 | 11 | 11 Mb |
引用自体は非常に多くなることがわかったので、読者を飽きさせないように、私は彼らにすべてを与えません、私は彼らの性格が同じままで、いくつかの未完成で神秘的であることを言及します:488数千、彼は叫んだ、三千、「m081ではない-」奴隷制はあなたから私に喜びです。 あります。」 それらすべてを読んだ後、本にふさわしい占いの考え(彼らがランダムなページを開いて、ランダムな行を読み、自分の生活の枠組みの中で何らかの方法でそれを解釈しようとするとき)が訪れます。 しかし、私はそのような目標を設定しませんでした。
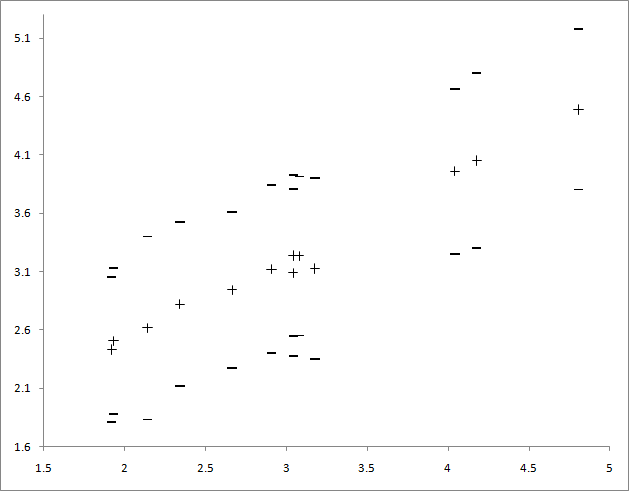
ボリュームの平均対10進対数のグラフ(Y-平均、標準偏差のプラスまたはマイナス、X-使用されたテキストのボリュームの対数)
原則として、この種の依存関係は推測できます。ここでは、聖書の2つのボリュームのみがわずかにノックアウトされていますが、それ以外の場合、ボリュームは対数に比例して増加します。
長さコーディング
最初に頭に浮かぶのは、あまりにも多くのテキストをエンコードする方法が問題から除外されていることです。つまり、数字の場合は10文字しか使用されず、文字12の場合、残りの単語は連鎖を中断するだけです。 もちろん、すべての文字を使用するか、少なくとも子音だけを使用する他のコーディング方法を考え出すことができます。 これらの方法は文献に記載されていますが、私の考えは、使いやすいツールを作成して、フレーズがこの数字にどのように対応するか、どの文字を破棄し、どの文字を考慮するかについてユーザーが困惑しないようにすることでした。そうでなければ可能です最初の重要な文字にコーディングを適用すると、明確になりますが、人にとっては便利ではありません。 アイデアは、単語の文字数で数字をエンコードするようになりました。 このようなコーディングでは、ゼロを表す問題が発生しますが、今のところこれについては詳しく説明しません。 比較するために、同じセットで同じルールに従って一連のテストを実施しました(コードはほぼ同じであるため、リストは1回の繰り返しになります)。
| 役職 | 平均 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ボリューム |
| クリロフのF話 | 2.831 | 0 | 96 | 203 | 490 | 197 | 13 | 1 | 83Kb |
| オネーギン | 3.497 | 0 | 96 | 85 | 166 | 536 | 113 | 4 | 1.1 Mb |
| ポルタバ | 2.808 | 0 | 96 | 231 | 459 | 199 | 13 | 2 | 85Kb |
| ロミオとジュリエット | 3.149 | 0 | 96 | 116 | 377 | 371 | 34 | 6 | 219Kb |
| ルスランとリュドミラ | 2.94 | 0 | 96 | 178 | 443 | 258 | 23 | 2 | 138Kb |
状況ははるかに良いと言えます。「1」列の同じ数字96だけが即座に警告を発します。ここでは、最初の文字ではなく最初の文字では単語が見つかった数字が計算されます。 これらは自然にゼロから始まる数字であり、これらの数字の約100は2列目と3列目にあります。ご覧のとおり、85以下です。結果の引用の例:v325nm-「あなたへ:私はうれしいです...正しくありません。」 詩の場合の不連続性は、行頭から引用することで補うことができます。ユーザーは、詩のどこから数字が始まるかをさらに覚えておく必要があります。たとえば、引用された引用は次のように表示されます。前の行:「ああ、優雅な騎士、私はあなたに誓います:私はうれしいです...私は正しいことはできません。」 しかし、すでにフレーズの始まりは明らかではなくなっています。 フレーズの先頭を覚えている場合は、ゼロの位置を個別に覚えることもできます。 おそらく誰かがそのようなアイデアをm笑だと思うかもしれませんが、少なくとも私はそれを適用できると思います。
このアイデアを適用すると、次の結果が得られます。
| 役職 | 平均 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ボリューム |
| クリロフのF話 | 3.444 | 0 | 0 | 114 | 426 | 367 | 88 | 5 | 83Kb |
| オネーギン | 4.26 | 0 | 0 | 2 | 93 | 596 | 261 | 48 | 1.1 Mb |
| ポルタバ | 3.413 | 0 | 0 | 132 | 414 | 367 | 83 | 4 | 85Kb |
| ロミオとジュリエット | 3.791 | 0 | 0 | 39 | 298 | 508 | 143 | 12 | 219Kb |
| ルスランとリュドミラ | 3.611 | 0 | 0 | 83 | 356 | 445 | 99 | 17 | 138Kb |
| 旧約聖書 | 4.189 | 0 | 0 | 5 | 126 | 585 | 243 | 41 | 1.1 Mb |
| 新約聖書 | 4.292 | 0 | 0 | 3 | 83 | 581 | 285 | 48 | 1.5 Mb |
| ドストエフスキー | 5.019 | 0 | 0 | 0 | 0 | 208 | 565 | 227 | 15 Mb |
| トールキン(ホビット) | 4.123 | 0 | 0 | 2 | 155 | 587 | 230 | 26 | 807Kb |
| プーシキン | 4.251 | 0 | 0 | 3 | 94 | 593 | 269 | 41 | 1.2 Mb |
| ボードレール | 3.946 | 0 | 0 | 18 | 214 | 591 | 158 | 19 | 461Kb |
これらのデータによると、確率が22%の乱数の場合、ドストエフスキーから適切な見積りを取得できるということは悪いことではないと考えられます。 引用はもちろん、過去の場合のように非常に重要です:725-「陽気な仕事を陽気に見ます」、m582to-「私の言葉は彼女に触れたようです、彼女」、m385ns-「一方、奇跡によって、異常な類似性があります」、514nt- 「血なまぐさい戦いと群衆の日が来ました。」
しかし、車の番号ではなく、電話番号を生成するとどうなりますか? すぐに言ってやった:
| 役職 | 平均 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| クリロフのF話 | 4.145 | 0 | 23 | 270 | 387 | 214 | 71 | 35 |
| オネーギン | 5.248 | 0 | 0 | 9 | 260 | 347 | 242 | 142 |
| ポルタバ | 4.131 | 0 | 16 | 293 | 385 | 193 | 76 | 37 |
| ロミオとジュリエット | 4.608 | 0 | 0 | 138 | 374 | 286 | 146 | 56 |
| ルスランとリュドミラ | 4.349 | 0 | 11 | 212 | 381 | 256 | 93 | 47 |
これらの結果は、ほぼ40%の確率の6桁の乱数に対して、「Eugene Onegin」という作品からの対応する引用があることを示唆しています。これらは覚えやすい詩です(最も可能性の高い人ではなく、大多数の人にとっても、 )
他の方法
舞台裏に残った他の可能性:テキストの生成、つまり、特定の構造の対応する単語または文の生成(必要な文字数または方法でも)、原則として、これはコンピューターなしで長い間行われてきました。 文献に示されている教科書では、0から1000までの数字ごとに著者が選択した単語を提供していますが、残念ながら、この方法では画像を結合できないため、大きな数字を覚えることができません。 それは理解可能であり、すべてが重複し始めます。 簡単な方法を次に示します。たとえば、3(03から)-医師、7-x(フォームのため)、5-金曜日など、一般的な関連付けで数字をエンコードできます。 この場合、各桁(位置ごと)に3つの数字を選択すると、すべての3桁の数字を「375-医師は金曜日に切断されました」などの非常に鮮明なストーリーでエンコードできますが、すべてが邪魔になり始めるため、非常に少数の数字しか記憶できません。医師が今回ハッキングされた正確な時期を覚えておくために、追加の類似点を描きます。
おわりに
単語長生成アルゴリズムは、モバイルデバイスで車の番号を認識するアプリケーションに実装されており、楽しみのためだけに非営利で開発されています。 さらに、このような選択はYaZapomnilサイトで実行されます[2]。
文字の数のシーケンスや単語の最初の文字のシーケンスなどの奇妙なメトリックに関するさまざまなテキストが、テキストの量が増えるにつれて大きくなることは、私にとって非常に興味深いように思えました。 さらに、結果は非常に良好です。 テキストが増加するにつれて、フラグメントを選択する可能性が増加します。これにより、品質が向上する可能性があります。
現時点では、多数の美しいテキストが含まれるソースと、人には明らかであり、より多くの引用符を選択できる比較方法を考えています。
アイデアが面白そうだったら嬉しいです。