豊富なフレームワークと独自の標準ライブラリの完全性により、プログラムが非常に特定のハードウェア上で実行されるという考えは徐々に背景に消えつつあります。 ほとんどの場合、これは正当化されますが、時には人生が独自の調整を行います。
最新のプロセッサの大部分は、頻繁に使用されるデータを保存するためのキャッシュを備えています。 キャッシュメモリはブロック(キャッシュライン)に分割されます。 キャッシュコヒーレンスを実装するメカニズムは、コンピューターシステムのプロセッサコア間でキャッシュメモリの同期を提供します。
偽共有という用語は、キャッシュメモリの同じブロックを共有するプログラム内の異なるオブジェクトへのアクセスを意味します。 マルチスレッドアプリケーションでの偽共有は、異なるスレッドから変更可能な変数が1つのブロックに現れると、パフォーマンスの低下とキャッシュコヒーレンスメカニズムの負荷の増加につながります。 これがどのように起こるかについての詳細は、このトピックに関する記事で見つけることができます。
ツールキット
- jitコードを分解するためのhsdisプラグイン 。
- CPUカウンターのプロファイリングと取得のためのインテル®VTune™Amplifier XE 2013 。
例
マルチスレッドアプリケーション、スレッド、各反復で、一般配列のセルから以前の値を取得し、計算を実行して結果を追加します。
非表示のテキスト
public class SArray { // volatile jvm private static volatile long globalArray[] = new long[512]; public static class MThread implements Runnable { private int aPos; private long iterations; public MThread(long iterations, int aPos) { this.aPos = aPos; this.iterations = iterations; } @Override public void run() { for(long l = 0; l < iterations; ++l) { ++globalArray[aPos]; } System.out.printf("A:TID:%d, count: %d\n", Thread.currentThread().getId(), globalArray[aPos]); } } private static final int THREAD_COUNT = Runtime.getRuntime().availableProcessors(); private static final long ITERATIONS = 1870234052L; public static void main(String[] args) throws Throwable { Thread[] threads = new Thread[THREAD_COUNT]; long smillis = System.currentTimeMillis(); for(int i = 0; i < THREAD_COUNT; ++i) { threads[i] = new Thread(new MThread(ITERATIONS, i)); } for(Thread t: threads) { t.start(); } for(Thread t: threads) { t.join(); } System.out.printf("Total iterations on %d threads: %d, took %d ms\n", THREAD_COUNT, ITERATIONS, System.currentTimeMillis() - smillis); } }
jvmが不要な最適化を導入していないことを確認します。
java -XX:+UnlockDiagnosticVMOptions -XX:CompileCommand=print,SArray$MThread::run -XX:PrintAssemblyOptions=intel -cp target\falseshare-1.0-SNAPSHOT.jar SArray
非表示のテキスト
0x0000000002350540: mov r11d,DWORD PTR [r13+0xc] 0x0000000002350544: mov r10d,DWORD PTR [r8+0x70] ;*getfield aPos ; - SArray$MThread::run@15 (line 18) 0x0000000002350548: mov r9d,DWORD PTR [r12+r10*8+0xc] ; implicit exception: dispatches to 0x00000000023505dd 0x000000000235054d: cmp r11d,r9d 0x0000000002350550: jae 0x0000000002350599 ;*laload ; - SArray$MThread::run@19 (line 18) 0x0000000002350552: shl r10,0x3 ; >>>> ; 0x0000000002350556: inc QWORD PTR [r10+r11*8+0x10] ;*goto ; - SArray$MThread::run@27 (line 17) 0x000000000235055b: add rbx,0x1 ; OopMap{r8=Oop r13=Oop off=127} ;*goto ; - SArray$MThread::run@27 (line 17) 0x000000000235055f: test DWORD PTR [rip+0xfffffffffddefa9b],eax # 0x0000000000140000 ;*goto ; - SArray$MThread::run@27 (line 17) ; {poll} 0x0000000002350565: cmp rbx,QWORD PTR [r13+0x10] 0x0000000002350569: jl 0x0000000002350540 ;*ifge
globalArrayが揮発性でない場合、jvmは毎回メモリから読み取りません。
非表示のテキスト
0x00000000021e0592: add rbx,0x1 ;*ladd ; - SArray$MThread::run@25 (line 17) ; >>>> ; 1 0x00000000021e0596: add r8,0x1 ;*ladd ; - SArray$MThread::run@21 (line 18) 0x00000000021e059a: mov QWORD PTR [r11+rcx*8+0x10],r8 ; OopMap{r11=Oop r13=Oop off=127} ;*goto ; - SArray$MThread::run@27 (line 17) 0x00000000021e059f: test DWORD PTR [rip+0xfffffffffe24fa5b],eax # 0x0000000000430000 ;*goto ; - SArray$MThread::run@27 (line 17) ; {poll} 0x00000000021e05a5: cmp rbx,r10 0x00000000021e05a8: jl 0x00000000021e0592 ;*ifge
実際には、計算方法が重要な場合、そのような最適化は行われない場合があります。
この場合、volatileはオプティマイザーを混乱させるためだけに使用されます。 volatile long [] arrayという形式のレコードは、volatileのセマンティクスが要素ではなく配列へのポインターを指すことを意味します。
VTune Amplifierで新しいプロジェクトを作成します。
非表示のテキスト 
Generic Exploration分析を作成して起動します。 要約では次のことがわかります。
非表示のテキスト 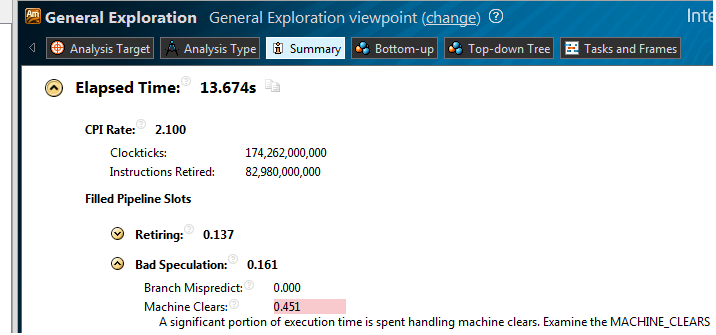
CPI-2.100、決済タスク1以下の通常。 ハードウェアの問題を表示します:
非表示のテキスト 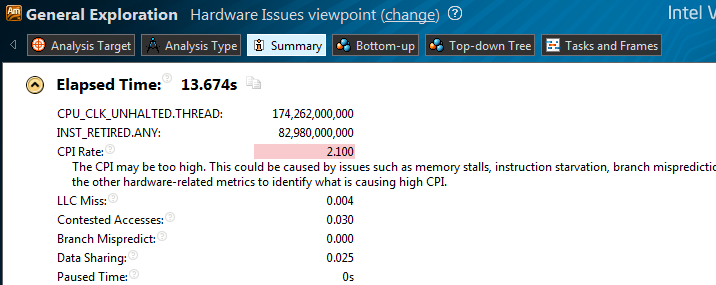
競合アクセスがあります。つまり、あるスレッドによって書き込まれたデータが別のスレッドによって読み取られ、スレッドが異なるコア/ CPUで実行されます。
つまり、globalArray配列のセルは1つのキャッシュラインに分類されます。
この状況を回避するために、メモリ内のセルをキャッシュラインの値で除算します。 Intel i5では、キャッシュラインサイズは64バイトです。 行を変更する
threads[i] = new Thread(new MThread(ITERATIONS, i));
に
threads[i] = new Thread(new MThread(ITERATIONS, (i + 1) * 8));
なぜ私は* 8ですか? 配列の場合、オブジェクトヘッダーの後の最初の要素は長さ(フィールド長)であるためです。 要素アクセス操作の場合、jvmはこのフィールドを読み取って、インデックスの有効性を確認できます。
Vtuneで再分析を実行します。
非表示のテキスト 
CPI-0.586、競合するアクセスはなくなりました、ランタイムはCPIに比例して13.7秒から4.5秒に変更されました。
テストはシングルプロセッサマシンで実行されました。マルチプロセッサ構成の場合、キャッシュメモリを同期するオーバーヘッドはさらに大きくなります。
当然、オブジェクトのフィールドにアクセスするときに同じ問題が発生する可能性があります。 ただし、hostpot jvmのオブジェクト(フィールドが1つ)の最小サイズは16バイトであるため、問題はそれほど一般的ではありません。 継承を使用したオブジェクトの誤った共有を回避する方法は、BlackHoleの実装のjmhソースで確認できます。 オプションの1つとして-すべてのフローに対してホールセールオブジェクトを作成せず、このプロセスを時間内に分散します。
テストは、Intel Core i5 3.3 GHzプロセッサ、64ビットJDK 1.7.0_21、Intel Vtune Amplifier XE 2013 Update 11(ビルド300544)評価ライセンス、Windows 7 64ビットを搭載したマシンで実行されました。
PS。 記事に記載されているパフォーマンスの数値をそのまま使用しないでください。 結果は、たとえばOSとjvmがプロセッサのコア間でスレッドをどのように分散するかなど、外部要因に大きく依存します。 ただし、高性能なものを作成する場合は、ターゲットプラットフォームのこのような機能を考慮する必要があります。