
はじめに
この記事は一連の記事の続きです: シングルトンパターンの使用[1] 、 シングルトンとオブジェクトの寿命[2] 、 依存関係の処理と設計パターンの生成[3] 、 マルチスレッドアプリケーションでのシングルトン実装[4] 。 次に、マルチスレッドについて説明します。 このトピックは膨大で多面的であるため、すべてを網羅することはできません。 ここでは、マルチスレッドについてまったく考えないようにするか、または非常に少ない量でそれについて考えることを可能にするいくつかの実用的なことに焦点を当てます。 より正確には、設計段階でのみ検討し、実装ではないと考えます。 つまり 頭痛のない正しい構成が自動的に呼び出されることを確認する方法についての質問が議論されます。 このアプローチにより、競合状態(競合状態、競合状態[5]を参照)およびデッドロック(デッドロック、 デッドロック[6]を参照)によって引き起こされる問題を大幅に減らすことができます。 この事実自体はかなりの価値があります。 また、ロックやアトミック操作を使用せずに、複数のスレッドから同時にオブジェクトにアクセスできるアプローチも検討されます!ほとんどの記事は特定のプリミティブセットのみに限定されており、使用は便利ですが、マルチスレッド環境で発生する一般的な問題を解決することはできません。 以下は、これらのタイプのアプローチで一般的に使用されるリストです。 同時に、読者はすでにそのようなアプローチに精通していると想定するので、これに焦点を合わせません。
使用するエンティティ:
ミューテックスインターフェイスの説明:
|
RAIIプリミティブ(例外に対して安全):
|
簡単な例としてのいじめのクラス:
|
例1.プリミティブアプローチ:Cスタイル
|
例2.高度なアプローチ:RAIIスタイル
|
例3.実際に理想的:ロックのカプセル化
|
不変量
奇妙なことに、オブジェクトの不変条件をチェックすることから、マルチスレッドの問題の議論を始めます。 それにもかかわらず、開発された不変式のメカニズムは将来使用されます。「不変式」の概念に精通していない人のために、このパラグラフは捧げられます。 残りは安全にスキップして実装に直接進むことができます。 したがって、OOPでは、奇妙なことに、オブジェクトを操作します。 各オブジェクトには独自の状態があり、非定数関数によって呼び出されると、状態が変わります。 したがって、原則として、各クラスには特定の不変条件があり、状態の変化ごとに満たす必要があります。 たとえば、オブジェクトが要素のカウンターである場合、プログラムが実行される任意の時点で、このカウンターの値が負であってはならないことは明らかです。 この場合、不変式はカウンターの負でない値です。 したがって、不変式の保存により、オブジェクトの状態が一貫していることがある程度保証されます。
クラスに不変式が保存されている場合は
true
を返し、不変式が違反されている場合は
false
を返す
isValid
メソッドがあることを想像してください。 次の「非負」カウンターを検討してください。
struct Counter { Counter() : count(0) {} bool isValid() const { return count >= 0; } int get() const { return count; } void set(int newCount) { count = newCount; } void inc() { ++ count; } void dec() { -- count; } private: int count; };
使用法:
Counter c; c.set(5); assert(c.isValid()); // true c.set(-3); assert(c.isValid()); // false assert
ここで、値が変更されるたびに
isValid
メソッドを呼び出さないように、不変式の検証を何らかの方法で自動化したいと思います。 これを行う明白な方法は、この呼び出しを
set
メソッドに含めることです。 ただし、多数の非定数クラスメソッドが存在する場合、このような各メソッド内にこのチェックを挿入する必要があります。 しかし、私はより少ない記述とより多くを得るために自動化を達成したいと思います。 それでは始めましょう。
ここでは、以前の一連の記事で開発されたツールを使用します: シングルトンパターンの使用[1] 、 シングルトンとオブジェクトの寿命[2] 、 依存関係の処理と設計パターンの生成[3] 、 マルチスレッドアプリケーションでのシングルトン実装[4] 。 以下では、参照のためにペアリングを行う実装を示します。
An.hpp
#ifndef AN_HPP #define AN_HPP #include <memory> #include <stdexcept> #include <string> // , . [1] #define PROTO_IFACE(D_iface, D_an) \ template<> void anFill<D_iface>(An<D_iface>& D_an) #define DECLARE_IMPL(D_iface) \ PROTO_IFACE(D_iface, a); #define BIND_TO_IMPL(D_iface, D_impl) \ PROTO_IFACE(D_iface, a) { a.create<D_impl>(); } #define BIND_TO_SELF(D_impl) \ BIND_TO_IMPL(D_impl, D_impl) // , DIP - dependency inversion principle template<typename T> struct An { template<typename U> friend struct An; An() {} template<typename U> explicit An(const An<U>& a) : data(a.data) {} template<typename U> explicit An(An<U>&& a) : data(std::move(a.data)) {} T* operator->() { return get0(); } const T* operator->() const { return get0(); } bool isEmpty() const { return !data; } void clear() { data.reset(); } void init() { if (!data) reinit(); } void reinit() { anFill(*this); } T& create() { return create<T>(); } template<typename U> U& create() { U* u = new U; data.reset(u); return *u; } private: // // // anFill, // // T T* get0() const { // const_cast<An*>(this)->init(); return data.get(); } std::shared_ptr<T> data; }; // , . [1] // // , // , // . . [3] template<typename T> void anFill(An<T>& a) { throw std::runtime_error(std::string("Cannot find implementation for interface: ") + typeid(T).name()); } #endif
一貫性を確認できるようにするために、次のようにオブジェクトへのアクセスを変更します(プライベートメソッド
get0
)。
template<typename T> struct An { // ... T* get0() const { const_cast<An*>(this)->init(); assert(data->isValid()); // assert return data.get(); } // ... };
すべて順調です。検証が進行中です。 しかし問題は、変更後ではなく、変更前に発生することです。 したがって、オブジェクトは一貫性のない状態になる可能性があり、次の呼び出しのみがそのジョブを実行します。
c->set(2); c->set(-2); // assert c->set(1); // , !
チェックは、変更前ではなく変更後に行うようにします。 これを行うには、必要な検証が行われるデストラクタでプロキシオブジェクトを使用します。
template<typename T> struct An { // ... struct Access { Access(T& ref_) : ref(ref_) {} ~Access() { assert(ref.isValid()); } T* operator->() { return &ref; } private: T& ref; }; // , ( , .. ): Access operator->() { return *get0(); } // ... };
使用法:
An<Counter> c; c->set(2); c->set(-2); // assert c->set(1);
必要でした。
スマートミューテックス
次に、マルチスレッドタスクに目を向けます。 mutexの新しい実装を作成し、スマートポインターとの類推によって「スマート」と呼びます。 巧妙なmutextのアイデアは、オブジェクトを操作するすべての「汚い」作業を引き受けることであり、私たちには最もおいしい部分があります。それを準備するには、「通常の」ミューテックスが必要です(スマートポインターのように、通常のポインターが必要です)。
// noncopyable struct Mutex { // void lock(); void unlock(); private: // ... };
ここで、以前に不変式をチェックする際に使用したプラクティスを改善します。 これを行うには、プロキシクラスデストラクタだけでなく、コンストラクタも使用します。
template<typename T> struct AnLock { // ... template<typename U> struct Access { // Access(const An& ref_) : ref(ref_) { ref.mutex->lock(); } // ~Access() { ref.mutex->unlock(); } U* operator->() const { return ref.get0(); } private: const An& ref; }; // Access<T> operator->() { return *this; } Access<const T> operator->() const { return *this; } // template<typename U> U& create() { U* u = new U; data.reset(u); mutex.reset(new Mutex); return *u; } private: // ... std::shared_ptr<T> data; std::shared_ptr<Mutex> mutex; };
使用法:
AnLock<Counter> c; c->set(2); // std::cout << "Extracted value: " << c->get() << std::endl;
定数リンクを使用している場合、値を変更するとコンパイルエラーが発生することに注意してください(
shared_ptr
直接使用するのではなく)。
const AnLock<Counter>& cc = c; cc->set(3); //
私たちが得たものを検討してください。
Counter
および
Mutex
のメソッドの画面出力を追加すると、値が変更されたときに次の画面出力が得られます。
ミューテックス::ロック カウンター::セット:2 ミューテックス::ロック解除
画面に表示するときのアクションのシーケンス:
ミューテックス::ロック カウンター::取得:2 抽出値:2 ミューテックス::ロック解除
利便性は明白です。ミューテックスを明示的に呼び出すのではなく、ミューテックスが存在しないかのようにオブジェクトを操作するだけで、内部で必要なすべてが発生します。
たとえば、
inc
2回呼び出してアトミックに実行する必要がある場合はどうすればよいでしょうか。 問題ありません! 最初に、便宜上、
AnLock
クラスに
typedef
をいくつか追加し
typedef
。
template<typename T> struct AnLock { // ... typedef Access<T> WAccess; // typedef Access<const T> RAccess; // // ... };
そして、次の構成を使用します。
{ AnLock<Counter>::WAccess a = c; a->inc(); a->inc(); }
これにより、次の結論が得られます。
ミューテックス::ロック カウンター::株式会社:1 カウンター::株式会社:2 ミューテックス::ロック解除
トランザクションのようなものですよね?
スマートRWミューテックス
そのため、今度は、読み取り/書き込みミューテックスと呼ばれる少し複雑な構造の実装を試みることができます( リーダー-ライターロック[7]を参照)。 使用の本質は非常に簡単です。複数のストリームからオブジェクトデータを読み取る機能を許可し、同時に読み取りと書き込みまたは書き込みと書き込みを同時に禁止する必要があります。このインターフェイスを備えた
RWMutex
実装がすでにあると仮定します。
// noncopyable struct RWMutex { // // void rlock(); void runlock(); // void wlock(); void wunlock(); private: // ... };
行う必要があるのは、実装をわずかに変更して、プロキシタイプ
RAccess
と
WAccess
が異なる関数を使用するようにすることだけであるように思われます。
template<typename T> struct AnRWLock { // ... // struct RAccess { RAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->rlock(); } ~RAccess() { ref.mutex->runlock(); } const T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; // struct WAccess { WAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->wlock(); } ~WAccess() { ref.mutex->wunlock(); } T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; WAccess operator->() { return *this; } RAccess operator->() const { return *this; } // ... // template<typename U> U& create() { U* u = new U; data.reset(u); mutex.reset(new RWMutex); return *u; } private: // ... std::shared_ptr<T> data; std::shared_ptr<RWMutex> mutex; };
使用法:
AnRWLock<Counter> c; c->set(2);
結果:
RWMutex :: wlock カウンター::セット:2 RWMutex :: wunlock
これまでのところ良い! しかし、次のコード:
std::cout << "Extracted value: " << c->get() << std::endl;
それは与える:
RWMutex :: wlock カウンター::取得:2 抽出値:2 RWMutex :: wunlock
一部の人にとっては、これは驚くことではありませんが、残りについては、なぜ期待どおりに機能しないのかを説明します。 結局、定数メソッドを使用したため、理論的には定数メソッド
operator->
を使用する必要がありました。 しかし、コンパイラはそうは思いません。 これは、操作が順番に適用されるという事実によるものです。最初に、操作
->
が非定数オブジェクトに適用され、次に定数メソッド
Counter::get
が呼び出されますが、列車は残ります。 非定数
operator->
はすでに呼び出されています。
簡単な解決策として、オブジェクトにアクセスする前に定数にキャストするオプションを提案できます。
const AnRWLock<Counter>& cc = c; std::cout << "Extracted value: " << cc->get() << std::endl;
結果:
RWMutex :: rlock カウンター::取得:2 抽出値:2 RWMutex ::ランロック
しかし、このソリューションは、控えめに言っても、あまり魅力的ではありません。 単純かつ簡潔に記述し、定数メソッドを呼び出すたびにかさばる構造を使用したくない。
この問題を解決するために、新しい演算子、長い矢印
--->
を導入し
--->
。これはオブジェクトに書き込みます。 非定数メソッドにアクセスし、通常の(短い)矢印
->
をそのままにしておきます。 読み取りに短い矢印を使用し、書き込みに長い矢印を使用する理由は次のとおりです。
- ビジュアル どの操作が使用されているかをすぐに確認できます。
- セマンティック 。 読書は、オブジェクトの一種の表面的な使用です:触れられ、解放されます。 記録は、内部のより深い操作、いわば変化です。したがって、矢印はより長くなります。
- 実用的 。 通常のミューテックスをRWミューテックスに置き換える場合、これらの場所で短い矢印を長い矢印に置き換えるだけでコンパイルエラーを修正する必要があり、すべてが最適な方法で機能します。
ここで、おそらく、熱心な読者は質問をしました:記事の著者と同じ雑草をどこで手に入れるか? やっぱり

実装を見てみましょう:
// , : WAccess operator--(int) { return *this; } // , : RAccess operator->() const { return *this; }
使用法:
AnRWLock<Counter> c; // : c->set(2) c--->set(2);
アクションのシーケンス:
RWMutex :: wlock カウンター::セット:2 RWMutex :: wunlock
長い矢印を使用することを除いて、すべてが以前と同じです。 さらに調査します。
std::cout << "Extracted value: " << c->get() << std::endl;
RWMutex :: rlock カウンター::取得:2 抽出値:2 RWMutex ::ランロック
私の意見では、書き込み操作に長い矢印を使用することは正当化されます。それは私たちの問題を非常にエレガントな方法で解決します。
読者がその仕組みをよく理解していない場合
読者がこれがどのように機能するかをよく理解していない場合は、「長い」矢印をヒントとして使用するための次の同等のコードを提供します。
(c--)->set(2);
コピーオンライト
次に、次の興味深く有用なイディオム、 コピーオンライト ( COW )、またはコピーオンライト[8]を考えてください 。 名前が示すように、主な考え方は、オブジェクトのデータを変更する直前に、新しいメモリ位置へのコピーが最初に発生し、次にデータが新しいアドレスに変更されるということです。COWアプローチはマルチスレッドに直接関連していませんが、それでもこのアプローチを他のアプローチと組み合わせて使用すると、使いやすさが大幅に向上し、多くのかけがえのない要素が追加されます。 そのため、 COWの実装を以下に示します。 さらに、開発されたトリックは、このイディオムの実装に簡単かつ自然に移行されます。
そのため、RWミューテックスと同様に、読み取り操作と書き込み操作を区別する必要があります。 読み取り時には特別なことは発生しませんが、書き込み時には、オブジェクトに複数の所有者がいる場合、まずこのオブジェクトをコピーする必要があります。
template<typename T> struct AnCow { // ... // T* operator--(int) { return getW0(); } // const T* operator->() const { return getR0(); } // ( !) void clone() { data.reset(new T(*data)); } // ... private: T* getR0() const { const_cast<An*>(this)->init(); return data.get(); } T* getW0() { init(); // “” if (!data.unique()) clone(); return data.get(); }
ポリモーフィックオブジェクトの使用はここでは考慮されない(つまり、テンプレートクラス
T
継承を作成しない)ことに注意する価値があります。 これはこの記事の範囲を超えています。 次回の記事では、この問題の詳細な解決策を説明しますが、実装は非常にまれです。
使用に移りましょう:
| コード | コンソール出力 |
|---|---|
| カウンター::セット:2 |
| カウンター::取得:2 抽出値:2 |
| カウンター::取得:2 抽出値:2 |
| カウンターコピーアクター:2 カウンター::株式会社:3 |
| カウンター:: dec:1 |
2
です。 次に、値は新しい変数に割り当てられますが、オブジェクトデータは同じように使用されます。 値
d->get()
出力するとき、同じオブジェクトが使用されます。
次に、
d--->inc()
が呼び出されると、最も興味深いことが起こります。最初にオブジェクトがコピーされ、次に結果の値が3に増加します。 次の
c--->dec()
呼び出しはコピーされません。 所有者は1人になり、オブジェクトの2つの異なるコピーがあります。 この例は、 COWの仕事を明確に示していると思います。
メモリ内のキー値ストレージ
最後に、開発された手法を使用してマルチスレッド環境で作業する場合、メモリ内のキー値ストレージの実装のいくつかのバリエーションを検討します。リポジトリには次の実装を使用します。
template<typename T_key, typename T_value> struct KeyValueStorageImpl { // void set(T_key key, T_value value) { storage.emplace(std::move(key), std::move(value)); } // T_value get(const T_key& key) const { return storage.at(key); } // void del(const T_key& key) { storage.erase(key); } private: std::unordered_map<T_key, T_value> storage; };
ストレージをシングルトンにバインドして、さらに操作を簡素化します( シングルトンパターンの使用[1]を参照)。
template<typename T_key, typename T_value> void anFill(AnRWLock<KeyValueStorageImpl<T_key, T_value>>& D_an) { D_an = anSingleRWLock<KeyValueStorageImpl<T_key, T_value>>(); }
したがって、
AnRWLock<KeyValueStorageImpl<T,V>>
インスタンスを作成すると、シングルトンから抽出されたオブジェクトが「注がれ」ます。
AnRWLock<KeyValueStorageImpl<T,V>>
は常に単一のインスタンスを指します。
参考のために、使用するインフラストラクチャを示します。
AnRWLock.hpp
#ifndef AN_RWLOCK_HPP #define AN_RWLOCK_HPP #include <memory> #include <stdexcept> #include <string> #include "Mutex.hpp" // fill #define PROTO_IFACE_RWLOCK(D_iface, D_an) \ template<> void anFill<D_iface>(AnRWLock<D_iface>& D_an) #define DECLARE_IMPL_RWLOCK(D_iface) \ PROTO_IFACE_RWLOCK(D_iface, a); #define BIND_TO_IMPL_RWLOCK(D_iface, D_impl) \ PROTO_IFACE_RWLOCK(D_iface, a) { a.create<D_impl>(); } #define BIND_TO_SELF_RWLOCK(D_impl) \ BIND_TO_IMPL_RWLOCK(D_impl, D_impl) #define BIND_TO_IMPL_SINGLE_RWLOCK(D_iface, D_impl) \ PROTO_IFACE_RWLOCK(D_iface, a) { a = anSingleRWLock<D_impl>(); } #define BIND_TO_SELF_SINGLE_RWLOCK(D_impl) \ BIND_TO_IMPL_SINGLE_RWLOCK(D_impl, D_impl) template<typename T> struct AnRWLock { template<typename U> friend struct AnRWLock; struct RAccess { RAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->rlock(); } ~RAccess() { ref.mutex->runlock(); } const T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; struct WAccess { WAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->wlock(); } ~WAccess() { ref.mutex->wunlock(); } T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; AnRWLock() {} template<typename U> explicit AnRWLock(const AnRWLock<U>& a) : data(a.data) {} template<typename U> explicit AnRWLock(AnRWLock<U>&& a) : data(std::move(a.data)) {} WAccess operator--(int) { return *this; } RAccess operator->() const { return *this; } bool isEmpty() const { return !data; } void clear() { data.reset(); } void init() { if (!data) reinit(); } void reinit() { anFill(*this); } T& create() { return create<T>(); } template<typename U> U& create() { U* u = new U; data.reset(u); mutex.reset(new RWMutex); return *u; } private: T* get0() const { const_cast<AnRWLock*>(this)->init(); return data.get(); } std::shared_ptr<T> data; std::shared_ptr<RWMutex> mutex; }; template<typename T> void anFill(AnRWLock<T>& a) { throw std::runtime_error(std::string("Cannot find implementation for interface: ") + typeid(T).name()); } template<typename T> struct AnRWLockAutoCreate : AnRWLock<T> { AnRWLockAutoCreate() { this->create(); } }; template<typename T> AnRWLock<T> anSingleRWLock() { return single<AnRWLockAutoCreate<T>>(); } #endif
AnCow.hpp
#ifndef AN_COW_HPP #define AN_COW_HPP #include <memory> #include <stdexcept> #include <string> // fill #define PROTO_IFACE_COW(D_iface, D_an) \ template<> void anFill<D_iface>(AnCow<D_iface>& D_an) #define DECLARE_IMPL_COW(D_iface) \ PROTO_IFACE_COW(D_iface, a); #define BIND_TO_IMPL_COW(D_iface, D_impl) \ PROTO_IFACE_COW(D_iface, a) { a.create<D_impl>(); } #define BIND_TO_SELF_COW(D_impl) \ BIND_TO_IMPL_COW(D_impl, D_impl) #define BIND_TO_IMPL_SINGLE_COW(D_iface, D_impl) \ PROTO_IFACE_COW(D_iface, a) { a = anSingleCow<D_impl>(); } #define BIND_TO_SELF_SINGLE_COW(D_impl) \ BIND_TO_IMPL_SINGLE_COW(D_impl, D_impl) template<typename T> struct AnCow { template<typename U> friend struct AnCow; AnCow() {} template<typename U> explicit AnCow(const AnCow<U>& a) : data(a.data) {} template<typename U> explicit AnCow(AnCow<U>&& a) : data(std::move(a.data)) {} T* operator--(int) { return getW0(); } const T* operator->() const { return getR0(); } bool isEmpty() const { return !data; } void clear() { data.reset(); } void init() { if (!data) reinit(); } void reinit() { anFill(*this); } T& create() { return create<T>(); } template<typename U> U& create() { U* u = new U; data.reset(u); return *u; } // TODO: update clone functionality on creating derived instances void clone() { data.reset(new T(*data)); } private: T* getR0() const { const_cast<AnCow*>(this)->init(); return data.get(); } T* getW0() { init(); if (!data.unique()) clone(); return data.get(); } std::shared_ptr<T> data; }; template<typename T> void anFill(AnCow<T>& a) { throw std::runtime_error(std::string("Cannot find implementation for interface: ") + typeid(T).name()); } template<typename T> struct AnCowAutoCreate : AnCow<T> { AnCowAutoCreate() { this->create(); } }; template<typename T> AnCow<T> anSingleCow() { return single<AnCowAutoCreate<T>>(); } #endif
次に、単純なものから複雑なものまで、このリポジトリを使用するさまざまな方法を検討します。
例1.最も単純な使用。
追加の飾りなしでストレージを直接使用します。 // template<typename T_key, typename T_value> struct KeyValueStorage : AnRWLock<KeyValueStorageImpl<T_key, T_value>> { typedef T_value ValueType; };
使用例:
| コード | コンソール出力 |
|---|---|
| RWMutex :: wlock Key-Value:キーの挿入:Peter RWMutex :: wunlock |
| RWMutex :: wlock Key-Value:キーを挿入:Nick RWMutex :: wunlock |
| RWMutex :: rlock Key-Value:キーの抽出:Peter ピーター年齢:28 RWMutex ::ランロック |
kv
オブジェクトを作成します(
anFill
関数を参照)。 次に、PeterとNickが追加され、Peterの年齢が表示されます。
出力から、書き込み時に書き込みロックが自動的に取得され、読み取り時に読み取りロックが取得されることが明らかだと思います。
例2.ネストされたRWミューテックス。
もう少し複雑な例を考えてみましょう。名前付きカウンターを取得Counter
し、複数のスレッドから使用したいとします。問題ありません:
// , AnRWLock template<typename T_key, typename T_value> struct KeyValueStorageRW : KeyValueStorage<T_key, AnRWLock<T_value>> { }; // typedef KeyValueStorageRW<std::string, Counter> KVRWType;
使用例:
| コード | コンソール出力 |
|---|---|
| RWMutex :: wlock Key-Value:キーの挿入:ユーザー RWMutex :: wunlock |
| RWMutex :: wlock Key-Value:キーの挿入:セッション RWMutex :: wunlock |
| RWMutex :: rlock Key-Value:キーの抽出:ユーザー RWMutex :: wlock カウンター::株式会社:1 RWMutex :: wunlock RWMutex ::ランロック |
| RWMutex :: rlock Key-Value:キーの抽出:セッション RWMutex :: wlock カウンター::株式会社:1 RWMutex :: wunlock RWMutex ::ランロック |
| RWMutex :: rlock Key-Value:キーの抽出:セッション RWMutex :: wlock カウンター:: dec:0 RWMutex :: wunlock RWMutex ::ランロック |
例3.アクセスの最適化。
次の記事でいくつかの最適化についてお話したいと思いますが、私はここで、非常に重要な最適化について説明します。以下は、比較のためのさまざまな使用例です。
オプション1:通常
| コード | コンソール出力 |
|---|---|
| RWMutex :: rlock Key-Value:キーの抽出:ユーザー RWMutex :: wlock カウンター::株式会社:2 RWMutex :: wunlock RWMutex ::ランロック |
オプション2:最適
| コード | コンソール出力 |
|---|---|
| RWMutex :: rlock Key-Value:キーの抽出:ユーザー RWMutex ::ランロック |
| RWMutex :: wlock カウンター::株式会社:3 RWMutex :: wunlock |
Counter
、キー値ストレージを制御する最初のミューテックスをリリースした後にのみ取得されることを示しています。この実装はミューテックスのより最適な使用を提供しますが、結果としてより長いレコードを取得します。ネストされたミューテックスを使用する場合は、この最適化に留意する必要があります。
例4.アトミックな変更のサポート。
たとえば、「users」などのカウンターの1つをアトミックに100増やす必要があるとします。もちろん、このためにオペレーションを100回呼び出すことができますinc()
。または、これを行うことができます。
| コード | コンソール出力 |
|---|---|
| RWMutex :: rlock Key-Value:キーの抽出:ユーザー RWMutex ::ランロック |
| RWMutex :: wlock カウンター::取得:4 カウンター::セット:104 RWMutex :: wunlock |
WAccess
さらに使用する場合、すべての操作は通常の「短い」矢印で進むことに注意してください。すでに取得したオブジェクトへの書き込みアクセス。また、操作という事実に注意を払う
get
と
set
、私たちが達成したかったものです同じミューテックス、下にあります。これは、オブジェクトを操作するときにトランザクションを開くように見えるという事実に非常に似ています。
上記の最適化と同じトリックを使用して、カウンターに直接アクセスできます。
オプション1:通常
| コード | コンソール出力 |
|---|---|
| RWMutex :: rlock Key-Value:キーの抽出:ユーザー RWMutex :: wlock カウンター::株式会社:4 RWMutex :: wunlock RWMutex ::ランロック |
| RWMutex :: rlock Key-Value:キーの抽出:セッション RWMutex :: wlock カウンター:: dec:-1 RWMutex :: wunlock RWMutex ::ランロック |
オプション2:最適
| コード | コンソール出力 |
|---|---|
| RWMutex :: rlock Key-Value:キーの抽出:ユーザー Key-Value:キーの抽出:セッション RWMutex ::ランロック |
| RWMutex :: wlock カウンター::株式会社:5 RWMutex :: wunlock |
| RWMutex :: wlock カウンター:: dec:-2 RWMutex :: wunlock |
例5.牛。
次の情報を持つ従業員がいるとします。 struct User { std::string name; int age; double salary; // ... };
私たちのタスク:たとえば、バランスシートを計算するために、選択したユーザーに対してさまざまな操作を実行します。操作が長いため、状況は複雑です。同時に、計算時に従業員に関する情報を変更することは受け入れられません。異なる指標は一貫している必要があり、データが変更された場合、バランスが収束しない可能性があります。同時に、長時間の操作の終了を待たずに、操作中に従業員に関する情報を変更したいと思います。計算を実装するには、ある時点のデータのスナップショットを取得する必要があります。もちろん、データは無関係になりますが、バランスを保つためには、一貫した結果を得ることがより重要です。
これをCOWを使用して実装する方法を見てみましょう。準備段階:
インスタンスの作成時にCOWを使用するUser
|
オブジェクトを格納できる新しいクラスを宣言します AnCow
|
リポジトリの宣言:int
-ユーザーID、 User
-ユーザー |
Peterユーザー情報の追加
|
Georgeユーザー情報の追加
|
従業員の年齢情報を変更する
|
適切なユーザーを獲得する
|
必要なパラメーターの計算。すべてのデータは一貫性があり、操作が終了するまで変更されません。
|
一般的に、計算する前にすべての要素をコピーすることはもちろん可能です。ただし、十分な量の情報がある場合、これはかなり長い操作になります。したがって、示されたアプローチでは、データのコピーが本当に必要になるまで延期されます。計算と変更で同時に使用する場合のみ。
分析と合成
例の分析を以下に示します。最も興味深いのは、まず、COWの最後の例です。予期しない驚きがそこに隠されています。詳細詳細
最後の例の一連の操作を検討してください。以下は、コンテナから値を取得するための一般的な概要です。
ここで
Data
、これは
User
上記の例にあり、
shared_ptr<Data>
これはオブジェクトのコンテンツです
AnCow
。操作のシーケンス:
| N | | 説明 |
|---|---|---|
| 1 | ロック | 呼び出されたときに自動的に行われるストレージロック operator->
|
| 2 | コピー | コピーshared_ptr<Data>
、つまり 実際、カウンター( use_count
および weak_count
オブジェクト内 shared_ptr<Data>
)の単純な増加があります。 |
| 3 | ロック解除 | 一時オブジェクトのデストラクタストレージのロック解除 |
オブジェクトにデータを書き込むとどうなりますか。私たちは見ます:
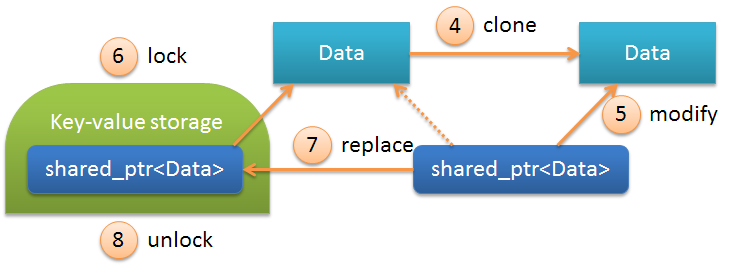
この場合の操作の順序は次のとおりです。
| N | | 説明 |
|---|---|---|
| 4 | クローン | オブジェクトのクローン作成、オブジェクトはコピーコンストラクタと呼ばれてData
います、すべてのフィールドを新しいメモリ領域にコピーします。この操作の後、彼 shared_ptr
は新しく作成されたオブジェクトを見始めます。 |
| 5 | 修正する | . , .. . |
| 6 | ロック | . |
| 7 | replace | shared_ptr<Data>
, 5- . |
| 8 | unlock | . |
int
。大きな違いは、COWでは、複数のスレッドの同じメモリ領域から同時にデータを使用できることです。
上記の操作のほとんどは自動的に行われることに注意してください。すべての操作を明示的に実行する必要はありません。
牛の最適化
上記のように、COWオブジェクトを変更すると、そのすべてのフィールドがコピーされます。これは、少量のデータでは大きな問題ではありません。しかし、クラスに多数のパラメーターがある場合はどうでしょうか?この場合、マルチレベルCOWオブジェクトを使用できます。たとえば、次のクラスを入力できますUserInfo
。
struct UserInfo { AnCow<AccountingInfo> accounting; AnCow<CommonInfo> common; AnCow<WorkInfo> work; }; struct AccountingInfo { AnCow<IncomingInfo> incoming; AnCow<OutcomingInfo> outcoming; AnCow<BalanceInfo> balance; }; struct CommonInfo { // .. }; // ..
各レベルでCOWオブジェクトを入力することにより、コピーの数を大幅に削減できます。同時に、コピー操作自体は、カウンターのアトミックな増加のみで構成されます。また、コピーコンストラクタを使用して変更オブジェクト自体のみがコピーされます。各レベルのオブジェクトの数が3 mに等しい場合、コピーの最小数が達成されることが簡単に示されます。
一般化されたスキーム
ネスティングを考慮して、COWの操作をより詳細に検討したので、考慮されたイディオムの使用の一般化に安全に進むことができます。しかし、このために、最初に例で使用されるスキームを検討します。最初の例では、ネストされた
AnRWLock
オブジェクトが使用され
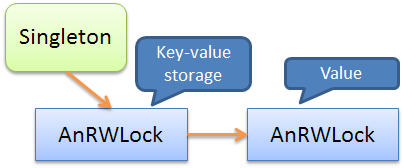
ました。指定された例のKey-Valueストレージはシングルトンに配置され、「スマート」ミューテックスでラップされています。値もスマートミューテックスでラップされました。
次の図は、COWを使用した例を示して
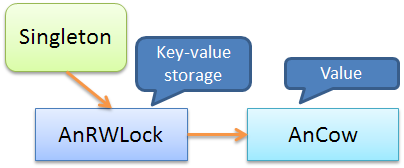
います。ここでは
AnCow
、COWセマンティクスを実装するために、値がオブジェクトにラップされています。
したがって、一般化スキームは以下のように書くことができる
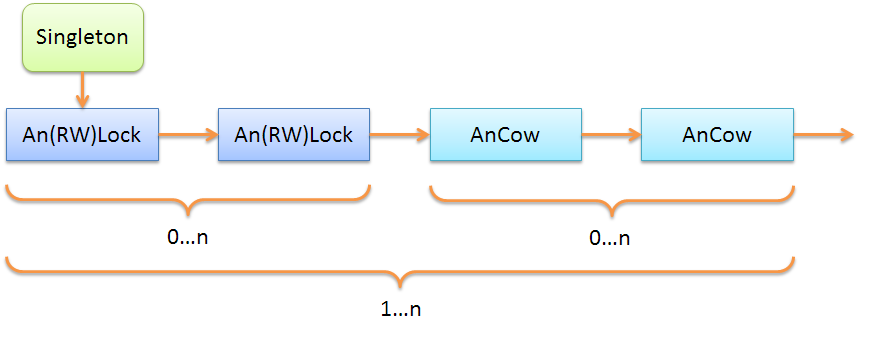
それは、オブジェクトことは明らかである
AnLock
と
An(RW)Lock
交換可能:どちらか一方を使用できます。また、チェーンが華やか以下の例のように、数回繰り返すことができます。
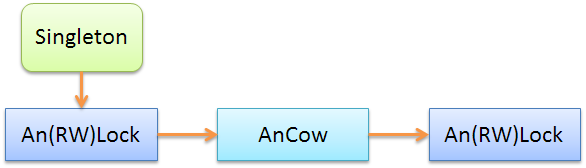
しかし、オブジェクトの意味論ということを忘れてはならない
An(RW)Lock
とは
AnCow
大きく異なります。
| 物件 | スマートミューテックス | 牛 |
|---|---|---|
| オブジェクトフィールドへのアクセス | 読み取り/書き込み中はロックされています | ブロックされていません |
| コンテナ内のオブジェクトを変更する | インプレース変更 | 変更後、新しい値をコンテナに戻します |
結論
そのため、この記事では、マルチスレッドアプリケーションの作成効率を向上させるいくつかのイディオムについて検討しました。次の利点は注目に値します。- シンプルさ。マルチスレッドプリミティブを明示的に使用する必要はなく、すべてが自動的に行われます。
- . . ( ) .
- . , (race condition) (deadlock). . (fine-grained) , .
このような普遍的なアプローチが可能になったのは、
An
-classes の実装において、保存されたオブジェクトの使用を完全に制御できるという事実のためです。したがって、必要な機能を追加して、アクセス境界で必要なメソッドを自動的に呼び出すことが可能になります。このアプローチは、次の記事で大幅に深化および拡張されます。
与えられた素材では、多態的なオブジェクトの使用は考慮されていませんでした。特に、実装
AnCow
は同じテンプレートクラスでのみ機能します。宣言された型のコピーコンストラクターは常に呼び出され
T
ます。次の記事では、より一般的なケースの実装について説明します。また、オブジェクトの統一とその使用方法があり、さまざまな最適化、マルチスレッドリンクなどについて説明しました。
文学
[1] Habrahabr:シングルトンパターンの使用[2] Habrahabr:シングルトンとオブジェクトライフタイム
[3] Habrahabr:依存関係の反転とデザインパターンの生成
[4] Habrahabr:マルチスレッドアプリケーションでのシングルトンの実装
[5] Wikipedia: 競合状態
[6] Wikipedia :相互ロック
[7] ウィキペディア:リーダー–ライターロック
[8] ウィキペディア:書き込み中のコピー
[9] Habrahabr:マルチスレッド、一般データおよびミューテックス
[10] Habrahabr:クロスプラットフォームマルチスレッドアプリケーション
[11] Habrahabr:ストリーム、ロック、 C ++ 11の条件変数[パート2]
[12] Habrahabr:C ++ 11のストリーム、ロック、および条件変数[パート1]
[13] Habrahabr:ミューテックスのデッドロックを防ぐための2つの簡単なルール
[14] DrDobbs:同期値で正しいMutexの使用を強制する
PSコピー数に関する問題の解決策
,
, —
, —
.
,
.
.
(
). つまり
, ..
— const. ,
, 3.
n
, —
k
, —
a
.
a = n^k
,
k = ln a/ln n
.
ln
k = a/n
.
= n*k
(
n
). つまり
= n*ln a/ln n
n/ln n
, ..
a
— const. ,
n = e
, 3.
そして最後に-調査。議題には2つの質問があります。