この記事は、Highload ++ 2012での私のレポートに基づいており、便利で非常に効果的なオープンソースフレームワークの簡単な紹介を目的としています。これは、NETMAPと呼ばれるHEAD / STABLE FreeBSDに含まれ、 * nixオペレーティングシステム。
Netmapは、ネットワークカードバッファーのメモリへのマッピング、I / Oバッチ処理、ネットワークカードのハードウェアバッファーに対応するリング送信および受信メモリバッファーの使用など、よく知られたパフォーマンス向上技術を使用します。 (10Gbit / sの理論上の最大値に対応します)。
この記事には、NETMAP作者の出版物の主要な断片であるLuigi Rizzoが含まれており、OSカーネルとネットワークカードを操作する際の重要な機能をカプセル化するnetmapフレームワークの内部実装のアーキテクチャと主要な機能について説明し、ユーザーランドにシンプルで理解可能なAPIを提供します。
猫の下では、14Mppsの速度でパケットを処理することに関連するアプリケーションを開発するためのフレームワークを使用する基本的なプリミティブが考慮され、L3レベルを担当するDDOS保護システムのコンポーネントを開発するときにネットマップフレームワークを使用する実際の経験が考慮されます。 別に、1 / 10Gbit / sチャネル、1つ/複数のプロセッサコア、大小のパケット、OS FreeBSD / Linuxスタックとのパフォーマンス比較のネットマップの比較パフォーマンス特性が別々に考慮されます。
1.はじめに
最新の汎用オペレーティングシステムは、ネットワーク監視プログラム、トラフィック生成、ソフトウェアスイッチ、ルーター、ファイアウォール、および攻撃認識システムで低レベルでパケットを処理するための豊富で柔軟な機能を提供します。 現在、これらのプログラムのほとんどを開発するために、rawソケット、Berkley Packet Filter(BPF)、AF_PACKETインターフェイスなどのソフトウェアインターフェイスが使用されています。 どうやら、これらのアプリケーションに必要な高いパケット処理速度は、上記のメカニズムの開発における主な目標ではありませんでした。 実装のそれぞれに大きなオーバーヘッドがあります(以降、オーバーヘッドと呼びます)。
同時に、伝送媒体、ネットワークカード、およびネットワークデバイスのスループットが大幅に向上しているため、ワイヤ速度での処理を可能にする低レベルのパケット処理用のインターフェイスが必要です。 毎秒数百万パケット。 パフォーマンスを向上させるために、一部のシステムはオペレーティングシステムのカーネルで直接動作するか、TCP / IPスタックとネットワークカードドライバーをバイパスしてネットワークカード構造(以降NIC)に直接アクセスします。 これらのシステムの有効性は、NICデータ構造への直接アクセスを提供するアイロンネットワークカードの特定の機能によるものです。
NETMAPフレームワークは、NICダイレクトアクセスソリューションに実装されたアイデアをうまく組み合わせて拡張します。 NETMAPは、生産性の劇的な向上に加えて、高性能のパケット処理のためにユーザーランドのハードウェアに依存しないインターフェースを提供します。 パケット処理の速度を評価できるように、次の1つのメトリックを示します。伝送媒体(ケーブル)からユーザースペースへのパケットの送信は、70 CPUサイクル未満です。 言い換えると、900 MHzの周波数を持つプロセッサの1つのコアのみでNETMAPを使用すると、1秒あたり1,488万パケット(Mpps)の高速転送を実行できます。これは、10Gbit / sチャネルのイーサネットフレームの最大伝送速度に相当します。
NETMAPのもう1つの重要な機能は、NICレジスタとデータ構造にアクセスするためのデバイスに依存しないインターフェイスを提供することです。 これらの構造およびカーネルメモリの重要な領域は、ユーザープログラムからアクセスできません。これにより、信頼性が向上します。 ユーザー空間から、メモリ領域に無効なポインタを挿入して、OSカーネルでクラッシュを引き起こすことは困難です。 同時に、NETMAPはゼロコピーパケット転送を可能にする非常に効率的なデータモデルを使用します。 メモリをコピーする必要のないパケット転送。これにより、驚異的なパフォーマンスが実現します。
この記事では、NETMAPが提供するアーキテクチャと機能、およびNETMAPで通常のハードウェアで取得できるパフォーマンスインジケーターに焦点を当てています。
2.最新のOSのTCP / IPスタック
記事のこの部分は、ソフトウェアスイッチ、ルーター、ファイアウォール、トラフィックアナライザー、攻撃認識システム、トラフィックジェネレーターなどのアプリケーションを開発する開発者にとって特に興味深いものになります。 汎用オペレーティングシステムは、原則として、未加工のパケットに高速でアクセスするための効果的なメカニズムを提供しません。 記事のこのセクションでは、OSのTCP / IPスタックの分析に集中し、オーバーヘッドの発生源を検討し、OSスタックを通過するさまざまな段階でパケットを処理するコストを理解します。
2.1。 NICデータの構造と操作
ネットワークアダプター(NIC)は、図1に示すように、メモリバッファー記述子のリングキューを使用して、着信パケットと発信パケットを処理します。

「米1号。 NICデータ構造とOSデータ構造との関係»
リングキューの各スロットには、バッファの長さと物理アドレスが含まれています。 CPU NICレジスタで使用可能な(アドレス指定可能な)には、パケットを送受信するためのキューに関する情報が含まれています。
パケットがネットワークカードに到着すると、現在のメモリバッファに配置され、サイズとステータスがスロットに記録され、処理する新しい着信データがあるという情報が対応するNICレジスタに記録されます。 ネットワークカードは、新しいデータが到着するとCPUに通知するために割り込みを開始します。
パケットがネットワークに送信される場合、NICは、OSが現在のバッファーを満たしていると想定し、送信データのサイズに関する情報をスロットに配置し、送信するスロットの数を対応するNICレジスタに書き込みます。これにより、ネットワークへのパケットの送信が開始されます。
パケットの送受信が高速の場合、多数の割り込みが発生すると、有用な作業を実行できなくなる可能性があります(「ライブロックの受信」)。 これらの問題を解決するために、OSはポーリングまたは割り込みスロットルメカニズムを使用します。 一部の高性能NICは、パケットの送受信に複数のキューを使用します。これにより、プロセッサの負荷を複数のコアに分散したり、ネットワークカードを複数のデバイスに分割して、そのようなネットワークカードで動作する仮想システムで使用したりできます。
2.2。 ユーザーのカーネルとAPI
OSはNICデータ構造をメモリバッファからキューにコピーします。これは各特定のOSに固有です。 FreeBSDの場合、これらはmbufであり、同等のものはsk_buffsとNdisPacketsです。 コアでは、これらのメモリバッファーは、各パケットに関する大量のメタデータを含むコンテナーです:サイズ、パケットの到着元/到着元のインターフェイス、NICおよび/またはOSのメモリバッファーデータの処理順序を決定するさまざまな属性とフラグ。
NICドライバーとオペレーティングシステムのTCP / IPスタック(以下、ホストスタックと呼びます)は、原則として、パケットを任意の数のフラグメントに分割できると想定しているため、ドライバーとホストスタックの両方がパケットのフラグメンテーションを処理する準備ができている必要があります。 ユーザースペースにエクスポートされた対応するAPIは、さまざまなサブシステムが遅延処理のためにパッケージを残すことができることを示唆しているため、メモリバッファーとメタデータは、呼び出し処理中に参照によって単に渡すことはできませんが、参照カウントによってコピーまたは処理する必要があります。 これはすべて、柔軟性と使いやすさの高いオーバーヘッドによる支払いです。
上記のAPIの設計はかなり前に開発されたものであり、今日のシステムでは今日では高すぎます。 メモリの割り当て、管理、およびバッファチェーンの通過のコストは、多くの場合、パケットで送信される有用なデータへの線形依存を超えています。
ユーザープログラムでのrawパッケージの入力/出力の標準APIは、OSカーネルとユーザー空間間でデータとメタデータをコピーするためのメモリ割り当てと、各パッケージ(場合によっては一連のパッケージ)の1つのシステムコールを少なくとも必要とします。
sendto()関数を使用してユーザーレベルからUDPパケットを送信するときにOS FreeBSDで発生するオーバーヘッドを考慮してください。 このユーザー空間の例では、プログラムはUDPパケットをループで送信します。 表2は、ユーザー空間およびさまざまなカーネル機能でパッケージの処理に費やされた平均時間を示しています。 Timeフィールドには、パケットを処理する平均時間(ナノ秒)が含まれ、値は関数が戻るときに記録されます。 デルタフィールドは、システムコール実行チェーン内の次の関数の開始までの経過時間を示します。 たとえば、8ナノ秒はユーザー空間のコンテキストで実行され、96ナノ秒はOSカーネルのコンテキストに入ります。
テストでは、OS FreeBSDで動作する次のマクロ定義を使用します。
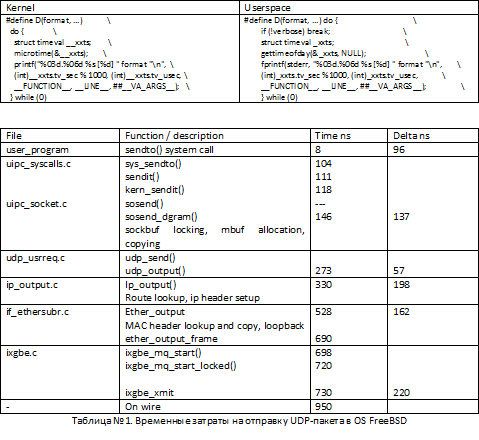
テストは、OS FreeBSD HEAD 64bit、i7-870 2.93GHz(TurboBoost)、Intel 10Gbit NIC、ixgbeドライバーを実行しているコンピューターで実行されました。 値は、数十の5秒テストで平均されます。
表1からわかるように、OSスタックのすべてのレベルのパケット処理で非常に長い時間を消費するいくつかの機能があります。 TCP、RAW_SOCKET、BPFなどのネットワーク入力/水用のAPIは、いくつかの非常に高価なレベルでパケットを送信することを強制されます。 この標準APIを使用すると、mbufのメモリ割り当てとコピーメカニズムをバイパスし、正しいルートを確認し、TCP / UDP / IP / MACヘッダーを準備および構築し、この処理チェーンの最後に、mbuf構造とメタデータを送信用にNIC形式に変換する方法はありませんネットワークへのパケット。 たとえば、ローカルの最適化の場合でも、ルートとヘッダーを最初から構築する代わりにキャッシュしても、10 Gbit / sインターフェイスでパケットを処理するのに必要な速度が大幅に向上することはありません。
2.3。 パッケージを高速で処理する際の生産性を向上させる最新の技術
パケットの高速処理の問題は比較的長いため、生産性を高めるためのさまざまな技術がすでに開発されており、処理速度を定性的に高めるために使用されています。
ソケットAPI
Berkley Packet Filter(以降BPF)は、rawパッケージにアクセスするための最も一般的なメカニズムです。 BPFはネットワークカードドライバーに接続し、受信または送信された各パケットのコピーをファイル記述子に送信します。ファイル記述子からユーザープログラムはそれを送受信できます。 Linuxには、AF_PACKETソケットファミリと呼ばれる同様のメカニズムがあります。 BPFはTCP / IPスタックで動作しますが、ほとんどの場合、ネットワークカードを「トランスペアレント」モード(無差別)に設定します。これにより、カーネルに入る大量の外部トラフィックがカーネル内で削除されます。
パケットフィルターフック
Netgraph(FreeBSD)、Netfilter(Linux)、Ndis Miniportドライバー(MS Windows)は、パッケージをコピーする必要がなく、ファイアウォールなどのアプリケーションをパケットフローチェーンに統合する必要がある場合に使用されるカーネル構築メカニズムです。 これらのメカニズムは、ネットワークカードドライバーからトラフィックを受信し、追加のコピーなしで処理モジュールに送信します。 明らかに、この句で示されるすべてのメカニズムは、mbuf / sk_buffの形式のパッケージの表現に基づいています。
ダイレクトバッファアクセス
パッケージをカーネル空間からユーザー空間に、またはその逆に転送するときに追加のコピーを回避する最も簡単な方法の1つは、アプリケーションがNIC構造に直接アクセスできるようにすることです。 通常、これにはアプリケーションがOSカーネルで実行される必要があります。 例は、クリックソフトウェアルータープロジェクトまたはカーネルモードpkt-genトラフィックジェネレーターです。 アクセスの容易さに加えて、カーネルスペースは非常に脆弱な環境であり、システムクラッシュを引き起こす可能性のあるエラーであるため、より適切なメカニズムはパケットバッファーをユーザースペースにエクスポートすることです。 このアプローチの例は、PF_RINGおよびLinux PACKET_MMAPです。これらは、ネットワークパケット用に事前に割り当てられた領域を含む共有メモリの領域をエクスポートします。 同時に、オペレーティングシステムのカーネルは、共有メモリ内のsk_buffersとパケットバッファー間でデータをコピーします。 これにより、パッケージのバッチ処理が可能になりますが、同時に、sk_buffチェーンのコピーと管理に関連するオーバーヘッドが残ります。
ユーザースペースからNICに直接アクセスできるようにすることで、さらに優れたパフォーマンスを実現できます。 このアプローチには特別なNICドライバーが必要であり、いくつかのリスクが増加します。 NIC DMAエンジンは、任意のメモリアドレスにデータを書き込むことができ、誤って書き込まれたクライアントは、カーネルのどこかで重要なデータを消去することにより、システムを誤って「殺す」可能性があります。 最新のネットワークカードの多くには、NIC DMAエンジンのメモリへの書き込みを制限するIOMMUユニットがあると言っても過言ではありません。 パフォーマンスを高速化するこのアプローチの例は、PF_RING_DNAおよびいくつかの商用ソリューションです。
3. NETMAPアーキテクチャ
3.1。 主な機能
前の記事では、高速でパケット処理のパフォーマンスを向上させるためのさまざまなメカニズムが検討されました。 データ処理のコストのかかる操作を分析しました。たとえば、データのコピー、メタデータの管理、およびパケットがユーザー空間からTCP / IPスタックを介してネットワークに渡されるときに発生するその他のオーバーヘッドです。
レポートに示されているNETMAPと呼ばれるフレームワークは、ネットワークとの交換時とTCP / IP OSスタック(ホスト)の操作時の両方で、受信と送信の両方のために、ネットワークパケットへの非常に迅速なアクセスをユーザー空間アプリケーションに提供するシステムですスタック)。 同時に、データ構造とネットワークカードレジスタがユーザー空間で完全に開かれている場合に生じるリスクに対して、効率が犠牲になることはありません。 フレームワークは、ネットワークカードとオペレーティングシステムを独立して管理し、同時にメモリを保護します。
また、NETMAPの特徴的な機能は、既存のOSメカニズムとの緊密な統合と、特定のネットワークカードのハードウェア機能への依存がないことです。 望ましい高性能パフォーマンスを実現するために、NETMAPはいくつかのよく知られた手法を使用します。
•コンパクトで軽量なパッケージメタデータ構造。 使いやすく、デバイス固有のメカニズムを隠し、パッケージを操作する便利で簡単な方法を提供します。 さらに、NETMAPメタデータは、単一のシステムコールで多種多様なパケットを処理するように設計されているため、パケット送信の負担が軽減されます。
•事前に割り当てられた線形バッファー、固定サイズ。 メモリ管理のオーバーヘッドを削減できます。
•インターフェイス間、およびインターフェイスとホストスタック間でパケットを転送するときのゼロコピー操作。
•複数のハードウェアキューなどのネットワークカードの便利なハードウェア機能のサポート。
NETMAPでは、各サブシステムは設計されたとおりに機能します。NICはネットワークとRAMの間でデータを送信し、OSカーネルはメモリを保護し、マルチタスクと同期を提供します。
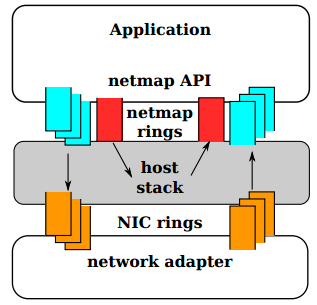
図 2番 NETMAPモードでは、NICキューはTCP / IP OSスタックから切断されます。 ネットワークとホストスタック間の交換は、NETMAP APIを介してのみ行われます
最高レベルでは、アプリケーションがNETMAP APIを介してネットワークカードをNETMAPモードにすると、NICキューはホストスタックから切断されます。 このため、プログラムは、ネットワークとOSスタック間のパケット交換を制御する機会を得て、「ネットマップリング」と呼ばれるリングバッファーを使用します。 ネットマップリングは、共有メモリに実装されます。 NICとOSスタックのキューを同期するには、通常のOSシステムコールが使用されます:select()/ poll()。 ネットワークカードからTCP / IPスタックを切断しても、オペレーティングシステムは引き続き動作し、操作を実行します。
3.2。 データ構造
主要なNETMAPデータ構造を図に示します。 番号3。 構造は、次のタスクを考慮して開発されました。
•パケット処理時のオーバーヘッドの削減
•インターフェイス間、およびインターフェイスとスタック間でパケットを転送するときの効率の向上
•ネットワークカードのハードウェア複数キューのサポート

図 番号3。 ユーザー空間のNETMAPエクスポート構造
NETMAPには、ユーザー空間から見える3種類のオブジェクトが含まれています。
•パケットバッファ
・リングキューバッファ(ネットマップリング)
•インターフェイスハンドル(netmap_if)
すべてのネットマップ対応システムインターフェイスのすべてのオブジェクトは、カーネルによって割り当てられ、ユーザー空間からプロセス間でアクセス可能な非ページ共有メモリの同じ領域にあります。 このような専用メモリセグメントを使用すると、すべてのインターフェイスとスタック間でゼロコピーパケット交換を簡単に実行できます。 同時に、NETMAPは、異なるプロセスに提供されるメモリ領域を相互に分離するような方法で、インターフェイスまたはキューの分離をサポートします。
異なるユーザープロセスは異なる仮想アドレスで動作するため、エクスポートされたNETMAPデータ構造内のすべてのリンクは相対的です。 オフセットです。
パケットバッファーはサイズが固定され(現在2K)、NICプロセスとユーザープロセスの両方で使用されます。 各バッファは一意のインデックスで識別され、その仮想アドレスはユーザープロセスで簡単に計算でき、物理アドレスはNIC DMAエンジンで簡単に計算できます。
すべてのネットマップバッファは、ネットワークカードがNETMAPモードになるときに割り当てられます。 インデックス、サイズ、およびいくつかのフラグなどのバッファを記述するメタデータは、スロットに格納されます。スロットは、後述するネットマップリングのメインセルです。 各バッファは、ネットマップリングおよびネットワークカード内の対応するキュー(ハードウェアリング)に接続されます。
Netmapリングは、ネットワークカードのハードウェアリングキューの抽象化です。 Netmapリングは、次のパラメーターによって特徴付けられます。
・ring_size、キュー内のスロット数(ネットマップリング)
•cur、キュー内の書き込み/読み取り用の現在のスロット
•avail、使用可能なスロット数:TXの場合、これらはデータを送信できる空のスロットです; RXの場合、これらはデータが到着したNIC DMAエンジンで満たされたスロットです
•buf_ofs、キューの先頭と固定サイズのパケットサイズバッファの配列の先頭との間のオフセット(ネットマップバッファ)
•スロット[]、ring_sizeで構成される配列で、固定サイズのメタデータの量。 各スロットには、受信したデータ(または送信するデータ)を含むパケットバッファーのインデックス、パケットサイズ、パケットの処理に使用されるいくつかのフラグが含まれます。
最後に、netmap_ifには、netmapインターフェイスを記述する読み取り専用情報が含まれています。 この情報には、ネットワークカードに関連付けられたキュー(ネットマップリング)の数と、NICに関連付けられた各キューへのポインターを取得するためのオフセットが含まれます。
3.3。 データ処理コンテキスト
上記のように、NETMAPデータ構造はカーネルとユーザープログラム間で共有されます。 NETMAPは、データを保護するような方法で、各構造の「アクセス権」と所有者を厳密に定義します。 特に、システムコールが行われない限り、ネットマップリングは常にユーザープログラムから管理されます。 システムコール中、カーネル空間のコードはネットマップリングを更新しますが、ユーザープロセスのコンテキストで更新します。 割り込みハンドラーおよびその他のカーネルスレッドは、ネットマップリングに接触しません。
curとcur + avail-1の間のパケットバッファーもユーザープログラムによって制御され、残りのバッファーはカーネルからのコードによって処理されます。 実際には、NICのみがパケットバッファーにアクセスします。 これらの2つの領域間の境界は、システムコール中に更新されます。
4. NETMAPの基本操作
4.1。 Netmap API
ネットワークカードをネットマップモードにするには、プログラムは特別なデバイス/ dev / netmapでファイル記述子を開き、実行する必要があります
Ioctl(...、NIOCREGIF、引数)
このシステムコールの引数には、インターフェイスの名前、および(オプションで)開いたばかりのファイル記述子を使用して開くネットマップリングを指定します。 成功すると、NETMAPによってエクスポートされたすべてのデータ構造が配置されている共有メモリ領域のサイズと、これらの構造へのポインタを取得するnetmap_ifメモリ領域へのオフセットが返されます。
ネットワークカードをネットマップモードに切り替えた後、次の2つのシステムコールを使用して、パケットを強制的に受信または送信します。
•ioctl(...、NIOCTXSYNC)-ネットワークカードの対応するキューと送信するためのキュー(ネットマップリング)の同期。これはネットワークへのパケットの送信と同等で、同期は位置curから始まります。
•ioctl(...、NIOCRXSYNC)-ネットワークから受信したパケットを受信するために、ネットワークカードのキューと対応するネットマップリングキューの同期。 位置curから録音が開始されます
上記のシステムコールは両方ともノンブロッキングであり、ネットワークカードからネットマップリングへのコピーおよびその逆を除き、データの不必要なコピーを実行せず、1つのシステムコールで1つ以上のパケットを処理します。 この機能は重要であり、パケット処理中のオーバーヘッドを大幅に削減します。 指定されたシステムコール中のNETMAPハンドラーのカーネル部分は、次のアクションを実行します。
•キューのcur / availフィールドと処理に関係するスロットの内容(ネットマップリングおよびハードウェアリング(ネットワークカードキュー)のパケットバッファーのサイズとインデックスをチェックします。
•ネットマップリングとハードウェアリング間の処理に関係するパケットスロットの内容を同期し、ネットワークカードにコマンドを発行してパケットを送信するか、データを受信するための新しい空きバッファの可用性についてレポートします。
•ネットマップリングのavailフィールドを更新します
ご覧のとおり、NETMAPカーネルハンドラーは最小限の作業を行い、入力されたユーザーデータをチェックしてシステムクラッシュを防ぎます。
4.2。 ブロッキングプリミティブ
ブロックされたI / Oは、/ dev / netmapファイル記述子を使用したselect()/ poll()システムコールでサポートされます。 結果は、パラメータavail> 0で制御が早期に戻ります。カーネルコンテキストから制御を返す前に、システムはioctl呼び出しと同じアクションを実行します(... NIOC ** SYNC)。 この手法を使用すると、ユーザープログラムは、CPUをロードすることなく、パスごとに1つのシステムコールのみを使用して、サイクルのキューのステータスを確認できます。
4.3。 マルチキューインターフェイス
複数のキューを備えた強力なネットワークカードNETMAPでは、プログラムを制御するために必要なキューの数に応じて、2つの方法で構成できます。 デフォルトモードでは、1つのファイル記述子/ dev / netmapがすべてのネットマップリングを制御しますが、ファイル記述子を開くときにring_idフィールドを指定すると、ファイル記述子は単一のネットマップリングRX / TXペアに関連付けられます。 この手法を使用すると、setaffinity()を通じてさまざまなネットマップキューのハンドラーを特定のプロセッサコアにバインドし、同期を必要とせずに独立して処理を実行できます。
4.4。 使用例
図5に示す例は、NETMAP APIに基づいた最も単純なトラフィックジェネレーターのプロトタイプです。 この例は、NETMAP APIの使いやすさを説明することを目的としています。 この例では、コードを理解しやすくするNETMAP_XXXマクロを使用して、対応するNETMAPデータ構造へのポインターを計算します。 NETMAP APIを使用するためにライブラリを使用する必要はありません。 APIは、コードができる限りシンプルで簡単になるように設計されました。
fds.fd = open("/dev/netmap", O_RDWR); strcpy(nmr.nm_name, "ix0"); ioctl(fds.fd, NIOCREG, &nmr); p = mmap(0, nmr.memsize, fds.fd); nifp = NETMAP_IF(p, nmr.offset); fds.events = POLLOUT; for (;;) { poll(fds, 1, -1); for (r = 0; r < nmr.num_queues; r++) { ring = NETMAP_TXRING(nifp, r); while (ring->avail-- > 0) { i = ring->cur; buf = NETMAP_BUF(ring, ring->slot[i].buf_index); //... store the payload into buf ... ring->slot[i].len = ... // set packet length ring->cur = NETMAP_NEXT(ring, i); } } }
プロトタイプトラフィックジェネレーター。
4.5。 ホストスタックとのパケットの送受信
ネットワークカードがネットマップモードに切り替えられた場合でも、OSネットワークスタックは引き続きネットワークインターフェイスを管理し、ネットワークカードからの切断については何も認識しません。 ユーザーは、ifconfigを使用したり、ネットワークインターフェースからパケットを生成または予期したりできます。 OSネットワークスタックに受信または転送されるこのトラフィックは、デバイスのファイル記述子/ dev / netmapに関連付けられた特別なネットマップリングのペアを使用して処理できます。
NIOCTXSYNCがこのネットマップリングで実行されている場合、ネットマップカーネルハンドラーは、OSネットワークスタックのmbuf構造にパケットバッファーをカプセル化し、パケットをスタックに送信します。 したがって、OSスタックからのパケットは特別なネットマップリングに配置され、NIOCRXSYNCの呼び出しを通じてユーザープログラムで利用可能になります。 したがって、ホストスタックに関連付けられたネットマップリングとNICに関連付けられたネットマップリングの間でパケットを転送する責任は、ユーザープログラムにあります。
4.6。 セキュリティに関する考慮事項
NETMAPを使用するプロセスは、たとえ何かが間違っていても、UIO-IXGBE、PF_RING_DNAなどの他のシステムとは異なり、システムをクラッシュさせることはできません。 実際、NETMAPによってユーザー空間にエクスポートされたメモリ領域には重要な領域は含まれていません。すべてのインデックスとパケットおよびその他のバッファのサイズは、使用前にOSカーネルによって簡単にチェックされます。
4.7。 ゼロコピーパケット転送
同じ共有メモリ領域内のすべてのネットワークカードのすべてのバッファが存在するため、あるインターフェイスから別のインターフェイスまたはホストスタックへの非常に高速な(ゼロコピー)パケット転送が可能になります。 これを行うには、着信および発信インターフェイスに関連付けられたネットマップリング内のパケットバッファーのインデックスを交換し、パケットサイズ、スロットフラグを更新し、ネットマップリングの現在位置(cur)を設定し、ネットマップ値を更新するだけです。リング/仕様書。これは、新しいパッケージの送受信を通知します。
ns_src = &src_nr_rx->slot[i]; /* locate src and dst slots */ ns_dst = &dst_nr_tx->slot[j]; /* swap the buffers */ tmp = ns_dst->buf_index; ns_dst->buf_index = ns_src->buf_index; ns_src->buf_index = tmp; /* update length and flags */ ns_dst->len = ns_src->len; /* tell kernel to update addresses in the NIC rings */ ns_dst->flags = ns_src->flags = BUF_CHANGED; dst_nr_tx->avail--; // src_nr_rx->avail--; // avail > 0
5.例:DDOS保護システムのトラフィック浄化サブシステムで使用するNETMAP API
5.1。 基本的な要件
NETMAPは、パケットのコンテンツにアクセスするための非常に高いパフォーマンスと便利なメカニズムの組み合わせ、インターフェイスとネットワークスタック間のパケットルーティングの管理により、ネットワークパケットを高速で処理するシステムにとって非常に便利なフレームワークです。 このようなシステムの例には、トラフィック監視アプリケーション、IDS / IPSシステム、ファイアウォール、ルーター、特にDDOS保護システムの重要なコンポーネントであるトラフィッククリーニングシステムがあります。
DDOS保護システムのトラフィッククリーニングサブシステムの主な要件は、最大速度でパケットをフィルタリングする機能と、現在DDOS攻撃に対処することが知られているさまざまな技術を実装するフィルターシステムでパケットを処理する機能です。
5.2。 ネットマップモードの準備と有効化
トラフィッククリーニングサブシステムのプロトタイプは、パケットの内容を分析および変更し、DDOS保護を実行するために必要な独自のリストとデータ構造を管理すると想定されているため、CPUリソースを再分配してDDOSモジュール操作を実行する必要があります。最低速度で全速力で動作します。 これらの目的のために、いくつかのCPUコアを「それらの」ネットマップリングで動作するように関連付けることが想定されています。
struct nmreq nmr; //… for (i=0, i < MAX_THREADS, i++) { // … targ[i]->nmr.ringid = i | NETMAP_HW_RING; … ioctl(targ[i].fd, NIOCREGIF, &targ[i]->nmr); //… targ[i]->mem = mmap(0, targ[i]->nmr.nr_memsize, PROT_WRITE | PROT_READ, MAP_SHARED, targ[i].fd, 0); targ[i]->nifp = NETMAP_IF(targ[i]->mem, targ[i]->nmr.nr_offset); targ[i]->nr_tx = NETMAP_TXRING(targ[i]->nifp, i); targ[i]->nr_rx = NETMAP_RXRING(targ[i]->nifp, i); //… }
OSネットワークスタックとパケットを交換する場合は、スタックとのやり取りを担当するネットマップリングカップルを開く必要があります。
struct nmreq nmr; //… /* NETMAP netmap ring ringid */ targ->nmr.ringid = stack_ring_id | NETMAP_SW_RING; // … ioctl(targ.fd, NIOCREGIF, &targ->nmr); // … <h2>5.3. rx_thread</h2> NETMAP, thread' <source lang="cpp"> for ( i = 0; i < MAX_THREADS; i++ ) { /* start first rx thread */ targs[i].used = 1; if (pthread_create(&targs[i].thread, NULL, rx_thread, &targs[i]) == -1) { D("Unable to create thread %d", i); exit(-1); } } //… /* Wait until threads will finish their loops */ for ( r = 0; r < MAX_THREAD; r++ ) { if( pthread_join(targs[r].thread, NULL) ) ioctl(targs[r].fd, NIOCUNREGIF, &targs[r].nmr); close(targs[r].fd); } //… }
その結果、すべてのスレッドを開始した後、max_threads + 1個の独立したスレッドがシステムに残り、それぞれが相互に同期する必要なく独自のネットマップリングで動作します。 同期は、ネットワークスタックと交換する場合にのみ必要です。
したがって、待機およびパケットループはrx_thread()で機能します。
while(targ->used) { ret = poll(fds, 2, 1 * 100); if (ret <= 0) continue; … /* run filters */ for ( i = targ->begin; i < targ->end; i++) { ioctl(targ->fd, NIOCTXSYNC, 0); ioctl(targ->fd_stack, NIOCTXSYNC, 0); targ->rx = NETMAP_RXRING(targ->nifp, i); targ->tx = NETMAP_TXRING(targ->nifp, i); if (targ->rx->avail > 0) { … /* process rings */ cnt = process_incoming(targ->id, targ->rx, targ->tx, targ->stack_rx, targ->stack_tx); … } }
したがって、poll()システムコールの後にnetmap_ringの1つが着信パケットを受信したというシグナルを受信した後、制御はprocess_incoming()関数に渡され、フィルター内のパケットを処理します。
5.5。 process_incoming()
process_incomingに制御を渡した後、さまざまなDDOS認識技術による分析と処理のためにパケットのコンテンツにアクセスする必要があります。
limit = nic_rx->avail; while ( limit-- > 0 ) { struct netmap_slot *rs = &nic_rx->slot[j]; // rx slot struct netmap_slot *ts = &nic_tx->slot[k]; // tx slot eth = (struct ether_header *)NETMAP_BUF(nic_rx, rs->buf_idx); if (eth->ether_type != htons(ETHERTYPE_IP)) { goto next_packet; // pass non-ip packet } /* get ip header of the packet */ iph = (struct ip *)(eth + 1); // … }
検討されたコード例は、NETMAPで作業するための基本的な手法を明らかにします。ネットワークカードをNETMAPモードにして、パケットがフィルターチェーンを通過するときにパケットのコンテンツにアクセスすることから終わります。
6.パフォーマンス
6.1。 指標
パフォーマンステストテストを実行するときは、常に最初にテストメトリックを決定する必要があります。 CPU、キャッシュ、データバスなど、多くのサブシステムがパケット処理に関与しています。 レポートは、CPU負荷パラメーターを次のように考慮します。 このパラメータは、パケットを処理するフレームワークの正しい実装に最も依存する場合があります。
通常、送信データのサイズ(バイトあたりのコスト)と処理済みパケット数(パケットあたりのコスト)の2つのアプローチに基づいてCPU負荷を測定します。 NETMAPの場合、ゼロコピーパケット転送が実行されるという事実により、バイトごとのCPU使用率の測定は、パケットごとのコストと比較してそれほど興味深いものではありません。 メモリのコピーがないため、大量のボリュームを転送する場合、CPUの負荷は最小限になります。 同時に、パケットごとのコストに基づく測定では、NETMAPは各パケットの処理で比較的多くのアクションを実行するため、このアプローチでのパフォーマンス測定は特に重要です。 そのため、測定は、サイズが64バイト(60バイト+ CRCの4バイト)の最短パケットに基づいて行われました。
2つのプログラムが測定に使用されました。NETMAPに基づくトラフィックジェネレーターと、着信パケットのカウントのみを実行するトラフィックレシーバーです。 トラフィックジェネレーターは、パラメーターとして、コア数、送信パケットのサイズ、1システムコールあたりの送信パケット数(バッチサイズ)を取ります。
6.2。 テスト用鉄とOS
テストアイロンとして、i7-870 4コア2.93GHz CPU(ターボブーストモードで3.2 GHz)を搭載したシステムを使用し、RAMは1.33GHzの周波数で動作し、Intel 82599チップセットに基づくデュアルポートネットワークカードがシステムにインストールされました。 FreeBSD HEAD / amd64を使用しました。
すべての測定は、ケーブルで直接接続された2つの同一のシステムで実行されました。 得られた結果はよく相関しており、平均からの最大偏差は約2%です。
最初のテスト結果は、NETMAPが非常に効率的であり、10GBit / sチャネルを最大数のパケットで完全に満たすことを示しました。 したがって、実験を実行するために、NETMAPコードによる変更の有効性を判断し、さまざまな依存関係を取得するために、プロセッサの周波数を下げました。 Core i7 CPUの基本周波数はそれぞれ133 MHzで、CPU乗算器(最大x21)を使用すると、最大3 GHzの離散値のセットでシステムを実行できます。
6.3。 プロセッサ、コアなどの周波数に応じた速度
最初のテストは、1つのシステムコール(バッチモード)で多数のパケットを転送し、異なる数のコアを使用して、異なるプロセッサ周波数でトラフィックを生成することです。
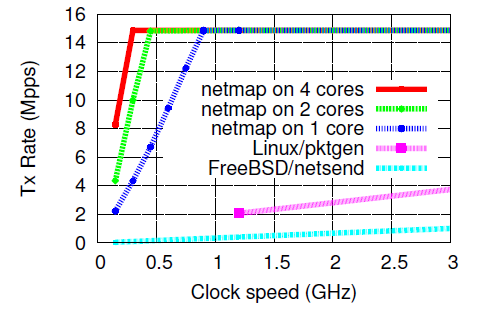
64バイトのパケットを送信する場合、シングルコアで周波数が900Mzの10GBit / sチャネルを即座に完全に満たすことができます。 簡単な計算では、1つのパケットを処理するのに約60〜65プロセッササイクルかかることが示されています。 明らかに、このテストでは、NETMAPパッケージ処理のコストのみが影響を受けます。 パッケージの内容の分析およびパッケージの有用な処理のための他のアクションは実行されません。
コアの数とプロセッサの周波数をさらに増やすと、ネットワークカードがパケットを送信するまでCPUがアイドル状態になり、パケットを送信するための新しい空きスロットの出現を通知しなくなります。
頻度が増加すると、1つのコアのプロセッサ負荷に関する次のインジケータを確認できます。

6.4。 パッケージサイズに応じた速度
前のテストでは、最短パケットでのパフォーマンスが示されています。これは、パケットごとのコストの点で最も高価です。 このテストでは、送信されたパケットのサイズに応じてNETMAPのパフォーマンスを測定します。
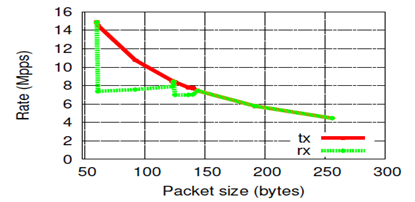
図からわかるように、パケットサイズの増加に伴い、ほぼ1 /サイズの式に従ってパケットを送信する速度は低下します。 これに加えて、驚いたことに、パケットの受信速度が異常に変化することがわかります。 65〜127バイトのサイズのパケットを送信すると、速度は7.5 Mppsに低下します。 この機能は、1Gbit / sを含むいくつかのネットワークカードでテストされています。
6.5。 システムコールごとのパケット数に応じた速度
明らかに、多数のパッケージを同時に使用すると、オーバーヘッドが削減され、単一のパッケージの処理コストが削減されます。 すべてのアプリケーションがこのように動作できるわけではないため、システムコールごとに処理されるパケットの数に応じてパケットの処理速度を測定することは興味深いことです。
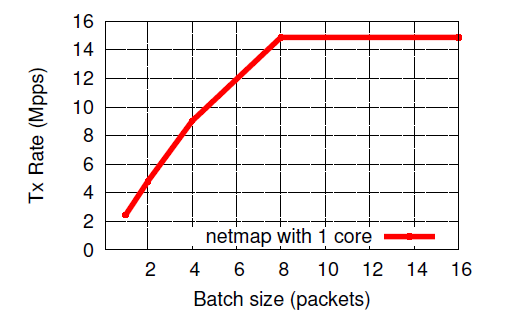
7.結論
NETMAPの作成者(Luigi Rizzo)は、パケットがOSネットワークスタックを通過するときに発生するパケット処理のオーバーヘッドを排除することで、生産性の劇的な向上を達成しました。 NETMAPで取得できる速度は、チャネルの帯域幅によってのみ制限されます。 NETMAPは、ネットワークパケットの処理における生産性を向上させるための最良の手法を組み合わせており、NETMAP APIで具体化された概念は、ネットワークトラフィックを処理するための高性能アプリケーションを開発するための新しい健全なアプローチを提供します。
現在、NETMAPの有効性はFreeBSDコミュニティによって評価されており、NETMAPはOS FreeBSDのHEADバージョン、stable / 9、stable / 8ブランチに含まれています。