この記事では、最も影響力のあるオブジェクトの検索について説明します。 この情報は、さまざまな仮想マーケティングキャンペーンを実施する場合と、疑わしいほど高いアクティビティを持つユーザーを特定する場合の両方に役立ちます。
はじめに
ソーシャルネットワークをグラフの形で表し、そのノードは人です。 オブジェクトが何らかの形で接続されている(フレンドである、または対応している)場合、これらのオブジェクト間にアークがあります。
 図 1
図 1
直感的な影響力の概念を提供します。 次の図を考えてください。
 図 2
図 2
ここで、中央のオブジェクトには6つの接続があります。 ただし、影響は接続の数に限定されません。 ターゲットオブジェクトが関連付けられているオブジェクトの影響度を考慮する必要があります。 写真を考えてみましょう。 3。
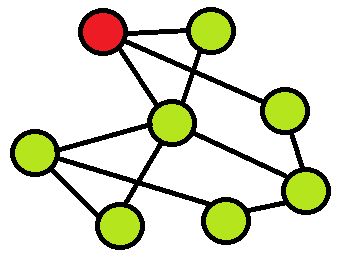 図 3
図 3
上の図は、オブジェクトに3つの接続があることを示していますが、関連付けられているオブジェクトはネットワークにある程度の影響を及ぼします。 この方法では、接続の数と、ターゲットオブジェクトが関連付けられているオブジェクトの影響の両方を考慮するために、影響の概念を形式化する必要があります。
マテリエル
この方向の研究の推進力は、この記事 [1]でした。 私は提案されたアルゴリズムを修正しましたが、それは私の意見では適切と思われます。
グラフは隣接行列として表されます。

次数kのオブジェクトiの反復力の概念を紹介します。

オブジェクトiの1次反復力は、このオブジェクトと他のオブジェクトとの接続の数であることに注意してください。 他のオブジェクトの影響はまだ考慮されていません。 2次から始まるこの量には、他のオブジェクトの影響が含まれます。
質問 :反復力のベクトルをどの順序で考慮する必要がありますか?
回答 :2または3。
事実は、オブジェクトkの反復力がオブジェクトiの影響度を表現することです。ただし、オブジェクトiの影響は半径kの範囲内でしか広がりません。 合計自体に固有のものです。 友だちに何かをするように誰かに頼んだときのことを覚えていますか? この影響は半径2にあり、反復された2次の力で表されます。 別の中間参加者とのチェーンを考慮する場合、3次の反復力のベクトルを考慮する必要があります。 実際の生活でこのような長いチェーンが出現する可能性は無視できるので、より大きな順序の反復力を考慮することは非現実的です。
したがって、大都市規模以上のオブジェクトの影響を計算する場合は、3次までカウントします。 小規模の場合は、2次を使用することをお勧めします。
反復力の数値ではなく、異なるオブジェクトの力が互いにどのように関係するかが重要であることに注意してください。 したがって、次の次数の反復力のベクトルを計算した後、このベクトルを正規化することをお勧めします。 基準として、最大値はその要素の絶対値に従って取得されます。
情報を収集します
情報はソーシャルネットワークVkontakteから収集されました。 2セットの友人をダウンロードするアプリケーションが作成されました:最大2レベルと最大3レベル。 明確にするために、図4を検討してください。
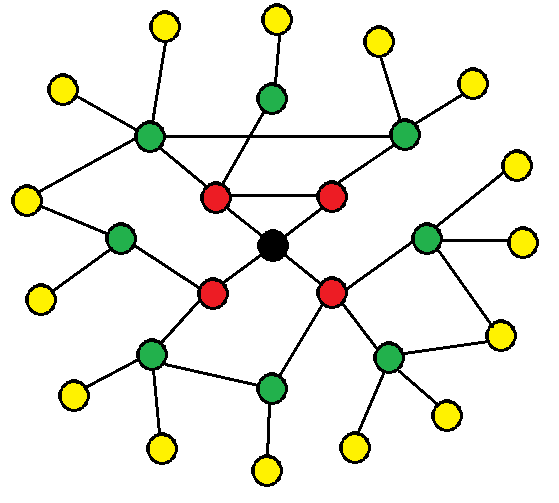 図 4
図 4
ここでは、第1レベルの友達は赤、緑-2番目、黄色-3番目でマークされています。 VK APIでは1秒間に3つ以上の要求を行うことができないため、3番目のレベルをロードするために夜間はマシンの電源を入れたままにする必要がありました。
 図 5
図 5
4つのレベルをダウンロードする場合、ネットワークユーザーの99%をダウンロードする可能性が高いことに注意してください。 6つの握手[2]の理論があり、地球上の任意の2人の間には5レベル以下の一般的な知人がいると主張しています。 VKは主にCISで配布されるという事実により、この数字は少なくなるはずです。
データの分析
したがって、2つのデータセットがあります。
- 2レベルの友人-約4万人のユーザー。
- 3レベルの友達-約420万人のユーザー。
私自身はソーシャルネットワークに座っていませんので、どちらの場合もサンプルの中心は私の友人であり、ヴォロネジ州立大学の学生でした。
最初のセットを分析することから始めましょう。
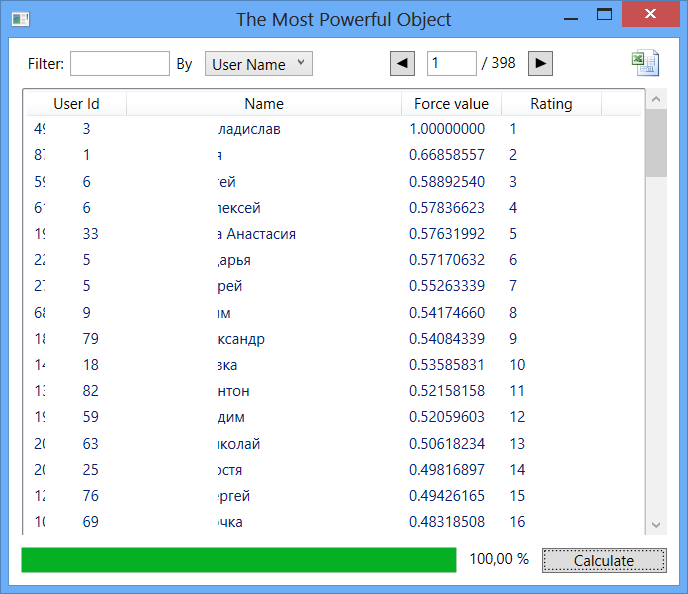 図 6
図 6
ここでは、サンプリングセンターが影響力の点で1位になりました。 これは、データのロード方法によって説明できます。 実際、最後のレベルの友人全体には1つの接続しか含まれていません。 これらのオブジェクトの場合、フレンドリストは空です。 したがって、第1レベルの友人(主に第2レベルの友人に基づく)の影響は低いと評価されます。 このため、客観的な結果は得られません。 それにもかかわらず、興味深いデータが観察できます。最初の30行には、ヴォロネジ州立大学の活動家の約半数がいます。
2番目のデータセットの調査に移りましょう。 ここでは、評価によるサンプリングの中心が3539位になります。
理解できます。ここでは、都市内ですでに影響力が考慮されています。
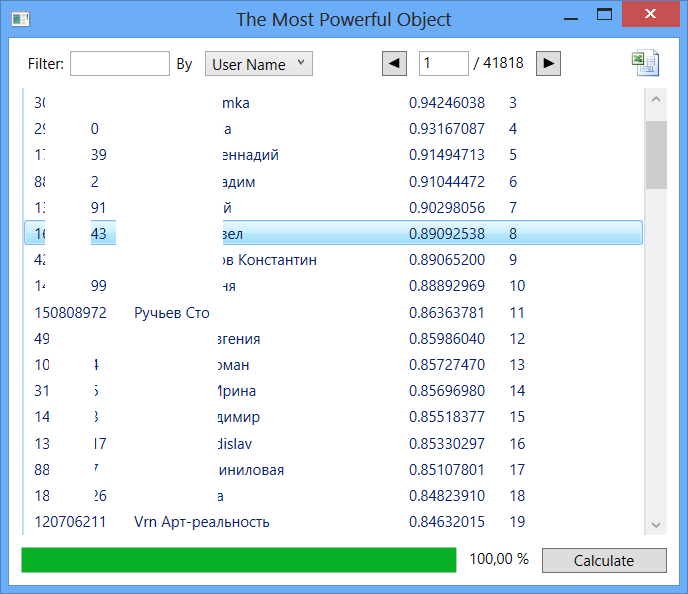 図 7
図 7
次のエントリは、この表の最初にトレースされます。
- ヴォロネジポスター
- 遠足
- ヴォロネジnightparty.ru
- 100ストリーム
- アートリアリティVrn
このリストの最初の行の人々に関しては、彼らの何人かは私たちの街の本当に有名な人々(主に写真家)であると言うことができます。 しかし、一部のオブジェクトのアクティビティは疑念を引き起こします。つまり、その人物についてのかなり貧弱な情報による影響の度合いが大きすぎます。 これらのオブジェクトは、現実の情報への準拠についてネットワーク管理者がレビューできます。
PS誰かがこのモデルを改善する方法について考えているなら、コメントで退会してください。
ソース:
- www.basegroup.ru/library/web_mining//information_flows_in_social_networks
- en.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D1%88%D0%B5%D1%81%D1%82%D0 %B8_%D1%80%D1%83%D0%BA%D0%BE%D0%BF%D0%BE%D0%B6%D0%B0%D1%82%D0%B8%D0%B9