フレームワークは、 有向非循環グラフとしてのタスクの表現に基づいており、グラフの頂点はプログラムであり、 エッジはデータが送信されるチャネルです。 Dryadフレームワークエコシステムもレビューされ、 フレームワークエコシステム の中心的なコンポーネントの1つである Dryad分散アプリケーションの実行環境のアーキテクチャの詳細な概要が作成されました。
この記事では、Dryadフレームワークソフトウェアスタックの最上位コンポーネントであるDryadLINQ分散ストレージクエリ言語について説明します。
#regionリリカルな余談(執筆意欲に関する)
Dryadについての昨日の記事で、Microsoft製品について何かを書くときはいつも書くべき段落が1つ欠けていました。
私は強調します:私は私の研究プロジェクトでドライアドの使用を提案したり、落胆させたりしません (現在、アカデミックライセンスのみが利用可能であるため)。 それ以上に、私はDryadが私たち全員が知っている悪の企業の「 内部 」 製品であり、その開発戦略[製品と悪] Microsoftが個別に決定する権利を持っていることを繰り返します(これはかなり公平です)。
これらのすべての事実は、ドライアドプラットフォームのアイデアや概念を専門家の開発にとってあまり面白くない、またはあまり役に立たない(私自身のために)。 あなたが何か違うものを持っている場合-これは私のためではなく、あなた次第です。
行を読んでいる人にとって、DryadLINQについてではなく、 Hadoopオープンソースプロジェクトとの比較についての記事が心配であり、代替ソリューションとの比較は次の記事でのみ行うことをお勧めします 。
私は強調します:私は私の研究プロジェクトでドライアドの使用を提案したり、落胆させたりしません (現在、アカデミックライセンスのみが利用可能であるため)。 それ以上に、私はDryadが私たち全員が知っている
これらのすべての事実は、ドライアドプラットフォームのアイデアや概念を専門家の開発にとってあまり面白くない、またはあまり役に立たない(私自身のために)。 あなたが何か違うものを持っている場合-
1.一般的な情報
順次および宣言型のコードを記述できるようにして、同じコードを単一のマシン、マルチコアマシン、またはマシンのクラスターで実行できるようにします。 これがDryadLINQプログラミングモデルの美しさです。
-Yuan Yu、マイクロソフトリサーチ主任研究員
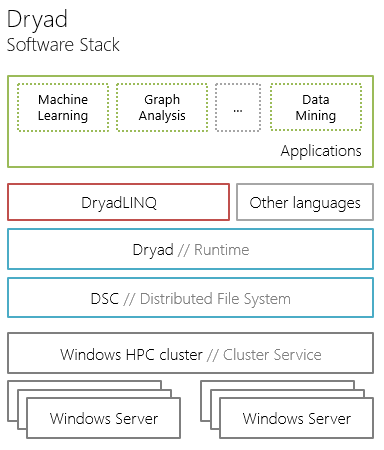
DryadLINQは、SQLのような構文を使用して、分散ファイルシステムに保存されているデータをクエリするための高レベル言語です。 DryadLINQは、.NET言語統合クエリ(LINQ)プログラミングモデルに基づいており、Dryadランタイムと対話するための特定のLINQプロバイダーを実装し、開発者に分散LINQ式を記述するためのAPIを提供します。
Hadoop-HiveQLプラットフォームのクエリ言語とは異なり、Pig Latin-DryadLINQは、特定の構文を持つ別のクエリ言語ではありません(学習に必要)。 代わりに、DryadLINQは.NET開発者になじみのあるものに基づいています。
- LINQ統合ソフトウェアモデル 。
- =>結果- データ要求を書き込むためのエレガントで機能的なアプローチ 。
- .NET Framework オブジェクトモデル
- MS Visual Studio 開発環境 。
- C#、F#、またはCLS互換言語などの高レベルPL 。
上記のリストの最初の段落を開くと、LINQには最初に要求が行われるデータウェアハウスの性質への明示的な参照が含まれていなかったことに注意してください。 また、LINQの上に構築されたDryadLINQ APIも
したがって、データベース(LINQ-to-SQLの場合)または分散ファイルシステム(DryadLINQの場合)にクエリを書き込むための構文の違いを最小限に抑えることにより、最も一般的なケースの1つに対するソリューションが大幅に促進されます-データベースベースのストレージからストレージへの移行分散ファイルシステムに基づいています。
分散アプリケーション開発者にとっては、DryadLINQのようです。 以下に、DryadLINQの内部実装、つまり、DryadLINQの基礎となるデータ、コンポーネント、および概念を照会する段階について説明します。
2.実装の段階

イラストのソース[5]
手順1. LINQ式を含むユーザー分散アプリケーションが実行されています。 LINQ式は遅延します(要求によって返されたデータが必要になるまで実行されません)。 DryadLINQ式も遅延して実行されます。
ステップ2. LINQ式を解析するとき、DryadLINQ固有のトリガー「ToDryadTable()」が呼び出されます。 DryadLINQはこのトリガーをインターセプトします(したがって、この段階でデータ要求が配信されることが明らかになります)。
ステップ3. DryadLINQはLINQ式をDryad分散クエリプランにコンパイルします 。LINQ式ツリーはサブクエリに分解され、各サブクエリは将来のDryad実行グラフの個別の頂点を表します。 リモート頂点操作の実行に必要なサービスデータの生成、トップでの実行可能コードの生成、必要なデータ型のシリアル化があります。
手順4. DryadLINQは、アプリケーション固有のDryad Job Managerを呼び出します。
手順5. Job Managerは、手順3で生成されたプランを使用して、アプリケーションランタイムグラフを作成します。
ステップ6.頂点プログラムは、定義されたピークで実行されます。
ステップ7. Dryadタスクの最後に、結果が出力テーブルに書き込まれます。
手順8. Job Managerは、DryadLINQジョブを実行して終了するノードに結果を返します。
手順9. DryadLINQ式の実行を開始したアプリケーションに制御が戻ります。 クエリの結果はDryadTableです。 DryadTableはIEnumerable <T>を実装しているため、厳密に型指定されたDryadTableコレクションのコンテンツには、通常の.NETオブジェクトのようにアクセスできます。
3. DryadLINQコンパイラー
DryadLINQクエリ言語の中心は、DryadLINQ 並列コンパイラです。 SQLクエリ言語の世界から類推すると、DryadLINQコンパイラをDBMSクエリスケジューラ/オプティマイザと比較できます。
コンパイラは、DryadLINQ式をコンパイルして、Dryadクラスターで実行される分散プログラムを作成します。 DryadLINQコンパイラには、実行計画を生成する静的コンポーネントと、さまざまなポリシーに基づいて実行を最適化し、実行時に実行計画を直接変更できる動的コンポーネントの両方が含まれています。
3.1。 実行計画グラフ
制御をコンパイラに転送するとき、後者はLINQ式を実行計画グラフ(EPG)に変換します。 EPGは、 パフォーマンスグラフのプロトタイプです (つまり、最終計画ではありません)。
DryadLINQオプティマイザーはEPGメタデータも補完し、計画および実行中に分散タスクに関する追加情報を提供できます。 したがって、グラフの頂点の場合、これはデータパーティションスキームに関する情報であり、グラフのエッジの場合、これは.NETデータタイプとデータ圧縮スキーム(存在する場合)です。
3.2。 DryadLINQの最適化
一方、DryadLINQオプティマイザーは、貪欲なヒューリスティックに基づく静的最適化と、 実行中に収集された統計情報に基づく動的最適化の両方を実行します。
静的最適化
静的オプティマイザーの主なタスクは2つです。ディスクメディアとネットワーク上の入出力操作の数を最小限に抑えることです。 従来はディスクサブシステムとマシン間の相互作用のインターフェイスが分散コンピューティング環境のボトルネックであるため、これは論理的です。
最も興味深い静的最適化手法を以下にリストします。
- パイプライン処理 (インプロセスインタラクション):オプティマイザーは、可能であれば、単一のコンピューティングノード内の計算のローカライズを最大化しようとします。
- I / O削減 :オプティマイザーは、デフォルトのデータ転送方法ではなく、TCPパイプとメモリ内FIFOを使用して頂点操作間でデータを転送しようとします-一時ファイルのディスクへの書き込み/ディスクからの読み取り(Dryadデータチャネルについては、前の記事で詳しく説明しました);
- 冗長性の削除 :オプティマイザーは、冗長/不必要なハッシュおよび範囲のパーティション分割手順を削除します。
動的最適化
動的オプティマイザーは、 分散タスクの実行中に実行グラフを変更します 。 したがって、収集された統計データ(潜在的に、特別に訓練されたモデルでさえ)に基づいて、オプティマイザーはグラフをオーバーライドできます。 動的最適化の主な手法は次のとおりです。
動的集約 :データ集約は、ノード間で転送されるデータ量を削減する最も効果的な方法の1つです。 集約は、コンピューティングノード、ラック、クラスターのレベルで順番に発生します。 このような最適化は、ノードのトポロジの場所と集約されたデータに大きく依存するため、実行時に(つまり動的に)実行するのが最も効率的です。
データ依存のパーティショニング :オプティマイザーは、入力データセットのサイズに応じて、データセット内のパーティション(パーティション)の数を動的に設定します。 動的集計の場合と同様に、分散タスクの実行中にのみ入力セットのサイズを推定することが正確に可能です。
4.練習
単語数
DryadLINQは、データクエリを記述するための驚くほど簡潔な構文を提供します。 次のリストは、map / reduceモデルによる計算の完全な実装です。
リスト1. map / reduceプログラミングモデルの実装。
public static IQueryable<TResult> MapReduce<TSource, TMap, TKey, TResult>( this IQueryable<TSource> source, Expression<Func<TSource, IEnumerable<TMap>>> mapper, Expression<Func<TMap, TKey>> keySelector, Expression<Func<IGrouping<TKey, TMap>, TResult>> reducer) { return source .SelectMany(mapper) .GroupBy(keySelector) .Select(reducer); }
リスト2は、上記のmap / reduceプログラミングモデルの実装を使用して、分散ファイルシステムに格納されているデータソースfoo.pt(パーティションテーブル)にDryadワードカウントタスクを作成する方法を示しています。
リスト2. DryadLINQを使用した単語カウント。
const string inputPath = @"file://\\machine\directory\foo.pt"; const string outputPath = @"file://\\machine\directory\count.pt"; PartitionedTable<LineRecord> inputTable = PartitionedTable.Get<LineRecord>(inputPath); var result = inputTable.MapReduce( r => r.Line.Split(' '), // r: rows w => w, // w: words g => new Tuple<string, int>(g.Key, g.Count())); // g: groups result.ToDryadPartitionedTable(outputPath);
Dryadフレームワークは、このアプリケーションの次のランタイムグラフを生成します。
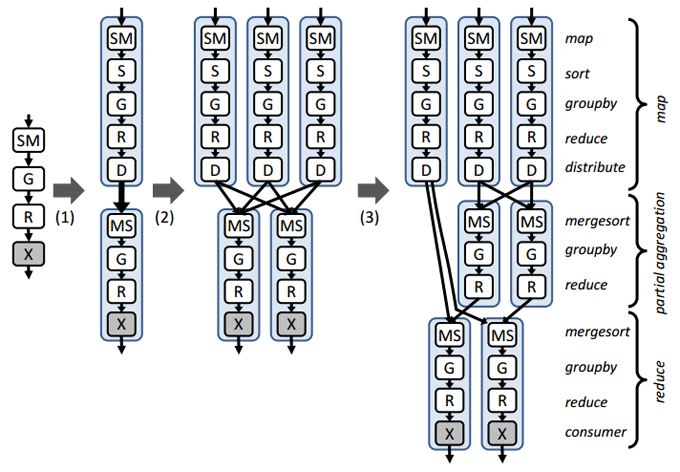
イラストのソース[3]。
さらに、ステップ(2)および(3)の実行グラフは、頂点間で送信されるデータの量と、このデータを処理する頂点操作のトポロジの位置に関する情報に基づいて動的に生成されます。
PageRankの計算
リスト3〜5は、分散PageRank計算アルゴリズムのコードを示しています。
リスト3. PageRankを計算するためのアルゴリズムの実装[5]。
public static IQueryable<Rank> PRStep(IQueryable<Page> pages, IQueryable<Rank> ranks) { // join pages with ranks, and disperse updates var updates = from page in pages join rank in ranks on page.Name equals rank.Name select page.Disperse(rank); // re-accumulate return from list in updates from rank in list group rank.Rank by rank.Name into g select new Rank(g.Key, g.Sum()); }
リスト4. DryadLINQを使用してPageRankを計算する。 ソース[5]。
const string inputPath = @"dfs://pages.txt"; const string outputPath = @"dfs://outputranks.txt"; var pages = PartitionedTable.Get<Page>(inputPath); var ranks = pages.Select(page => new Rank(page.Name, 1.0)); const int iterationCount = 1000; for (int iter = 0; iter < iterationCount; iter++) ranks = PRStep(pages, ranks); ranks.ToPartitionedTable<Rank>(outputPath);
リスト5.ヘルパークラス。 ソース[5]
public class Page { public Page(Int64 name, Int64 degreee, Int64[] links) { this.Name = name; this.Degree = degreee; this.Links = links; } public Int64 Name { get; set; } public Int64 Degree { get; set; } public Int64[] Links { get; set; } public Rank[] Disperse(Rank rank) { Rank[] ranks = new Rank[Links.Length]; double score = rank.Value / this.Degree; for (int i = 0; i < ranks.Length; i++) ranks[i] = new Rank(this.Links[i], score); return ranks; } } public class Rank { public Rank(Int64 name, double rank) { this.Name = name; this.Value = rank; } public Int64 Name { get; set; } public double Value { get; set; } }
異なる反復間のデータ転送は、メモリ内FIFOチャネルを介して行われます 。これにより、Hadoopでの同様のアルゴリズムの実装の場合のように、ネットワーク経由のデータ転送よりも桁違いに高いパフォーマンスが保証されます(Hadoopの最新リリースバージョンについて話している) 。
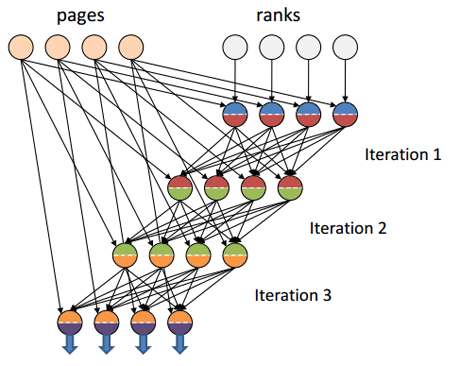
イラストのソース[5]
図への追加 :反復間のデータ転送反復1>反復2> ...>反復nは、メモリ内FIFOチャネルを介して排他的に発生します。
5.制限
Dryadフレームワークは、Hadoop MapReduceとは異なり、 分散アプリケーションを実行する責任と、そのようなアプリケーションを作成できるプログラミングモデル/クエリ言語を混在させません。
この責任区分にもかかわらず、私の意見では、DryadLINQソフトウェアモデルは 、DryadプログラムでのLINQ式の解釈に関する直接的な義務を引き受けるだけでなく、EPG実行グラフと最適化の構築にも関与している場合、それ自体で責任が混在しています。 後者の場合、Dryadタスクの起動時間が長くなることは避けられません。DryadLINQ式の解釈に費やすCPUサイクルが、より少ない義務で行った場合よりも多くなります。
その結果、1つのコンピューティングノードでの多くのDryadLINQ式の解釈は、ローカルレベルとクラスター全体のレベルの両方で、タスクの実行時間に大きな悪影響を及ぼします。 説明した問題が、Dryadクラスター全体のスケーラビリティの問題にどのように変わるかはまだわかりませんが。
別の発言は静的オプティマイザーに関連しています。これは、最適化を効果的に適用するために 、Dryadランタイムコンポーネントの内部「状況」-Webサイトのトポロジー、データパーティションスキームなど、 多くを知る必要があります 。
ドキュメントから、動的オプティマイザーがどのような統計を持っているのかは不明です:入出力操作の数の統計は、実行エンジン(Dryadランタイム)の内部データであり、プログラムモデル(DryadLINQ)のレベルで公開されるべきではありません。
DryadLINQは、静的最適化と動的最適化の両方を実行します。 [3]上記で引用した文章から、疑問がすぐに生じます。なぜ、動的最適化のタスクがDryadLINQの責任範囲に含まれているのですか? 実際、セマンティクスでは、DryadLINQ式の最終解釈の後、つまりランタイム環境のレベルで、動的オプティマイザーは既に機能しています。
6.利点
本格的なプログラミング言語
機能的なスタイルでデータクエリを作成できるLINQモデルを備えた、最新の高レベルプログラミング言語を使用した開発。
強力なデータ型付け
Dryadフレームワークは、強く型付けされたデータを計算し、強く型付けされたオブジェクトのコレクションを返します。
データの自動シリアル化
データは、チャネルを介して送信されるときに、フレームワークによって自動的にシリアル化/非シリアル化されます。
実行の自動並列化
DryadLINQは、クラスターで実行される分散実行計画を生成します。 ローカルで実行されるタスクにPLINQ(Parallel LINQ)を使用することで、マルチプロセッサコンピューティングノードの使用率が向上します。
自動パフォーマンス最適化
実行時グラフは、最適化ポリシーを使用して実行計画を作成するとき、および統計に依存して実行時に動的に、特別なDryadフレームワークコンポーネントによって最適化されます。
使い慣れた開発ツール
DryadLINQプログラミングモデルを使用してMPPアプリケーションを作成するには、MS Visual Studioと、Intellisense、コードリファクタリング、統合デバッグ、ビルド、ソースコード管理などのVS機能を使用できます。
.NET Frameworkとの完全な互換性
DryadLINQは、.NETライブラリおよびCLS互換の静的型付けプログラミング言語で使用できます。
おわりに
DryadLINQは、.net開発者になじみのあるソフトウェアモデルであり、既存の.NET Frameworkスタックに完全に統合された、表現力豊かで簡潔な、プログラムを記述する典型的な機能スタイルです。 さらに、DryadLINQモデルは、クエリを分散データウェアハウスに書き込み、クエリの分散性の詳細をカプセル化し、実行をスケジュールし、最適化するためのLINQのような構文を開発者に提供します。
退屈している人(またはボーナス)
ソースのリスト
[1] DryadLINQプロジェクト 。 Microsoft Research。
[2] M.アイサードとY.ユー。 高度なプログラミング言語を使用した分散データ並列コンピューティング 。 データ管理に関する国際会議(SIGMOD)、2009年。
[3] Y. Yu、M。Isard、D。Fetterly、M。Budiu、U。Erlingsson、PK Gunda、およびJ. Currey。 DryadLINQ:高級言語を使用した汎用分散データ並列コンピューティングのためのシステム 。 第8回オペレーティングシステムの設計と実装に関するシンポジウム(OSDI)の議事録、2008年。
[4] Y. Yu、M。Isard、D。Fetterly、M。Budiu、U。Erlingsson、PK Gunda、J。Currey、レポートMSR-TR-2008-74、Microsoft Research、2008年。
[5]李J陽。 ドライアド/ドライアドLINQスライドは 、2009年にYuan YuおよびMichael Isardのスライドを採用したものです 。