プロセッサコアで何らかの種類の計算を実行するのは退屈なので、大きな計算リソースを必要とするタスクが必要です。それは並列計算にうまく分解され、見た目はクールです。 レイトレーシングアルゴリズム、または簡単な方法でレイトレーシングを使用して、単純な3Dシーンをレンダリングするプログラムを作成することをお勧めします。
最初から始めましょう。私たちの目標は、すべてのプロセッサコアでの並列コンピューティングです。 すべての最新のPC用プロセッサーとARM(GPUについては言及していません)もマルチコアプロセッサーです。 これはどういう意味ですか? つまり、単一のコンピューター上のプロセッサーには、単一の処理コアではなく、複数のコアがあります。 一般的に、すべては少し複雑に見えます:複数のソケット(プロセッサチップ)をコンピューターにインストールでき、各チップ(単結晶内)に一度に複数の物理コアがあり、各物理コア内に複数の論理コア(たとえば、ハイパースレッディングテクノロジーの使用時に発生するものなど)。 これはすべて下図に概略的に示されており、トポロジと呼ばれます。

明らかに、ソケットは同じマザーボード上にインストールされたほんの数個のプロセッサです。 わかりやすくするために、以下にいくつかの写真を示します。

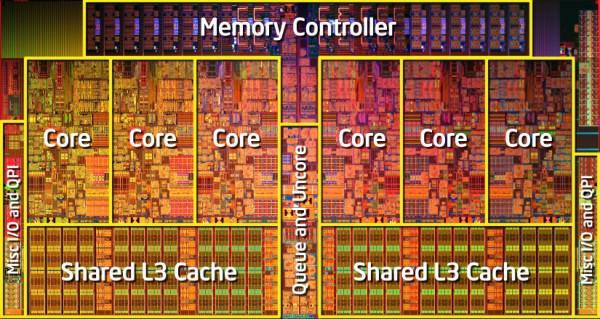
この中で最も興味深いのは、 論理コアの存在です。 これは、 SMT (同時マルチスレッディング)の原理を示しています。つまり、実際には、プロセッサパーツが解放されている間に別の論理スレッドから次の命令を実行し、メインスレッドからの命令の完了を待ちます。 プロセッサの各物理コアは多くのコンポーネント(キャッシュ、パイプライン、ALU、FPUなど)で構成され、多くの部分は互いに独立して動作し、同期する必要があるため、命令はキャッシュまたはメモリからのデータを待ってから実行を終了します。同じ命令を使用する別のスレッドからの命令? 詳細情報と写真は、このリンクまたはIntel、AMD、ARMの公式文書にあります。
この記事では、最適化を改善するためにのみトポロジーの詳細が重要になります(そして、すべてのカーネルは同じものとして認識されます)。 CPUID命令を使用してプログラムでトポロジを取得できますが、次回はその詳細を取得します。
さらにいくつかの概念を紹介します。
SMP (対称型マルチプロセッシング)-すべてのプロセッサーの対称的な使用を意味します。 たとえば、すべてのプロセッサコアは同じRAMに完全にアクセスでき、すべてのプロセッサコアは同じであり、同じ動作をします。
前の概念とは対照的に、 AMP (非対称マルチプロセッシング)は、少なくとも1つのコアが他のコアとは異なる動作をすることを意味します。 たとえば、CPUとGPUの共同作業は、AMPの例と考えることができます。
NUMA (非均一メモリアクセス)-メモリの異なる領域へのプロセッサアクセスの不均一。 実際、各プロセッサコアはすべてのメモリにアクセスできますが、各コアには、他のコアよりも高速にアクセスするメモリ領域があります。 再び最適化に使用されます。
現代のコンピューターシステムには、これらの原則と技術がすべて備わっています。
SMPを最も純粋な形で検討します。 システムが起動すると、プロセッサ自体が任意のカーネルを1つ選択し、 ブートストラッププロセッサ (BSP)と呼びます。残りはすべてアプリケーションプロセッサ (AP)になります。 BSPはBIOSコードの実行を開始し、システム内のすべてのプロセッサコアを見つけて起動し、初期化を実行して安全にオフにします。 したがって、開始後、プログラムはプロセッサの1つのBSPコアで動作するので、目標は一見、非常に単純に見えます:コンピューター上にあるコアの数を確認し、システム内の各コアを開始して構成し、すべてのコアに1つの計算を実行させるタスク、共通の利益のために。
目標を達成するには、いくつかの質問に答える必要があります。
システム内のプロセッサとコアの数とトポロジを決定する方法は?
これを行うには、素晴らしいACPIインターフェイスを使用する必要があり、トポロジーを決定するにはCPUIDを使用します。
特定のプロセッサコアを識別する方法
このため、システム内の各プロセッサコアが持つAPICデバイス、またはむしろLAPICは、システムの一意の識別子(プロセスのPIDなど)を持ち、特定のプロセッサコアに割り込みを配信する役割を果たします。
あるコアを別のコアから起動する方法は?
1つのプロセッサコアから別のプロセッサコアに割り込みを送信するだけで十分です。 この信号はIPI(Inter Processor Interrupt)と呼ばれます。 それを送信するには、コアの1つでLAPICデバイスを使用して、レジスタに特定の値を書き込むだけで十分です。
プロセッサコアの実行を停止する方法
このカーネルでHLT命令を呼び出すだけで十分です。
もう少し。 ACPI ( APICと混同しないでください)は、高度な構成および電源インターフェイスです-実際、オペレーティングシステムがコンピューター、その詳細な構成に関する情報を受信し、コンピューターの電源を管理できる標準インターフェイスです。 このインターフェイスは、電源管理デバイス(ACPIデバイスと呼ばれ、PCIに存在します( 記事を参照 ))と、コンピューターのRAMに配置され、システムに関する情報を含むいくつかのACPIテーブルで構成されます。 コンピューターのプロセッサコアに関する情報に加えて、一部のACPIテーブルには、コンピューターの物理的寸法とフォームファクターに関する情報も格納されます(たとえば、タブレットからプログラムが動作することがわかります)。 多くのテーブルがあり、それらの完全な説明はここで見つけることができますが、私たちはRSDTによって参照されるMADPにのみ興味があります。RSDPテーブルへのポインタはBIOSの近くにあります。 メインACPIテーブルの簡略図は次のとおりです。
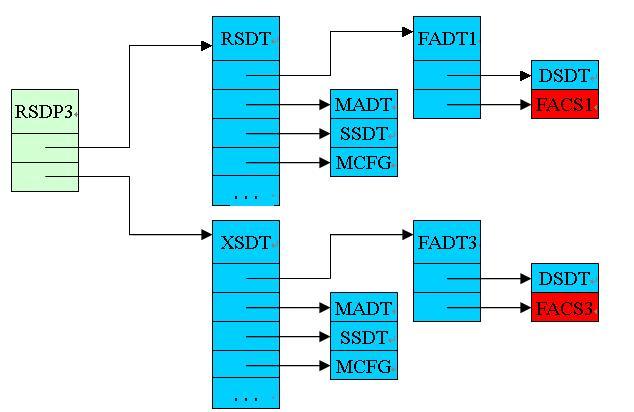
現時点で知っておく必要があるのは、プロセッサコアに関する情報を含むレコードがMADTに含まれていることだけです。 各エントリには、このカーネルのLAPIC識別子(8ビット長、システム内の任意のタイプの256コア以下を意味する)と有効化ビット(このカーネルを使用できるか、予約されているかを示す)が含まれます。
現在、 LAPICはローカルAPICであり、 APIC ( ACPIと混同しないでください)は、古いPIC(プログラマブル割り込みコントローラー)に代わる高度なプログラマブル割り込みコントローラーです。 PICはプロセッサに割り込みを即座に配信していましたが、現在はLAPICを介してこれを実行しています。 ローカルAPICはAPICの唯一のタイプではありません-IO APICもあります-これは独立した割り込みコントローラであり、システム上のプロセッサコア間で割り込みを分散する役割を果たします。 全体像は次のとおりです。
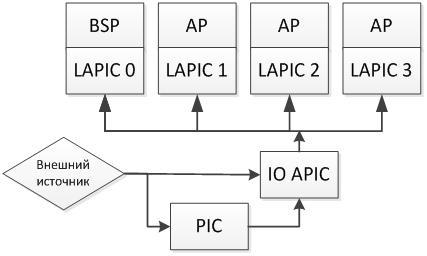
一見複雑に見えますが、それを理解すれば、すべてが非常に合理的です: PIC-長い間使用されてきた割り込みコントローラー-が残っていて消えていない、それはまだマザーボード上のチップセットの一部です。 マルチコアの登場により、 IO APICが追加されました。これは、誰かがこれを行う必要があるため、PICと他のソースからの割り込みをカーネル間で分散するようになりました。 各LAPICには、IPIおよびIO APIC構成で使用される一意の識別子が装備されています。 また、LAPIC番号にはトポロジがエンコードされています。 BSPのLAPIC識別子は常に0です。
LAPICをプログラムするには、レジスタへのデータの読み書きが必要です(他のデバイスと同様)。レジスタは0xFEE00000のメモリにあります。 実際、このアドレスは異なる場合がありますが、特別なMSR(モデル固有レジスタ-これらのレジスタはrdmsr / wrmsr命令を介して読み書きされます)を介して常に見つけることができます。 多くの場合、このアドレスは同じですが、各コアにはこのアドレスに独自のLAPICがあります。 このデバイスには多くのレジスタがありますが、IPIを送信できるICR (割り込み制御レジスタ)が1つだけ必要です。
プロセッサコアを開始するには、3つのIPIをこのコアに送信する必要があり、これにより別のコアが強制的にオンになります:INIT IPI、次にSTARTUP IPI、および別のSTARTUP IPI。最初のIPI(またはSIPI)は初期化プロセスを完了するために必要です。最初のSIPIが成功した場合、2番目は無視されます。 何もすることはありません-そのようなルール。 各IPIを送信するには、LAPICのICRレジスタに特定のバイトを書き込むだけです。 これらのバイトには、IPIが送信されるLAPICのバイトと、送信するIPIのタイプが含まれます。 SIPIの場合、さらに2バイトが使用され、そこからAPが起動されるメモリ内のアドレスが決定されます。
後者は非常に便利です。最初にコードからプロセッサを起動する必要があります。これにより、プロセッサが保護モードに移行します(はい、INIT-SIPI-SIPIがリアルモードで起動した後のプロセッサは適切ではありません)。 プロセッサ初期化コードについては、後で詳しく説明します。 はい、生のアセンブラなしではできません。
LAPICおよびIO APICの詳細については、Intelプロセッサのマニュアルをご覧ください。
現在、 Lock 、 FPU 、およびレイトレーシングアルゴリズム自体(ペイロード)のいくつかの小さな事柄に対処しています。
まだ最初に必要なことは、すべてのコアの動作を同期する機能です。 これを行うには、 ロックコードを記述します。これにより、メモリ内に、たとえば、統一の外観が期待されます。 正しくロックする方法は? 最も明白なオプション:つま先が特定のアドレスに現れることを期待する単純なwhile(1)を記述し、他のカーネルがこれを行う時間ができるまでそのアドレスにユニットをすぐに記述します。 そして、城のロックを解除するには、ゼロを書き込む必要があります。
現在、 FPU (浮動小数点ユニット)はプロセッサ上の特別なモジュールであり、浮動小数点を使用した算術計算に使用されます。 つまり、プログラムでfloat型とdouble型の変数を使用する場合は、このモジュールを初期化する必要があります。 最新のすべてのオペレーティングシステムでは、OSカーネルがこれを行いますが、この場合はユーザー次第です。 ただし、これは決して難しくありません。アセンブラーでの2、3の指示だけです。 それ以外の場合はレイトレーシングが機能しないため、フロートが必要になります。
レイトレーシングはどのように行いますか? このアルゴリズムはこの記事の範囲を超えているため、ここでは説明しませんが、それに関する多くの優れた記事があります。 私たちの場合、完成したプログラムを取得して少し変更します。
理論が終わったので、プログラムを書き始めましょう。
! 重要!: 記事「オペレーティングシステムなしでプログラムを実行する方法」の3番目のパートの 6つのステップすべてを正常に完了した後にのみ、以降のすべてのアクションを正常に実行できます。
ステップ1.まず、余分な部分をきれいにします。
まず、不要なファイルや関数から既存のコードをわずかにクリアする必要があります。 本格的な数学ライブラリが必要になるため、commonから余分なファイルを削除する必要があります。ファイルcommon / s_floor.cを削除します。
フラクタルを描画する必要はありません。レイトレーシングが必要なので、fractal.cを削除できます。 ただし、グラフィックモードが必要なため、kernel.cに次のコードを記述します。
1. main関数の前にいくつかの宣言を追加します。これらの宣言は、とりわけ、画面解像度とレンダリングする画像を設定します。
私は
nt vbe_screen_w = 800, vbe_screen_h = 600; int VBE_SetMode( ulong mode ); int VBE_Setup(int w, int h); extern ulong vbe_lfb_addr; extern ulong vbe_selected_mode; extern ulong vbe_bytes; // int ray_main(); void SmpPrepare(void);
2.メイン機能を変更します。
void main() { clear_screen(); printf("\n>>> Hello World!\n"); // SmpPrepare(); VBE_Setup(vbe_screen_w, vbe_screen_h); VBE_SetMode(vbe_selected_mode | 0x4000); // ray_main(); }
3.行を削除します。
void DrawFractal(void);
ステップ2.数学ライブラリfdlibmを追加します。
これで、本格的な数学ライブラリを追加できます。 実際、必要なのはsqrt、tan、およびpow関数だけです。これらはレイトレーシングアルゴリズムで使用されます。
1.ルートディレクトリfdlibmを作成します。
2.このディレクトリで、ここから fdlibmライブラリをダウンロードします 。 このフォルダーからすべてのファイルをアップロードする必要があります。
3.ここで、makefileをより単純なものに置き換える必要があります(同時にファイルのリストを確認できます)。 コンパイル中に、基本的にルートのメイクファイルと同じフラグが使用されます。 これにより、単純なライブラリfdlibm.aがコンパイルされます。 新しいメイクファイルの内容:
CC = gcc CFLAGS = -Wall -fno-builtin -nostdinc -nostdlib -ggdb3 LD = ld OBJFILES = \ e_acos.o e_acosh.o e_asin.o e_atan2.o e_atanh.o e_cosh.o e_exp.o \ e_fmod.o e_gamma.o e_gamma_r.o e_hypot.o e_j0.o e_j1.o e_jn.o \ e_lgamma.o e_lgamma_r.o e_log.o e_log10.o e_pow.o e_remainder.o \ e_rem_pio2.o e_scalb.o e_sinh.o e_sqrt.o \ k_cos.o k_rem_pio2.o k_sin.o k_tan.o \ s_asinh.o s_atan.o s_cbrt.o s_ceil.o s_copysign.o s_cos.o s_erf.o s_expm1.o \ s_fabs.o s_finite.o s_floor.o s_frexp.o s_ilogb.o s_isnan.o s_ldexp.o s_lib_version.o \ s_log1p.o s_logb.o s_matherr.o s_modf.o s_nextafter.o s_rint.o s_scalbn.o s_signgam.o \ s_significand.o s_sin.o s_tan.o s_tanh.o \ w_acos.o w_acosh.o w_asin.o w_atan2.o w_atanh.o w_cosh.o w_exp.o w_fmod.o w_gamma.o \ w_gamma_r.o w_hypot.o w_j0.o w_j1.o w_jn.o w_lgamma.o w_lgamma_r.o w_log.o \ w_log10.o w_pow.o w_remainder.o w_scalb.o w_sinh.o w_sqrt.o k_standard.o all: fdlibm.a rebuild: clean all .so: as -o $@ $< .co: $(CC) -Ix86emu –I../include $(CFLAGS) -o $@ -c $< .cpp.o: $(CC) -Ix86emu -I. -Iustl –I../include $(CFLAGS) -o $@ -c $< fdlibm.a: $(OBJFILES) ar -rv fdlibm.a $(OBJFILES) ranlib fdlibm.a clean: rm -f $(OBJFILES) fdlibm.a
4.すべてを組み立てるために、 k_standard.cに変更を加えます。 errnoを宣言し、空の関数fputsを定義する必要があります。この場合、ファイルシステムとグラフィック表示がないと意味がありません。 これを行うには、次の行を置き換えます。
#ifndef _USE_WRITE #include <stdio.h> /* fputs(), stderr */ #define WRITE2(u,v) fputs(u, stderr) #else /* !defined(_USE_WRITE) */
行ごと:
void fputs(void *u, int stderr) { } int errno = 0; #ifndef _USE_WRITE #define WRITE2(u,v) fputs(u, 0) #else /* !defined(_USE_WRITE) */
ステップ3.必要な定義とヘッダーを追加する
いつものように、プログラムで後で使用される定義をわずかに拡張する必要があります。
1.今回はテンプレートでもC ++が使用されるため、多くのエラーを回避するには、 include / string.hファイルを修正する必要があります。 その中で、void *がchar *に変換されるすべての場所で明示的な型変換を追加する必要があります。 42、53、54、79、80行です。 たとえば、同様の変更が行われた場合、修正された行42は次のようになります。
p =(char *)addr;
2.数学ライブラリの定義をいくつか追加する必要があります。 これらには、いくつかのグローバル変数定義、いくつかのタイプ、いくつかの定数、およびfdlibmが使用するエラーコードが含まれます。 その結果、次のコードを追加して/ types.hをインクルードします (ファイルの最後の最後の#endifの前):
typedef unsigned long long u64; #define FLT_MAX 1E+37 #define DBL_MAX 1E+37 #define LDBL_MAX 1E+37 # ifndef INFINITY # define INFINITY (__builtin_inff()) # endif #define NUM 3 #define NAN 2 #define INF 1 #define M_PI 3.14159265358979323846 /* pi */ #define __PI 3.14159265358979323846 #define __SQRT_HALF 0.70710678118654752440 #define __PI_OVER_TWO 1.57079632679489661923132 typedef const union { long l[2]; double d; } udouble; typedef const union { long l; float f; } ufloat; extern double BIGX; extern double SMALLX;
3.次のコードを含むファイルinclude / errno.hを追加します。
#ifndef _ERRNO_H #define _ERRNO_H extern int errno; #define EDOM -6 #define ERANGE -8 #endif
4.ここで、ハードウェア、SMP、ACPI、LAPIC設定、および特別なプロセッサレジスタのセットアップ機能に関連する多くの定義を追加する必要があります。 これを行うには、 次のコードを追加するinclude / hardware.hファイルを作成します 。 今回は、完成したコードを含む2つのファイルをgithubに投稿しました。 これは、コードが比較的大きい(〜500行)ことが判明したため、記事のフレームワーク内で記述するのは不便です。 コードにはロシア語のコメントが多数含まれているため、githubのコードは記事の続きと見なすことができます。 段落自体に、ファイルの内容を示します。
a。 ACPIテーブルの解析に使用される構造の定義。 このコードは、公式のACPI仕様に基づいています。 コードには、必要なテーブル(RSDP、RSDT、MADT)の定義のみが含まれます。
b。 さらにファイルには、アセンブラー命令を含むいくつかのインライン関数の宣言があります。 ほとんどの場合、関数は非常に小さくなっていますが、gccでアセンブラーを使用する特殊性のために大きく見えますが、典型的なデザインは次のようになります。 これらの関数の名前によるコードは、FreeBSD、Linux、およびBitvisorなどのプロジェクトの両方のコードで、インターネット上のさまざまな場所にあります。 次の関数を理解します:rdtsc、__ rdmsr、__ rdmsrl、__ wrmsr、__ wrmsrl、__ rep_nopおよび__cpuid_count、__ get_cr0、__ set_cr0。
c。 特に、SmpSpinlock_LOCKおよびSmpSpinlock_UNLOCKと呼ばれる2つの関数を強調したいと思います。 両方の関数はorangetide.com/src/bitvisor-1.3/include/core/spinlock.hから取得され、 アセンブラーでも記述されています。 これらは、同時に動作するプロセッサコアの同期オブジェクトを操作するための関数を表します。 これらは単純なロックです。 作業の本質は簡単です。メモリ内の1バイトがロックとして使用され、値0または1を取得できます。0の場合、ロックは開かれ、1の場合は閉じられます。 SmpSpinlock_LOCK関数の本質は、ロックのバイトの値0を待機し、このバイトを1に設定することです。待機するには、「休止」命令を使用して通常のサイクルを使用します。 値1を読み取ってメモリのバイトに同時に設定するには、「xchg」命令を使用します。これにより、メモリとレジスタ間で値をアトミックに交換できます。 アトミック性とは、別のプロセッサコアがこの命令の動作を中断することができず、その動作の途中で自身を妨害することを意味します。
d。 hardware.hコードは、LAPICに関連するいくつかの定数をさらに説明しています。 これらはIntelのドキュメントから取得されます。
e。 ファイルの最後で、別の__enable_fpuアセンブラー関数が宣言され、これによりプロセッサーでFPUが有効になります。 これは、float型を扱うために必要であることを思い出してください。 この機能は、カーネルでFPUを有効にするために必要な「fnclex」と「fninit」の2つの命令の実行です。
手順4.プロセッサコアの初期化コードを追加します。
これで、smp.cファイルの作成を開始できます。このファイルには、複数のプロセッサコアを操作するための関数が含まれています。 このファイルの最も重要な部分は、新しく起動されたカーネルで実行されるアセンブラーコードです。 smp.cコードもgithubにあり、説明付きのコメントがたくさんあります。 コードの一部はインターネット上の多くのソースから収集する必要があり、一部は自分で作成する必要がありました。 実際には、マルチコアのセットアップは各OSに固有の問題であるため、コードには特定のOSに必要なものが多く含まれています。 この記事の著者の目的は、このようなコードを単純化して、SMPを使用するために実行する必要のあるアクションと最小限のアクションの本質を示すことができるようにすることでした。 smp.cコードには2つの部分が含まれています。
1.各APを検索して有効にするコード。 すべての初期化の開始は、SmpPrepare関数の呼び出しで発生します。 一部のサブ機能には短い遅延が必要です。 タイマーまたはCMOSを使用してこれらの遅延を実行するのは正しいことですが、この例では、TSCカウンターの特定の値(開始から経過したプロセッサークロックサイクルのカウンター)の期待に基づいて遅延が使用されます。 SmpPrepareでは、次の手順が実行されます。
- a。 CPUIDを使用してLAPICを確認します。
- b。 MSRを介して基本LAPICアドレスを取得します。
- c。 64ビットICRレジスタの2つの部分へのポインターを取得します。 これらはメモリ内の特定の領域への通常のポインタです。 IPIの送信に使用されます。
- d。 次に、RSDPアドレスが検索されます。 TSDTテーブルのアドレスを決定します。 RSDTテーブルには、MADTのアドレスがあります。 MADTテーブル全体がスキャンされ、ローカルAPICに関連するすべてのエントリが分析されます。 各エントリにはLAPIC IDとカーネルイネーブルフラグが含まれています。 その結果、システム内にある検出されて含まれるすべてのLAPIC IDの配列が収集されます。
- e。 次のステップは、各プロセッサコアのスタックでメモリを予約することです。 スタックは64Kbで割り当てられ、物理メモリの5メガバイトから始まります。
- f。 次に、アセンブラコードが物理アドレス0x6000にコピーされ、APの各コアが初期化されます。 このコードについては以下で説明します。
- g。 その後、プロセッサコアの各APが起動されます。 これを行うには、特定のバイトをICRに書き込むことにより、INIT-SIPI-SIPI信号が各コアに順次送信されます。 このコードは(http://fxr.watson.org/fxr/source/i386/i386/mp_machdep.c)から取得されます。 コードを実行するには、以前に取得したLAPIC IDと、初期化コードにあるアドレス0x6000に対応するベクトル6が使用されます。
- h。 次に、BSPはすべてのプロセッサコアがオンになることを予期します。このため、オンになっているコアのカウンターが合計数と等しくなる瞬間を待ちます。 各APコアはこのカウンターを1増やします。
- i。 この関数でその作業を終了します。
2.各APで実行されるコード。 このコードはアセンブラーで始まります。 smp.cの先頭にすぐにあります。 このアセンブラコードでは、各行がコメント化されています。 このアセンブラコードを簡単に説明すると、次のアクションが実行されます。
- a。 フラグレジスタでいくつかのフラグを収集し、ベースレジスタをリセットして作業を開始します。
- b。 ページングなしでcr0に保護モードを含める。
- c。 32ビットコードセグメントへの移行。
- d。 GDTRとすべてのセグメントを32ビット(コードとデータ)としてロードします。
- e。 MSRからベースLAPICアドレスを読み取ります。
- f。 LAPICレジスタを読み取り、そのIDを決定します(現在のカーネル用)。
- g。 現在のカーネルのスタックポインターを取得します。 各コアでは、メモリがその個人スタック用に事前に予約されています。
- h。 Cでの関数呼び出し(SmpApMain)。
SmpApMain関数は、プロセッサインデックスを定義します。 インデックスは、0からNまでの番号です。ここで、N-1はコンピューター上のコアの総数です。 次に、実行中のコアのカウンターが同期的に増加します。これは、すべてのプロセッサーの開始を待機するために使用されます。 次に、プロセッサコアは、ペイロード起動フラグが有効になるのを待ちます。 フラグがオンになるとすぐに、ap_cpu_worker関数が呼び出されます-これはペイロード(レイトレーシング)を実行します。
ステップ5.レイトレーシングアルゴリズムの追加。
最も難しい部分は後ろにあります。 ここで、レイトレーシングアルゴリズムの形式でペイロードを追加する必要があります。 アルゴリズム自体はこの記事の範囲外であるため、 これらのリソースから理論と実践を入手できます。 レイトレーシングコードについてはコメントしません。 代わりに、完成したコードを基礎として、プログラムでコンパイルするために変更する方法を説明します。 ここからのコードを基礎としてみましょう。 その中で、メモリとSTLの動的割り当てを削除し、すべてを静的配列に置き換える必要があります。 次に、レンダリング機能を修正して、イメージ領域を1行ずつしかレンダリングできないようにする必要があります。 最後に、特定のパラメーターでrenderを呼び出すap_cpu_worker関数を実装する必要があります。
1. ray.cppファイルを作成します。 結果のコードをそこにコピーします 。
2.その中の行を置き換えます:
#include <cstdlib> #include <cstdio> #include <cmath> #include <fstream> #include <vector> #include <iostream> #include <cassert>
行ごと:
extern "C" { #include "types.h" #include "printf.h" #include "string.h" #include "hardware.h" double tan(double x); double sqrt(double x); double pow (double x, double y); extern int vbe_screen_w; extern int vbe_screen_h; extern ulong vbe_lfb_addr; extern ulong vbe_bytes; extern u32 cpu_count; extern ulong SmpStartedCpus; void SmpReleaseAllAps(); } namespace std { template <class T> const T& max (const T& a, const T& b) { return (a<b)?b:a; // or: return comp(a,b)?b:a; for version (2) } template <class T> const T& min (const T& a, const T& b) { return !(b<a)?a:b; // or: return !comp(b,a)?a:b; for version (2) } }
3.次の行を削除します。
friend std::ostream & operator << (std::ostream &os, const Vec3<T> &v) { os << "[" << vx << " " << vy << " " << vz << "]"; return os; }
そしてこれら:
// Save result to a PPM image (keep these flags if you compile under Windows) std::ofstream ofs("./untitled.ppm", std::ios::out | std::ios::binary); ofs << "P6\n" << width << " " << height << "\n255\n"; for (unsigned i = 0; i < width * height; ++i) { ofs << (unsigned char)(std::min(T(1), image[i].x) * 255) << (unsigned char)(std::min(T(1), image[i].y) * 255) << (unsigned char)(std::min(T(1), image[i].z) * 255);
4.交換:
const std::vector<Sphere<T> *> &spheres, const int &depth)
オン:
const Sphere<T> **spheres, unsigned spheres_size, const int &depth)
5. ray.cppファイル全体で 、 spheres.size()をspheres_sizeに置き換えます(合計3つの置き換え)。
6.レンダリング機能をこれに置き換えます:
void render(const Sphere<T> **spheres, unsigned spheres_size, unsigned y_start, unsigned y_end) { Vec3<T> pixel; T invWidth = 1 / T(vbe_screen_w), invHeight = 1 / T(vbe_screen_h); T fov = 30, aspectratio = vbe_screen_w / T(vbe_screen_h); T angle = tan(M_PI * 0.5 * fov / T(180)); // Trace rays for (unsigned y = y_start; y < y_end; ++y) { for (unsigned x = 0; x < (unsigned)vbe_screen_w; ++x) { T xx = (2 * ((x + 0.5) * invWidth) - 1) * angle * aspectratio; T yy = (1 - 2 * ((y + 0.5) * invHeight)) * angle; Vec3<T> raydir(xx, yy, -1); raydir.normalize(); pixel = trace(Vec3<T>(0), raydir, spheres, spheres_size, 0); // int color = ((int)(pixel.x * 255) << 16) | ((int)(pixel.y * 255) << 8) | (int)(pixel.z * 255); // *(int *)((char *)vbe_lfb_addr + y * vbe_screen_w * vbe_bytes + x * vbe_bytes + 0) = color & 0xFFFFFF; } } }
7.したがって、ファイル全体で、別のspheres_sizeパラメーターを追加して、トレース関数の残りの2つの呼び出しを修正します。
Vec3<T> reflection = trace(phit + nhit * bias, refldir, spheres, depth + 1);
に置き換えます:
Vec3<T> reflection = trace(phit + nhit * bias, refldir, spheres, spheres_size, depth + 1) ;
そしてこれ:
refraction = trace(phit - nhit * bias, refrdir, spheres, depth + 1) ;
に:
refraction = trace(phit - nhit * bias, refrdir, spheres, spheres_size, depth + 1) ;
8.ファイルの最後に、main関数の代わりに、 ray_main関数とap_cpu_worker関数を追加します 。
#define RAY_SHAPES_COUNT 6 Sphere<float> *ray_spheres[RAY_SHAPES_COUNT]; extern "C" void ap_cpu_worker( int index ) { __enable_fpu(); render<float>((const Sphere<float> **)ray_spheres, 6, vbe_screen_h/cpu_count * index, vbe_screen_h/cpu_count * index + vbe_screen_h/cpu_count); forever(); } extern "C" int ray_main() { Sphere<float> sp1 (Vec3<float>(0, -10004, -20), 10000, Vec3<float>(0.2), 0, 0.0); Sphere<float> sp2 (Vec3<float>(0, 0, -20), 4, Vec3<float>(1.00, 0.32, 0.36), 1, 0.0); Sphere<float> sp3 (Vec3<float>(5, -1, -15), 2, Vec3<float>(0.90, 0.76, 0.46), 1, 0.0); Sphere<float> sp4 (Vec3<float>(5, 0, -25), 3, Vec3<float>(0.65, 0.77, 0.97), 1, 0.0); Sphere<float> sp5 (Vec3<float>(-5.5, 0, -15), 3, Vec3<float>(0.90, 0.90, 0.90), 1, 0.0); Sphere<float> sp6 (Vec3<float>(0, 20, -30), 3, Vec3<float>(0), 0, 0, Vec3<float>(3)); ray_spheres[0] = &sp1; ray_spheres[1] = &sp2; ray_spheres[2] = &sp3; ray_spheres[3] = &sp4; ray_spheres[4] = &sp5; ray_spheres[5] = &sp6; SmpReleaseAllAps(); ap_cpu_worker(0); forever (); return 0; }
ステップ6.最近の改善と起動。
すべてがコンパイルされるように、メイクファイルをファイナライズするだけです。 これを行うには、次の変更を行います。
1. OBJFILESの更新:
OBJFILES = \ loader.o \ common/printf.o \ common/screen.o \ common/bios.o \ common/vbe.o \ common/qdivrem.o \ common/udivdi3.o \ common/umoddi3.o \ common/divdi3.o \ common/moddi3.o \ common/setjmp.o \ common/string.o \ x86emu/x86emu.o \ x86emu/x86emu_util.o \ smp.o \ ray.o \ kernel.o
2. C ++をコンパイルする目標を追加します。
.cpp.o: $(CC) -Ix86emu -I. -Iustl -Iinclude $(CFLAGS) -o $@ -c $<
3.次に、新しいライブラリを接続するために、リンカーの呼び出し行を変更する必要があります。
$(LD) -T linker.ld -o $@ $^ fdlibm/fdlibm.a
4.次に、ライブラリをビルドする必要があります。
cd fdlibm make rebuild
5.これで、プロジェクトを再構築できます。
make rebuild sudo make image
6. 4コアプロセッサをエミュレートするオプションを使用してプロジェクトを実行し、すべてが機能することを確認します。
sudo qemu-system-i386 -hda hdd.img –smp 4
すべてが正しく行われていれば、この美しさが見えるはずです。
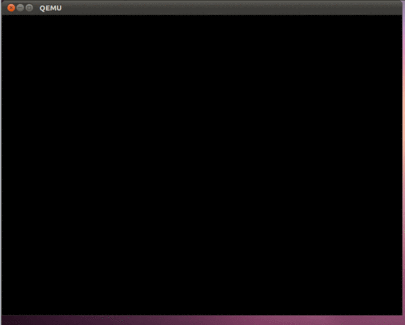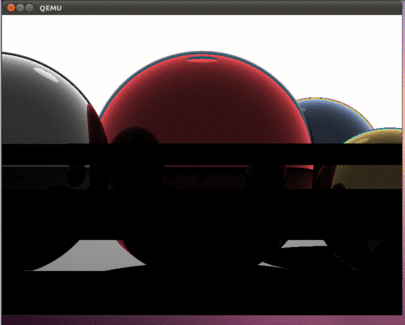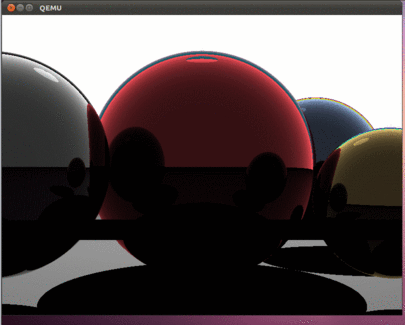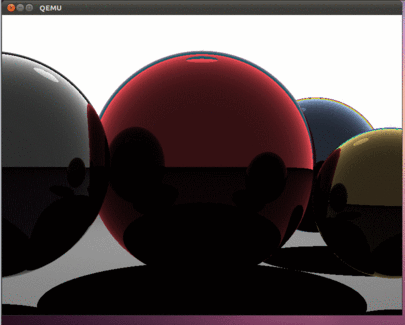
記事の前の部分と同様に、ddコマンドを使用して、hdd.imgイメージをUSBフラッシュドライブにコピーし、実際のコンピューターでプログラムをテストできます。
その結果、最新のプロセッサのすべてのコアを使用する興味深いプログラムができました。 この記事は、時間のかかる計算によって研ぎ澄まされたプログラムを開発する可能性を開きます。 前の記事と同様に、オペレーティングシステムがないため、すべての計算は利用可能なすべてのハードウェアリソースを使用して実行されることに注意することが重要です。 プログラムは割り込みさえ処理しません-それらは単にオフにされます。 したがって、どの速度ですべてが描画され、プロセッサの実際のコンピューティング機能が決定されます。 もちろん、プログラムがベアメタルで実行される場合、これはすべて当てはまります。 Intel i5は、この図を描くのに約800ミリ秒かかります。 コメントで、実際のハードウェアで取得した速度に関する情報を見るのは興味深いでしょう。
シリーズの次の記事へのリンク:
「 オペレーティングシステムなしでプログラムを実行する方法: パート5. OSからBIOSにアクセスする 」
「 オペレーティングシステムなしでプログラムを実行する方法: パート6. FATファイルシステムでディスクを操作するためのサポート 」