キャプチャのボトルネックは、異なる文字の同じスペルです:
- l = I(Lは小文字、iは大文字)
- O = 0 = O(両方の言語で小文字と大文字o、数字のゼロ)
- キリル文字とラテン文字の類似した文字、しかしそれらの多くがあります(ABCEHKMOPTX)
- 追加の問題は、キャプチャ自体によって配信されます。
VKontakteはcaptchaを人々に近づけようと試み、それをロシア化したが、我々が知っているように、彼らは英語版に戻った。
キャプチャの欠点には、その認識の時間を含める必要があります。 より多くの時間-より多くの注意がユーザーから奪われます-より多くの注意をそらします。 理想的には、キャプチャはユーザーの注意をまったくとるべきではありませんが、これは(今のところ)達成不可能です。
既存のキャプチャを見てみましょう。
Google-reCAPTCHA。


ソフトウェアの巨人から最も人気のあるキャプチャであり、言葉を提供する数少ないキャプチャの1つです。
短所:
- 認識されないテキストの大部分
- 2つの単語のうち1つは、システムによって制御されません。 英数字以外の文字
そのプラスは、公開されており、無料であり、サーバーにインストールする必要がないことです。
ヤンデックス


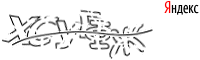
提供されるほとんどすべての写真が認識されますが、このためにはキリル文字を知っている必要があります。 外国人にとって、これは簡単なテストではありません。 最大のマイナス-あなたはナンセンスを導入する必要があります。
Mail.ru



私の意見では、最もい実装です。 数字と文字の両方が存在するため、ゼロと文字Oを混同することになります。このキャプチャでは、キリル文字とラテン文字のスペルが同じ文字のみが使用され、入力をチェックするために考慮されるかどうかはまったく関係ありません。ユーザーはまだそれについて考えます。
ヴコンタクテ



私が言えることは、色覚異常の人はどうやらこのキャプチャが大好きだということです。 0とOは使用されませんが、これは簡単ではありません。
批判-申し出!

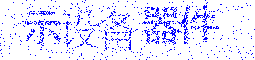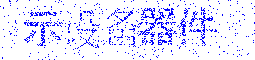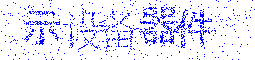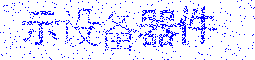

n + 1番目のcaptchaをお勧めします。 それは完全ではありませんが、上記の欠点がないように思えます。
その原理は人間の目の特性に基づいており、動きを全体像から簡単に区別できます。
構築アルゴリズムは非常に簡単です。
- 2つの確率が設定されます:背景ポイントの可視性とシンボルポイントの可視性。 差が大きければ大きいほど読みやすくなり、満足に読めるようにそのような差を選択します
- GIFアニメーション用にフレームが収集されます。この場合、キャラクターは開始位置に対してランダムに少しずらされます。
短所
- 従来のシングルフレームキャプチャよりも大きな画像サイズ
- それに応じて、生成に要する時間が長くなります。
- ランダムな文字セットには悪い
- これはまだアニメーションであり、さらにダウンロードしています
長所
- 文字を歪める必要はありません-ユーザーには通常のフォントが表示されます
- 色覚異常の人は他の人と同じように見えます
議論された利点
- 機械認識の複雑さ、つまり
- より小さな単語セットを使用できます。つまり、
- 通常の言葉を表示できます
- 目はすぐにキャプションを読む-ユーザーはキャプチャ認識にあまり注意を払わない
追加の利点
- キャプチャの背景は透明にすることができます。つまり、機能を失うことなくサイトの背景に適用できます。
- 背景色とドットを設定する機会を与えることができます-サイトパレットに準拠するため
- 任意の言語(象形文字を含む)を使用できます-これにより、認識の利便性が向上します
- このようなキャプチャの型破りな使用-たとえば、テキストではなく、そのようなgifを生成することにより、フォーラムで電話またはメールに通知するため
質問と懸念
最も重要な質問は、インターネットがさらに別のキャプチャを必要とするのか、それとも全員に適しているのかということです。
2番目の質問は、機械の認識にとってキャプチャが本当に難しいかということです。
そして3つ目-どのように改善できますか?
現在、gif生成モジュールはC#で記述されているため、速度は毎秒2-3キャプチャです(超最適化なし)。 gifの生成とパッケージ化の両方を最適化するには、C ++でこれを書き換える必要があります。
このキャプチャでスタートアップを作成したくないので、作成できません。 収益化の方法はそれほど多くありません。私に起こったのは、キャプチャに小さな広告を作成することだけでした。 有料のキャプチャはナンセンスです。
しかし、少なくとも費用がかかる場合は、このアイデアを販売できてうれしいです。