さらに、最もよく、少なくとも最小限の複雑で機能的なシステム(いずれにしても、私が銀行業界で8年の仕事で個人的に会ったシステム)は通常異質です-それらは多彩なキルトのような多くの機能ブロックで構成され、各パッチは、多くの場合異なるハードウェアプラットフォーム上であっても、異なるアプリケーションによって実行されます。 なんで? はい、それは合理的で便利です。 各製品はその分野で優れています。 たとえば、経済学者はExcelを使用してデータを分析および視覚化することを好みます。 しかし、このプログラムを使用して深刻な人工ニューラルネットワークをトレーニングしたり、微分方程式をリアルタイムで解決したりすることを考える人はほとんどいません。このため、柔軟なAPIを提供する強力なユニバーサルパッケージがしばしば購入される(または既に会社によって取得されている)か、注文用に個別のモジュールが作成されます。 そのため、同じMatlabで結果を検討し、(Linuxクラスターで実行されている)Oracle DBMSテーブルに保存し、WindowsでOLEサーバーとして実行されるExcelでユーザーにレポートを表示する方がより有益であることがわかります。 さらに、これらのコンポーネントはすべて、ユニバーサルプログラミング言語の1つによって接続されています。
特定のタスクに最適な実装環境を選択する方法は? あなたは妥協に直面しています:いくつかのツールやライブラリはあなたにより馴染みがあり、他のものはより多くの機能を持っています(例えば、それらはOOPをサポートします)、他のものは実行速度に利点があります(例えば、C ++のようなSSEベクトル化を使用します)、4つ目は高い開発速度を提供します(例えば、 Visual Basic)。 コンパイラ、コンピューター数学システム、オフィススイート、ハードウェアテクノロジー(x86-x64、Cell、GPGPU)、およびそれらの共同作業を組織化する手段(ネットワーク、クラスター、クラウドコンピューティング)の両方のソフトウェアツールが印象的な量が今日市場で提供されています。
これに、コンピューティングリソースの使用の傾向(並列コンピューティングへの大量移行、アプリケーションとサーバーの仮想化)、コンピューティングパワーを提供する新しいモデル(Amazon EC2など)、フォールトトレランスを確保する新しい方法、ライセンスの微妙な違いを追加すると、膨大な数の組み合わせが得られます。 最高の選択方法は?
主な推奨事項は、最初に開発速度が最も速い環境でプロトタイプを作成し、次により時間のかかるオプションに移動して、このサブタスクを解決する時間がなくなるまでパフォーマンスメトリックの改善(たとえば、実行時間の短縮)を試みることです。 同時に、意図的にスケーラブルでないソリューションにエネルギーを浪費してはいけません。 怠けてはいけません。コードを書いて「ライブ」でテストし、推測を確認してください。 理論的な知識と繊細な直観は問題ありませんが、小さな生産問題を解決する私の経験でわかるように、現実は私たちのモデルやアイデアとは異なることが非常に多くあります。
先日、私は単純なアルゴリズムのパフォーマンスを最適化する必要がありました。1から2億までのすべての整数の正弦の合計を数えることです。 実際、実際のアルゴリズムは多少異なっていましたが、同様のクラスの問題を解決するための最適なツールを探していました。初期段階で各プロトタイプに完全なインフラストラクチャを構築することは理にかなっていないため、アルゴリズムを限界まで単純化しました。 なぜこの種のアルゴリズムが必要なのか疑問に思っているなら、三角関数を人工ニューラルネットワークのしきい値活性化関数として使用できることを思い出します。 ネタバレ:研究の結果は私にとって完全に予想外でした!
問題文:
ワークベンチ:デュアルXeon E5 2670 @ 2.6 Ghz、アイドル時のCPU周波数を下げる省エネテクノロジー、ハイパートレッド機能を備えた2x8物理コア、Windows Server 2008R2プラットフォームの128 Gb DDR3-1600メモリ

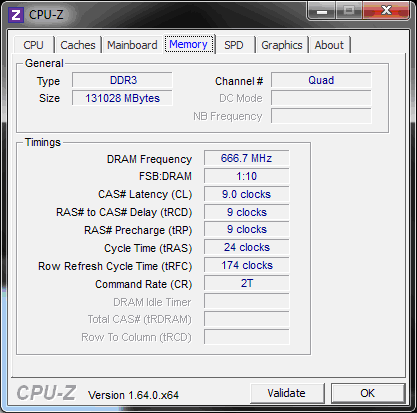
開始時の倍精度(倍精度、つまり標準のx86コプロセッサーフォーマットの1つ)は、私たちを完全に満足させます。 異なるコンパイラ、そして異なるコンピューティングアーキテクチャが、サインの合計を計算するタスクにどのように対処するかを見てみましょう。 レースの参加者:Maple 12、Maple 17、MatLab R2013a、Visual Basic 6.0、Visual Basic.NET、およびVisual C ++ 2012(一般的に、手元にいる人)。 すべての時間測定は再起動後に行われ、平均時間に対応しています。
私は、テスト方法論が最も厳格ではないことを知っています。1つのタイプのプロセッサ、1つのOS、パフォーマンスを測定する簡単な方法だけです。 ただし、科学記事はありません。したがって、最も興味深い事実に限定します。 コンポーネント間通信の構成の詳細には触れません(原則として、Win、COMコンポーネント、通常のdll、共有メモリアクセスで十分です)。どの組み合わせを使用すると、目的の結果をすばやく計算できるかを確認するだけです。 最初に、どのツールが最速のシングルスレッドバージョンを生成するかを見つけ、それを並列化します。
Mapleから始めましょう。
st := time():evalhf(sum(sin(i),i=1..200000000));time() - st;
Maple 12の結果:
54.304秒で1.25023042417602160
Maple 17の結果:
19.656秒で1.25023042417610020
一見、MapleSoftエンジニアのすばらしい仕事。 製品のバージョンごとにランタイムが75%改善されました。 17番目のバージョンでもこの手順をコンパイルできるかどうか見てみましょう。 ナイーブコール
cp:=Compiler:-Compile(proc(j::integer)::float;local i::integer: evalhf(sum(sin(i),i=1..j)) end proc:):
何らかの理由で、どんな状況でもゼロを生成するプロシージャを取得します。 私たちは代替案を試みます-明示的なサイクル。
p2 := proc(j::integer)::float;local i::integer,res::float;res:=0; for i from 1 to j do: res:=res+evalhf(sin(i)):end do; res end proc:
コンパイルせずにp2を実行すると、結果は待つことができません! 少なくとも10分待ってあきらめました。 どうやら、Mapleランタイムでは、sum関数はループと比較して大幅に最適化されています。 しかし
cp2:=Compiler:-Compile(p2): st := time():cp2(200000000);time() - st;
Maple 17では、優れた結果が得られます。
9.360秒で1.25023042417610020!
システムの「トリック」にも関わらず、永続性と創意工夫を示しながら、優れたパフォーマンスの向上を得ることができました:-)
Microsoft Visual Studio 2012への移行
私は、コンパイルされたコードのひどい遅さで、かつてNetプラットフォームに深く失望していたことをよく覚えています。 私のテストケース(コンパイル済み!)VB.Net 2003では、VB6コードの約8倍の速度で実行されたため、VB.Net 2012のプロジェクトを構築するときに幻想はありませんでした。
Public Class Form1 Private Sub Form1_Load(sender As Object, e As EventArgs) Handles MyBase.Load Dim i As Long, res As Double, tm As DateTime tm = Now For i = 1 To 200000000 res = res + Math.Sin(i) Next TextBox1.Text = res & vbNewLine & Now.Subtract(tm).TotalSeconds.ToString("0.000") End Sub End Class
結局のところ、無駄に!
VB.Net 2012の結果:
11.980秒で1.25023042417527、悪くない!
もちろん、最適化Visual C ++コンパイラに主な期待を割り当てました。次の手順をNetスラグなしでネイティブ実行可能コードにコンパイルするつもりです。
#include <iostream> #include <windows.h> using namespace std; int main() { double res=0.0; int dw = GetTickCount(); for (int i = 1; i <= 200000000; i++) res+=sin(i); cout.precision(20); cout << "Result: " << res << " after " << (GetTickCount()-dw); }
使用されるキーは/ O2および/ Otです。
VC ++の結果:Net 2012:
まったく印象的ではない:11.404秒で1.2502304241761002。
古い学校のVB6の番
コードは非常にシンプルに見えます:
res = 0: for i = 1 To 200000000: res = res + Sin(i) : Next i
最大の最適化でコンパイルします:
そして、VB6に直面してチャンピオンを獲得します。
結果:1.25023042417543、使用時間:0:00:09(9.092153)
では、12年前の製品がすべての点で新しいコンパイラーをどのように投入しているかを説明してください。 MSは劣化しているようですが、これは別の会話のトピックです。 逆アセンブラーのリストを見ると、VC ++コンパイラーがコードを正直にベクトル化したことがわかります。
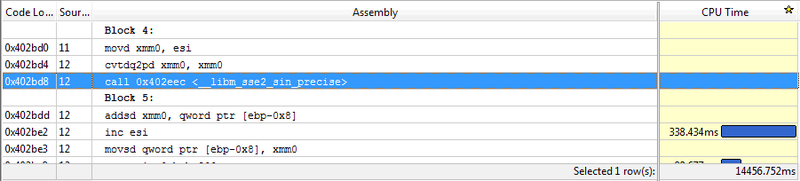
確かに、SSE2でのこのサインの実装の詳細はわかりませんが、Visual Basic 6で使用されているFPUスタックの単一オペランドコマンドが失われた場合、何が良いでしょうか? そのような不快な発見の後、秘密をお伝えします。インテルParallel Studio XE 2013の試用版をダウンロードし、QxSSE4.2キーを使用してインテルC ++ 13コンパイラーでプロジェクトを再構築し、その後13〜15秒で結果がさらに悪化しました。 そのような結果の後、ワイルドな思考が生じました-私のサーバーのプロセッサーですべてが正常に動作しているとは限りませんか? VB6とVC ++ 2012の比較を、2つのコアを持つ古いCore Duo 6600という別のマシンで開始しました。 SSEバージョンの遅延はさらに大きくなります。 唯一の論理的な説明は、コアアーキテクチャから始まって、IntelエンジニアはSSEと比較してFPU操作のパフォーマンスを大幅に改善し、MicrosoftおよびIntelコンパイラの開発者はこの事実を失ったということです。
ちなみに、上の図では、ホットスポットモードのVtune AmplifierプロファイラーがSSE命令のタイミング計算に対応できないことがわかりました。 あなたが彼を信じているなら、私のコードで最も時間のかかる操作はループカウンターを増やすことです! 学術的な関心から、Intelパッケージがインストールされてから、並列化できるコード内の場所を表示するように設計されたAdvisor XE 2013製品を介してモジュールを実行しました。 データ依存性のない短いサイクルで、並列実行のための共有リソースPERFECTがなければ、この製品はそのような場所を見つけることができませんでした。 さて、より複雑なケースでこのプログラムを信頼する方法は? 広く知られているが、練習には適していないものの、Intelプログラマーが製品をリリースしているという意識が高まっています(LarrabeeとKnights Cornerのトウモロコシの発表と再発表を思い出すと、プログラマーだけでなく)。 まあ、まだMatlabがあります。
Matlabでの実験はうれしい驚き
タイピング
tic;sum(sin(1:200000000));toc;
ほとんどすぐに結果が表示されます。
1.250230424175050、経過時間は3.621641秒です。
まあ、まあ! 賢いMatlabは、この式をローカルマシン上の物理コアの数ですぐに並列化して、全負荷を確保することが判明しました。 いいですね。 結局のところ、私は強力なハードウェアの代金を支払ったので、ソフトウェア(とにかく、決して安くはない)を100%使用したいと思っています。 MathWorksのエンジニアを尊重してください!
コンパイルしてみましょうか? これを行うには、式をmファイルに転送します。 そして、別の驚きが私たちを待っています。 コンパイルされていないチック; FastSum(200000000); toc; すでに5.607512秒の経過時間を与えます。 誰がすでにこれに遭遇しましたか、問題は何ですか? 私にとって、それは謎です。 deploytoolコマンドのヘルプを使用して、一定の時間待機すると、Matlabは0.5 MBの巨大な実行可能ファイルを作成します。 はい、コンパイラの開発チームには他に取り組むべきことがあります-比較のために、VC ++のサイズは46Kb、VB.Netは30Kb、Vb6は36Kbです。 しかし、Matlabコンパイル済み実行可能ファイルは何を提供しますか?
1.2502、経過時間は10.716620秒です。
ご覧のように、コンパイルされたバージョンでは、何らかの理由でループの自動並列化が消えます。 私の心は、会社がParallel Computing Toolboxのために余分なお金を望んでいることを教えてくれます:-)
いずれにせよ、シングルスレッドによるVB6リーダーが存在するため、この環境で単純なActive Exeサーバーを作成しました。これにより、特定のスレッド数で計算を並列化できます。

ワークフローの数を1から32に増やすことでソリューションがどれだけうまくスケーリングするかを見てみましょう。正直に言うと、HTの仮想コアがどこからリソースを取得するかによって、物理プロセッサコアの数が上限に達するまでパフォーマンスが向上することを確信していましたFPUパイプラインがすでに完全に占有されている場合の浮動小数点
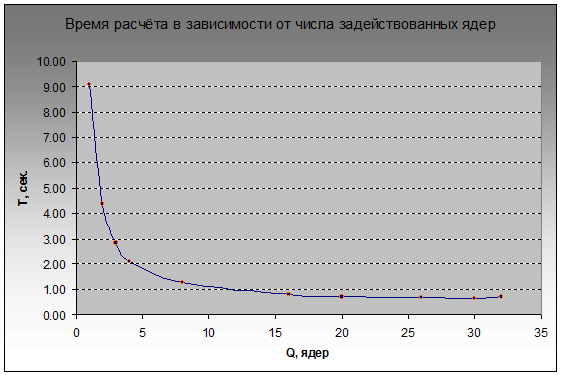
それにもかかわらず、14個の論理コアが追加で含まれているため、実行時間を20%短縮できました。t(16)= 0.803秒から。 t(30)= 0.645 プロセッサが最初に省電力モードになっていない場合、おそらく結果はより印象的です。0.6秒で、クロック周波数を最大に上げる時間がないように見えるためです。
GPGPU
さて、特定のケースで主流の構成に最適なソリューションを見つけました。 しかし、GPGPU(ユニバーサルコンピューティングを実行できるグラフィックカード)を忘れないでください。最近ではサーバーが増え、すべてのホームコンピューターと新しいラップトップにはほぼ確実に装備されています。 私のスタンドサーバーも例外ではありませんでした。特にマルチスレッドコンピューティング用に、CUDAテクノロジーをサポートする、 Fermiアーキテクチャを備えたデュアルチップGTX 590グラフィックスカードである元フラッグシップのNvidiaが購入されました。
一般的に、私はNvidiaを非常に尊敬していると言わなければなりません。 第一に、これはおそらく大規模(会議、セミナー、イベント、ソフトウェアとアーキテクチャの積極的な開発と改善)に高並列コンピューティングを実際に促進する唯一の企業であるため、第二に、ハードウェア」であり、新しい高性能コンピューティングセクターで主導権を握ります。 はい、AMD(ATI)ソリューションはより強力で、AMDカードのギガフロップはより多くなる可能性がありますが、FireStream向けの開発を開始してください-AMDのWebサイトには、テクノロジーの説明資料やわかりやすい説明はありません。 AMDプログラマー/マーケティング担当者/幹部は、単に才能のあるATIエンジニアの仕事を埋めているように見えます。 したがって、これまでの選択はCUDAです! ところで、CUDA 5とVisual Studio 2012の統合に問題がある場合は、 この記事の推奨事項を使用できます。
それでは、奇跡のデバイスにはどのようなリソースがありますか?

ご覧のとおり、理論的には、2つのGPUデバイスで16 * 1536 * 2 = 49152スレッドで計算を実行できます。 実際、すべてがそれほどバラ色ではありません-Fermiの正弦は特殊機能ユニットでカウントされ、そのうち4つはマルチプロセッサ(SM)上にあります。 同時に計算できる合計値は、16 * 4 * 2 = 128以下です(理論的にも)。
特にCUDAの最適化の微妙な点については、すぐにCUDAアーキテクチャの詳細に立ち入りたくありません。これは、それ自体が科学と芸術の両方です。 したがって、低レベルのCUDA Cに加えて、CUDAモデルの高レベルの抽象化によりプログラマーの生産性を向上させるために設計された、 Thrustライブラリーの簡単なプロトタイプから始めましょう。
作成者によると、Thrustの魅力は、開発者が算術演算、ソート、あらゆる種類の削減などのプリミティブを個別に実装する時間をもはや必要としないことです(おそらく、CUDAマニュアルに精通した後、ほとんどのプログラマーの語彙に確実に入力された用語) 、検索、配列の再編成、およびその他のタイプの操作。 さらに、このライブラリは最適な起動構成を個別に決定し、以前のようにブロック数とGPUフローの最適な比率を決定することに集中する必要はありません...
ThrustはすべてのCUDA互換デバイスを自動的にアクティブにするわけではありませんが、最速の1つを選択しますが、いずれにしても、Nvidiaのナンバークラッシャーで無条件の勝利を期待していましたが、倍精度計算のパフォーマンスの低下については知っていました。 結局のところ、2億の正弦を計算することは1つのことですが、この配列全体を1つの合計値に効果的に削減する必要があります。
強力なtransform_reduce関数を使用します。これにより、1つの論理ステップで配列の要素を変換および合計できます。 特別なファンクターsin_opを作成してみましょう。 コードは非常に簡単です。
#include <thrust/transform_reduce.h> #include <thrust/device_vector.h> #include <thrust/host_vector.h> #include <thrust/functional.h> #include <thrust/sequence.h> #include <windows.h> using namespace std; template <typename T> struct sin_op { __host__ __device__ T operator()(const T& x) const { return sin(x); } }; int main(void) { int dw = GetTickCount(); int n=10; double res=0.0; sin_op<double> tr_op; thrust::plus<double> red_op; thrust::device_vector<int> i(200000000/n); for (int j=1;j<=n;j++) { thrust::sequence(i.begin(), i.end(),200000000/n*(j-1)+1); res = thrust::transform_reduce(i.begin(), i.end(), tr_op, res, red_op); } cout.precision(20); cout << res << endl<< "Total Time: " << (GetTickCount()-dw) << endl; }
外部ループを使用して、必要な量のメモリをデバイスに確保します。残念なことに、Thrustは常に単独でこれを行うとは限りません。 論理的には、スレッドは整数インデックスを計算し、それに変換ファンクタを適用し、結果を高速共有メモリに保存する必要があります。 だから、コンパイル、実行:
1.704秒で1.2502304241755013
失望に制限はありません。 kakbeの結果は、ライブラリがアクセラレータに私たちが想像したものとまったく同じことを強制していないことを示唆しています。 実際、詳細なタイミングを見ると、ライブラリは最初にデバイスの比較的低速なメインメモリ(時間の35%を消費する)にゼロの巨大な配列を配置しようとし、次にこれらのゼロを自然数1,2,3 ...(40%時間)、まあ、残りの25%は正弦の計算と直接加算(プラス演算子による削減、および遅いメインメモリ)に関係しています。
悲しいことに、このライブラリには仮想イテレータ(ファンシーイテレータ)があることを思い出します。 ドキュメントを調べます-確かに、
constant_iteratorとcounting_iteratorは配列として機能しますが、実際にはメモリストレージを必要としません。 これらのイテレータの1つを間接参照すると、その場で適切な値が生成され、呼び出し元の関数に返されます。カウントイテレータは、医師が注文したものです。
#include <thrust/iterator/counting_iterator.h> #include <thrust/transform_reduce.h> #include <thrust/device_vector.h> #include <thrust/host_vector.h> #include <thrust/functional.h> #include <thrust/sequence.h> #include <windows.h> using namespace std; template <typename T> struct sin_op { __host__ __device__ T operator()(const T& x) const { return sin(x); } }; int main(void) { int dw = GetTickCount(); double res=0.0; sin_op<double> tr_op; thrust::plus<double> red_op; thrust::counting_iterator<int> first(1); thrust::counting_iterator<int> last = first + 200000000; res = thrust::transform_reduce(first, last, tr_op, res, red_op); cout.precision(20); cout << res << endl<< "Total Time: " << (GetTickCount()-dw)<< endl; }
リードタイムは? 彼らはそれをほぼ半分にし、メインメモリでの非効率な操作を取り除きました:
0.780秒で1.2502304241761253
待機中のデバイスコンテキストへの空の呼び出しでも時間がかかることを念頭に置いておく必要があります。少なくとも今回は平均0.26秒でした。 場合によっては、0.52秒でさえ、数テラフロップスのピークパフォーマンスを備えた超並列アーキテクチャデバイスから期待される結果ではありません。 CUDA Cでコアを自分で記述してみましょう。これにより、予備的な集計が実行されます。 それほど難しくありません...このために、計算を等しい長さのブロックに分割します。 各ブロックは、高速共有メモリ内の要素の並列削減を実行し、ブロックインデックスに等しいオフセットで、アクセラレータのグローバルメモリに結果を保存します。
__global__ void SumOfSinuses(double *partial_res, int n) { // extern- extern __shared__ double sdata[]; // int i =blockIdx.x*blockDim.x+threadIdx.x; sdata[threadIdx.x] = (i <= n) ? sin((double)i) : 0; __syncthreads(); // for (int s=blockDim.x/2; s>0; s>>=1) { if (threadIdx.x < s) { sdata[threadIdx.x] += sdata[threadIdx.x + s]; } __syncthreads(); } // , if (threadIdx.x == 0) partial_res[blockIdx.x] = sdata[0]; }
理論的には、1つのブロックの合計は、デバイス上で最大1024タームです。 SumOfSinusesカーネルへの最初の呼び出しの後、デバイスのメモリに約20万の中間項があります。これは、thrust :: reduce:への1回の呼び出しで簡単に追加できます。
int main(void) { int dw = GetTickCount(); int N=200000000+1; cudaDeviceProp deviceProp; cudaGetDeviceProperties(&deviceProp, 0); double *partial_res; int rest=N;int i=0;double res=0; int threads_per_block=1024;//deviceProp.maxThreadsPerBlock; int max_ind=deviceProp.maxGridSize[0] * threads_per_block; checkCudaErrors(cudaMalloc(&partial_res, max_ind/threads_per_block*sizeof(double))); thrust::device_ptr<double> arr_ptr(partial_res); do { int num_blocks=min((min(rest,max_ind) % threads_per_block==0) ? min(rest,max_ind)/threads_per_block : min(rest,max_ind)/threads_per_block+1,deviceProp.maxGridSize[0]); SumOfSinuses<<<num_blocks,threads_per_block,threads_per_block*sizeof(double)>>>(partial_res,i*max_ind,N); checkCudaErrors(cudaDeviceSynchronize()); // thrust- , res = thrust::reduce(arr_ptr, arr_ptr+num_blocks,res); rest -=num_blocks*threads_per_block; i++; } while (rest>0); cudaFree(partial_res); cout.precision(20); cout << res << endl<< "Total Time: " << (GetTickCount()-dw)<< endl; }
0.749秒で1.2502304241758133
CUDAブロックのメッシュサイズが制限されているため、Doループを使用する必要があります。 したがって、この場合、コアはループから3回呼び出され、毎回約7000万語を処理します。 それにもかかわらず、パフォーマンスは倍精度の超越関数の計算にかかっているため、Thrustは比較的低いパフォーマンスを責めることはできません。より理解しやすくエレガントなコードで最初のオプションを使用することをお勧めします。 ところで、私たちのアプローチは、CUDA互換デバイス(ローカルクラスターを編成できるデバイス)の数によってまだスケーリングされていません。 これは修正できますか? 何らかの理由で2つのデバイスと補助バインディング全体(cudaSetDevice、cudaStreamCreate / cudaStreamDestroyを呼び出す)の間でコンテキストを簡単に切り替えるには、すでに約0.5秒かかりました。 つまり、複数のCUDAデバイスにまたがるスケーリングは、カーネルの実行時間が長く、コンテキストの切り替えのオーバーヘッドが見えない場合に有益であることがわかります。 私たちの場合、これはそうではないので、記事の範囲外の複数のデバイスにスケーリングを残します(ホスト側で複数のストリームを使用すべきだったかもしれませんが、わかりません)。
私はほとんど忘れていました-MatlabはCUDAデバイスでのコード実行を3年間サポートしています(もちろん、いくつかの制限があります)。 興味のある方は英語のウェビナーを見ることができます(登録が必要です)。 客観性のために、Mapleでは、いくつかの線形代数パッケージプロシージャのレベルで、CUDAサポートが初歩的であると言われるべきです。 この点で、MatLabははるかに高度です。 現在のバージョンでは、ホストから配列をコピーすることなく、デバイス上で直接配列を配列で埋めることができるかどうかはわかりません(ドキュメントによる判断ではできません)。 そこで、正面アプローチを適用します。
tic; res=0.0;n=10;stride=200000000/n; for j=1:n X=stride*(j-1)+1:stride*j; A=gpuArray(X); res=res+sum(sin(A)); end toc; gather(res)
1.250230424175708、経過時間は2.872859秒です。
デュアルチップアクセラレータの両方のプロセッサでコードをすぐに動作させることはできませんでした。マニュアルでは、このトピックは完全には公開されていません。 Spmdは機能し、2つの部分に分割された複合配列が作成されます。 ただし、ある時点で、プログラムは失敗し、データはもう利用できないと言っています。 matlabで複数のGPUを既に使用している人;-)とにかく、matlabバージョンはThrustでの実装より高速ではありません。
まあ、私はfa然として、Vtuneイベントプロファイリングを使用してキャッシュミスやその他の微妙さを最適化した純粋なアセンブラバージョンを追加したいと思いますが、力はありません:-)ボランティアがいる場合は、結果を送信してください。記事。 ナイツコーナーの下で打ち上げの結果を見るのも面白いでしょうが、残念なことに、適切なハードウェアはありません。
そして最後まで読んだ人へのボーナス
きっと多くの人が私が浮気していることに気づきました。 サインの特定の合計は、2億個の数値を合計するだけでなく、複数の数量を単純に乗算することでも取得できます。
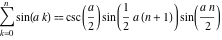
さて、または気付かないことですが、MathematicaまたはMapleで数式をシンボリック形式で駆動します。 正確な小数点以下50桁で検索された数値:
最も重要で最適な最適化は常にアルゴリズムレベルで行われます:-)それにもかかわらず、行われた作業は役に立たなかったわけではありません-結局、より複雑なパターンでは分析式を使用できない可能性が高く、すでに数値の問題に対処する方法がわかっています。 ちなみに、合計の精度が重要な場合は、小さな用語を大きな合計に追加するときに有効数字が失われないようにするために、追加の対策を講じる必要があります。たとえば、Kaganアルゴリズムを使用します。 あなたが興味を持っていたことを願っています!
よろしく
アナトリー・アレク
シーエフ05/24/2013
さて、または気付かないことですが、MathematicaまたはMapleで数式をシンボリック形式で駆動します。 正確な小数点以下50桁で検索された数値:
1.2502304241756868163500362795713040947699040278200
最も重要で最適な最適化は常にアルゴリズムレベルで行われます:-)それにもかかわらず、行われた作業は役に立たなかったわけではありません-結局、より複雑なパターンでは分析式を使用できない可能性が高く、すでに数値の問題に対処する方法がわかっています。 ちなみに、合計の精度が重要な場合は、小さな用語を大きな合計に追加するときに有効数字が失われないようにするために、追加の対策を講じる必要があります。たとえば、Kaganアルゴリズムを使用します。 あなたが興味を持っていたことを願っています!
よろしく
アナトリー・アレク
シーエフ05/24/2013