まずは単純なものから始めましょう-「さまざまなデータの圧縮の程度」という図です。 ここにあります:
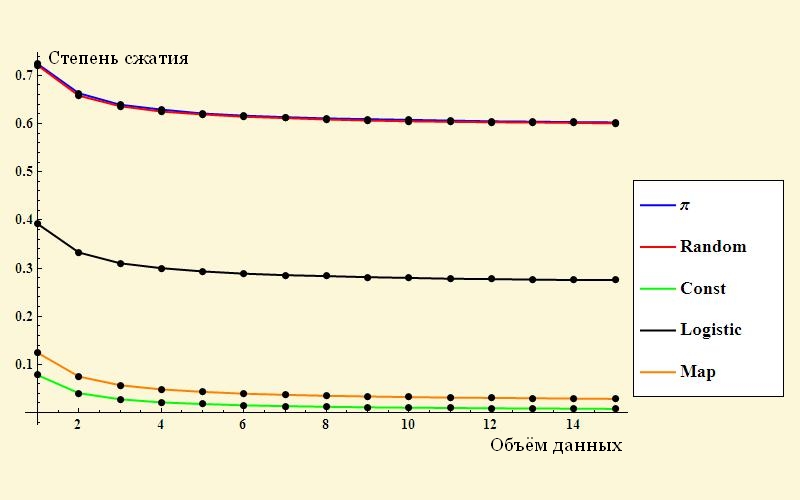
驚くべきことに、数字のランダムなシーケンスは元のボリュームの最大60%までどこかで縮小します。 若い頃、圧縮されたビデオと写真をjpgで圧縮しようとしたことを覚えています。 アーカイブは元のボリュームとほぼ同じ量で取得され、場合によっては数パーセント増加しました! 残念ながら、この記事の著者は、彼がどのように結果を得たのかを詳細に説明しませんでした。 乱数のシーケンスの圧縮率は、10/16 = 0.625の比率と疑わしく類似しています。
私は自分で実験を再現しようとしました。 ランダムな文字を含むファイルを生成し、ヘッダーに記載されているのと同じwinRarで圧縮しました。 結果は次のとおりです。
| ファイルサイズ | アーカイブサイズ |
|---|---|
| 1,000,000バイト | 1002 674バイト |
| 100,000バイト | 100 414バイト |
| 10,000バイト | 10 119バイト |
ご覧のように、ランダムに生成されたデータのシーケンスでは、予想どおり、アーカイブのサイズは元のファイルのサイズより大きくなります。
面白い観察:ファイルを生成するために、Javaで小さなプログラムを作成しました。 実際の生成はチームによって行われました
dataOutputStream.writeChar((int) (Math.random() * 65536));
説明させてください:UnicodeはJavaでサポートされているため、char型は2バイトを使用します。 つまり、0〜65535の数字です。Math.random()は、0〜1の数字を与え、係数を掛けるとランダムな文字が得られます。
おもしろい観察:プログラムは最初、65536の代わりにエラーで記述され、16536でした。その結果、ランダムな文字を含むファイルは元の95%に圧縮されました。 原則として、これは期待される結果でもあります。 式で確認します。
元の記事に記載されている式を使用します。

ファイル内の文字は独立して表示されると考えています。 各位置で16536個の異なるシンボルが可能です。各結果の確率は同じで等しいです。 したがって、金額は次のように計算されます。
H =-(1/16536 * log(1/16536))* 16536 = 14
以下、対数は底2で取得されます。
ただし、アーカイバでは、2バイトごとに65536個すべての値を使用できます。 アーカイブシンボルのエントロピーは
H =-(1/65536 *ログ(1/65536))* 65536 = 16
エントロピーの比率14/16 = 0.875-アーカイブの結果として得られる0.95よりわずかに小さい-も非常に自然な結果です。
元の記事の著者は10進数の数字を生成し、圧縮後、これらの数字は16進数でエンコードされたと思われます。 これにより、アーカイバは10/16の傾向があるデータを圧縮できます。
私がコメントしたい2番目のポイント。 お気づきのとおり、エントロピーの式には、1つまたは別の値を取得する確率などの量があります。 この確率では、すべてがそれほど明白ではないので、別の大きな記事に値するように思えます。 メッセージ内のすべての文字が互いに独立しており、各値がランダムに表示される最も単純なケースを考えました。 この場合、すべてが単純です。各値の出現確率について話すことができます。 ファイルが生成される場合、この確率を設定できます。 ファイルが外部からのものである場合-各文字の出現頻度を測定でき、十分に長いメッセージで、確率が高くなる傾向があります。
ただし、実際には、すべてがそれほど単純ではありません。 テキスト、たとえば、人間の言語でつながった文章を取り上げます。 独立した文字のストリームと見なすと、文字の周波数が異なり、確率を一致させ、ある程度の圧縮を達成できることに気付くことができます。 ただし、自然言語では、いくつかのペアとトリプルの文字はほとんど検出されません。これは、たとえば有名なPuntoSwitcherによる作業の基礎です。 つまり 現在の文字が表示される確率は、その前の文字によって異なります。 これにより、不確実性が減少し、さらに大きな圧縮が実現します。 先に進むことができます:テキストは単語で構成されています。 テキストの著者の語彙は、おそらく4096ワードを超えないため、1ワードあたり12ビットになります。 ここでは、約8のケースまたは活用のために3ビットを追加する必要があります(合計15ビット)。 ロシア語の中間語は6文字で構成されています-ASCIIでは48ビット、Unicodeでは96ビットです。 ちなみに、いくつかの単語は他の単語よりも一般的であり、ケースと同じです-つまり、単語あたりの平均ビット数はさらに少なくなります(まれな単語は長いビットシーケンスでエンコードされ、頻繁なものは短いビットでエンコードされます)。
しかし、それだけではありません。 文のレベルに進むことができます-これにより、どの単語が前の単語に続く可能性が高いかを予測し、メッセージのエントロピーをさらに減らすことができます。
これらの困難はすべて、自然なテキストにのみ特徴的であると考える必要はありません。 私がコメントしている記事で、著者はPiの一連の文字を絞りました。 このシーケンスには単一のランダムな文字はありません。非常にインテリジェントなアーカイバーはこれを認識できます。 この場合、Piの任意の数の文字のアーカイブは、たとえば次のようなエントリを表します。
[数字Piの文字を計算する式] [文字数]
ご覧のとおり、このレコードの長さは元のシーケンスの長さに対して対数的に増加します(999文字をエンコードするには式を記述する必要があります+ 10進数3桁、9999文字をエンコードするには10進数が1桁増えます。 「アーカイブ」の長さを元のシーケンスの長さで割って、圧縮率を取得し、文字ごとのエントロピーを推定します。 この比率は、非ランダムな初期データの場合のように、初期シーケンスの長さが長くなるとゼロになる傾向があります。 はい、そのようなアーカイブを解凍するには、いくつかのコンピューティングリソースが必要になりますが、通常のアーカイブもそれ自体では解凍されません。
上記のすべては、エントロピーを計算するための式に反論するものではなく、単に確率を示す文字pの後ろに隠れることのできるトリックを示しています。