しかし、問題を裏返し、最小限のコード行から可能な限り大きなサイズの実行可能ファイルを取得してみましょう。
結果はそれほど印象的ではありませんでした。60行のコードのうち53Mbしか得られませんでした。 そして、テストされた3つのコンパイラーのうちの1つのみで、数時間のコンパイルのコストがかかります。 14MBのボリュームの最大ボリューム/ライン比は2.3MB /ラインです。
どのように、そしてなぜそれが起こったのか。
資源
4GBのメモリを搭載したラップトップ1台、Intel®Core(TM)i3-2330M CPU @ 2.20GHzプロセッサー、
Linux OS 3.7.3-101.fc17.x86_64
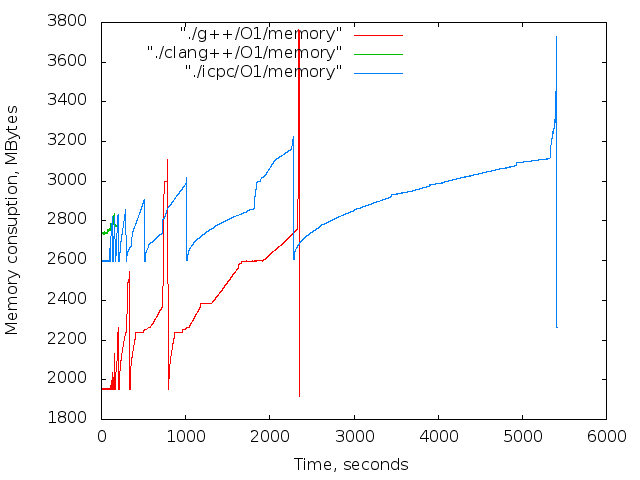
無効化されたスワップパーティション。
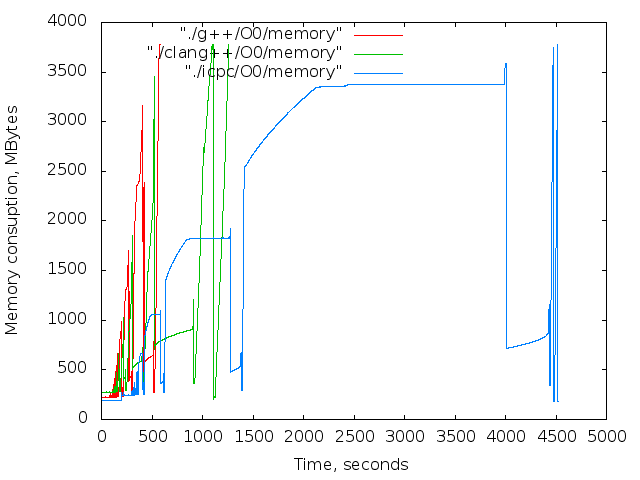
フォークの爆弾が投稿タイトルに登場したのと同じ理由で、スワップを無効にする必要がありました。 タスクのボリュームが十分に大きいため、コンパイラはすべてのメモリを消費し、ディスクとの積極的な交換を開始しました。これにより、マシンがしっかりと永続的にハングしました。
コンパイラーのバージョン:
- g ++(GCC)4.7.2 20120921(Red Hat 4.7.2-2)
- インテル®C ++インテル®64、バージョン13.1.1.163ビルド20130313で実行されるアプリケーション用のインテル®64コンパイラーXE
- clangバージョン3.3(トランク179304)
長い配列
最も簡単な方法は、コンパイル段階の配列とその上の文字列関数を整理することです。 このように:template<long n> inline void nop(){nop<n-1>();asm("nop"); } template<> inline void nop<0>() {asm("nop");} int main(int argc, char ** argv) { nop<LVL>(); return 0; }
その結果、main()関数は空の
シーケンスnopのサイズは、再帰の深さによって理論的に決定されます。 g ++マナは、c ++ 11の最大深さが17および1024であることを示しています。
マナからの引用
標準には特定の数値が見つかりませんでした。 再帰の最大の深さが実装によって決定されるという点だけが見つかりました。
-ftemplate-depth = n
テンプレートクラスの最大インスタンス化の深さをnに設定します。 テンプレートのインスタンス化の深さの制限が必要です
テンプレートクラスのインスタンス化中に無限の再帰を検出します。 ANSI / ISO C ++準拠プログラムは、
17より大きい最大深さ(C ++ 11では1024に変更)。 デフォルト値は900です。これは、コンパイラが不足する可能性があるためです。
状況によっては、1024に達する前にスタックスペース
テンプレートクラスの最大インスタンス化の深さをnに設定します。 テンプレートのインスタンス化の深さの制限が必要です
テンプレートクラスのインスタンス化中に無限の再帰を検出します。 ANSI / ISO C ++準拠プログラムは、
17より大きい最大深さ(C ++ 11では1024に変更)。 デフォルト値は900です。これは、コンパイラが不足する可能性があるためです。
状況によっては、1024に達する前にスタックスペース
4.7.1.14 for C ++ 03
4.7.1.15 for C ++ 11
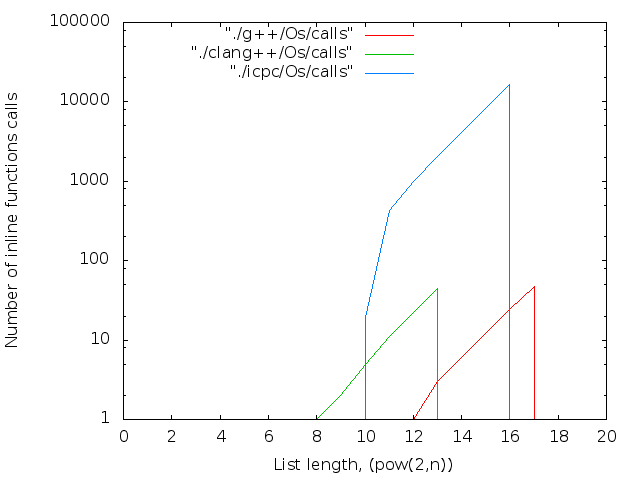
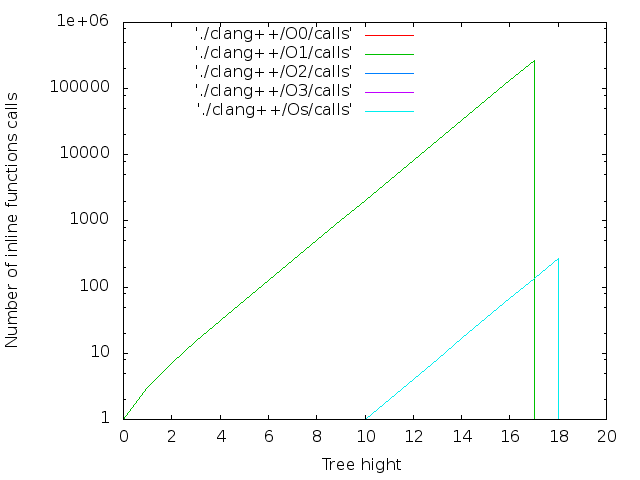
これは経験により確認されました。 十分な大きさのLVLの場合、コンパイラーがクラッシュしました。 g ++やicpcが2 17に達するのとは異なり、2 13でクラッシュしたclang ++に驚いた。
アセンブリは、チームによって実行されました。
clang++ -DLVL=$(( 2**$n)) -o list$n ./list.cc -ftemplate-depth=3000000 -O$x g++ -DLVL=$(( 2**$n)) -o list$n ./list.cc -ftemplate-depth=3000000 -O$x icpc -DLVL=$(( 2**$n)) -o list$n ./list.cc -O$x
内に ビルドスクリプト
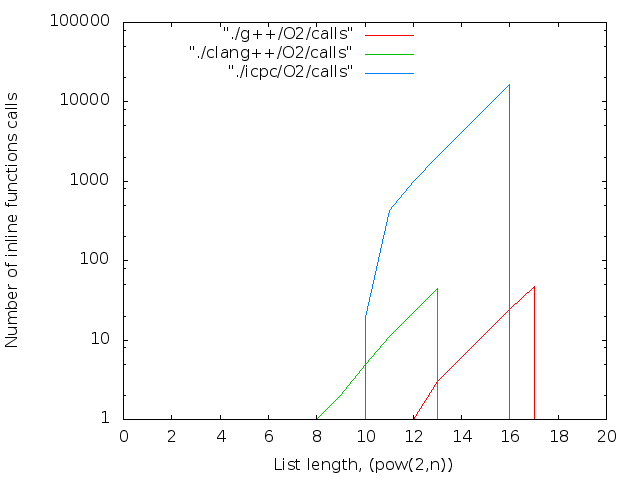
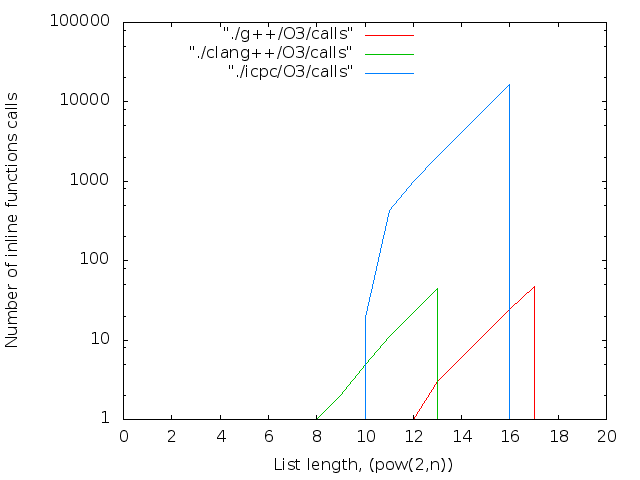
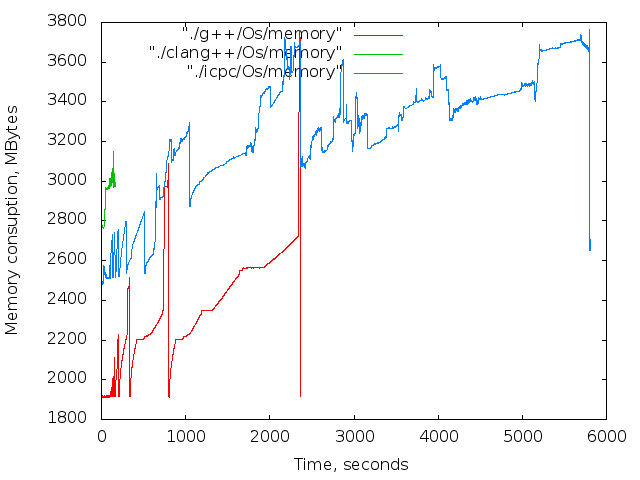
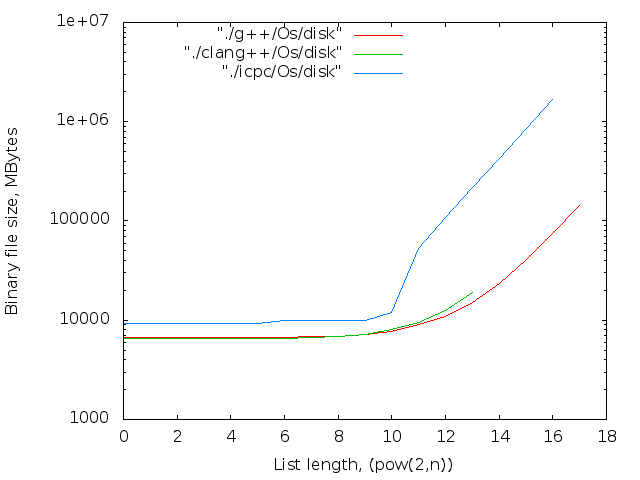
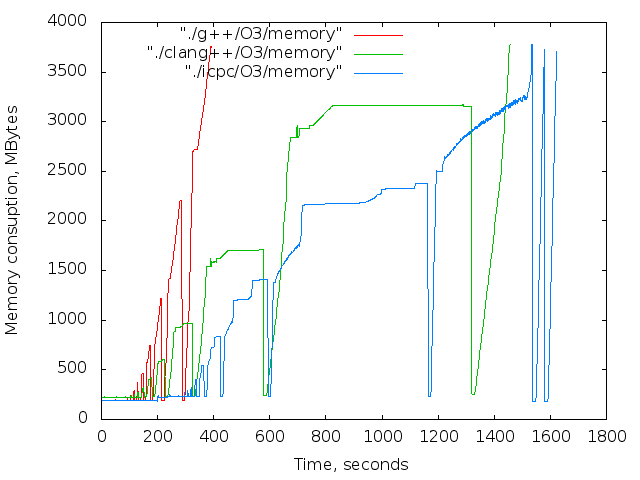
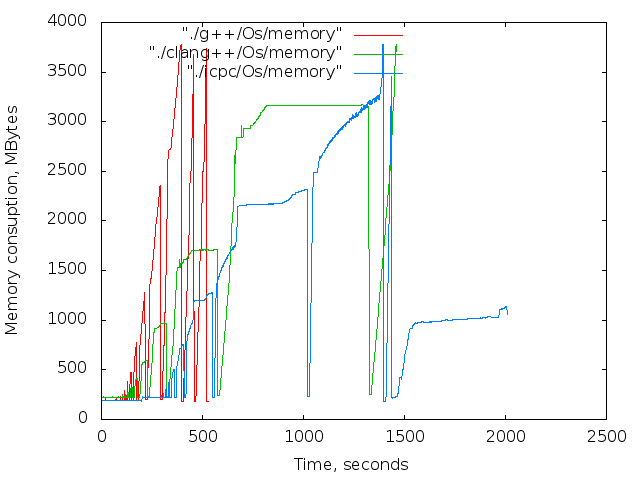
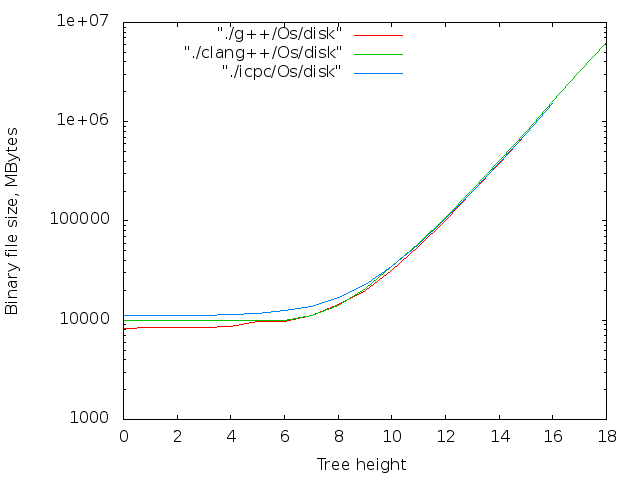
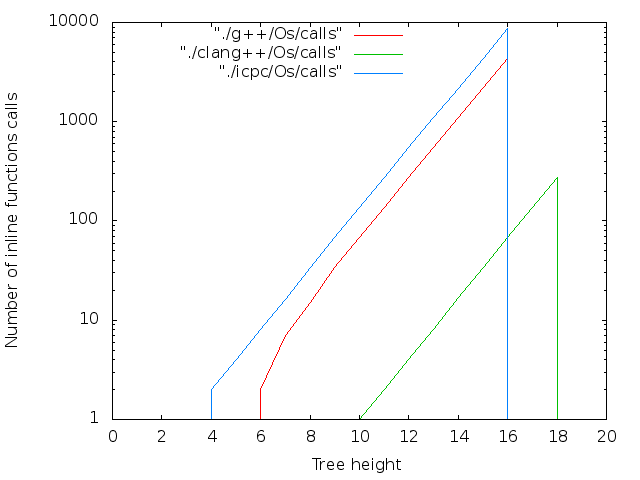
バイナリは、長期間にわたって連続的に収集されました。 各コンパイラ、最適化の各レベル。 アセンブリ結果はグラフに表示されます。 4つの画像列:
#/bin/bash MIN=0 MAX=19 for i in 2; do mkdir -p attempt$i cd attempt$i for CXX in clang++ g++ icpc do mkdir -p $CXX cd $CXX for O in O0 O1 O2 O3 Os do mkdir -p $O cd $O (while :;do free -m |grep Mem|awk '{print $3}' >> ./memory;sleep 1;done)& TIME=$! for i in $(seq $MIN $MAX) do # CMD="$CXX -$O ../../../fbomb.cc -DLVL=$i -o fbomb$i" #-save-temps=obj " CMD="$CXX -$O ../../../list.cc -DLVL=$(( 2 ** $i)) -o list$i -ftemplate-depth=3000000" #-save-temps=obj " echo $CMD $CMD sleep 5 sleep 5 done kill -9 $TIME cd .. done cd .. done cd .. done
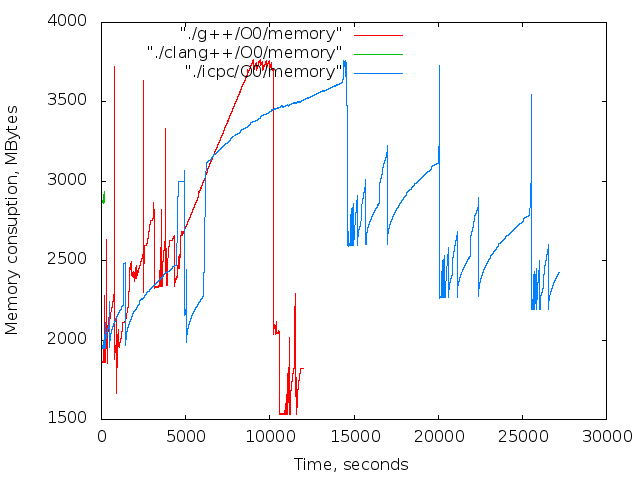
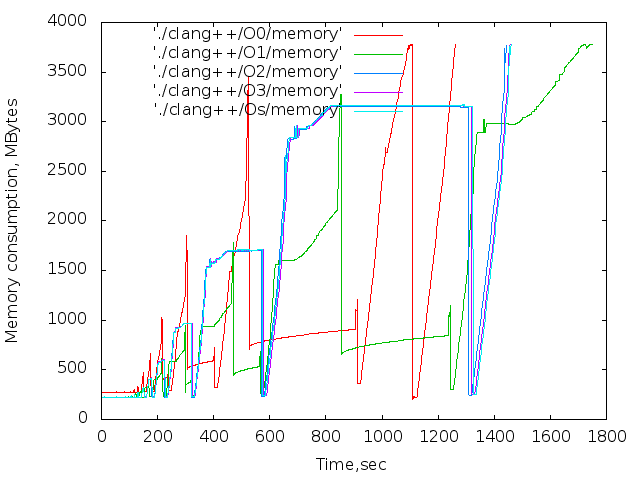
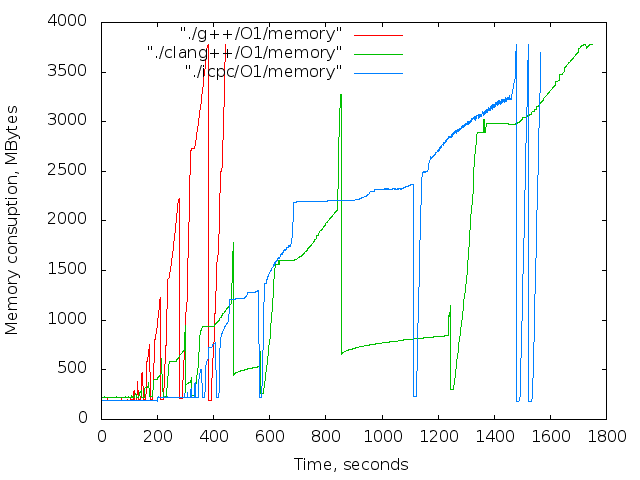
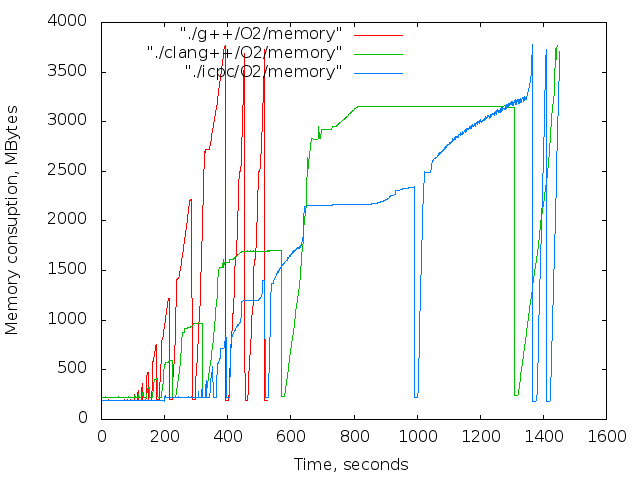
- 使用済みメモリの時間依存。 これらのグラフは参照専用です。 コンパイル中、Xサーバーとブラウザーは機能しましたが、主な傾向は明らかです。
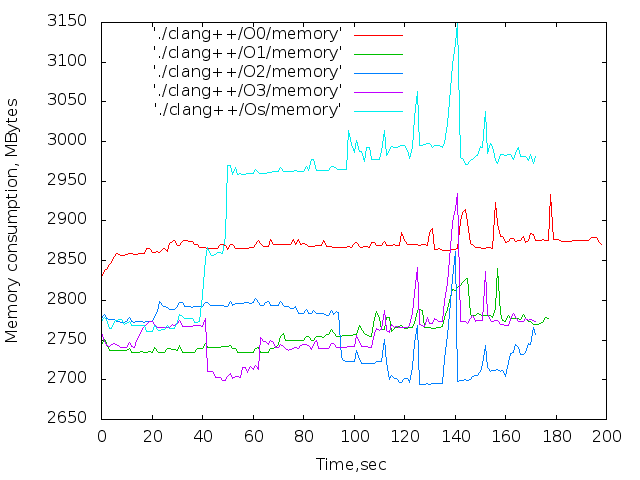
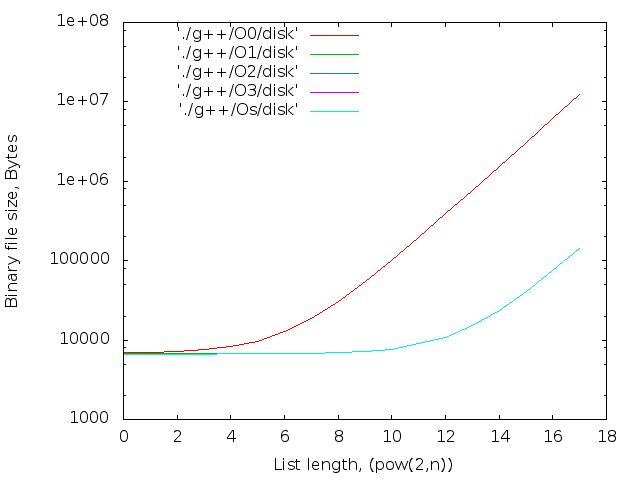
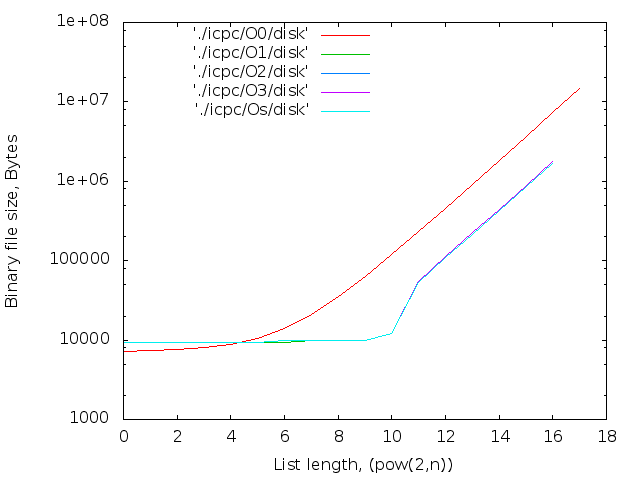
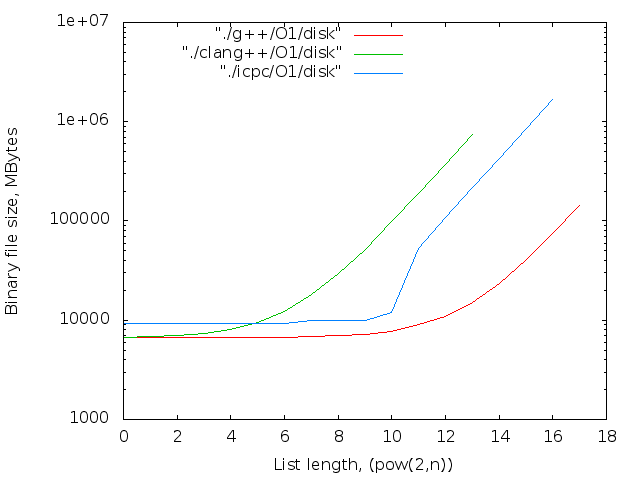
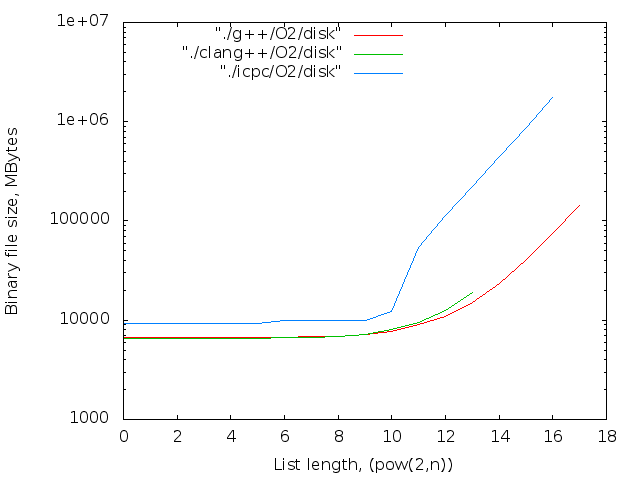
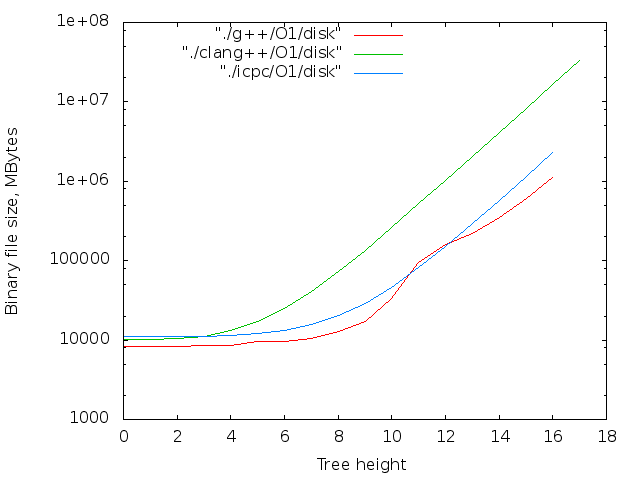
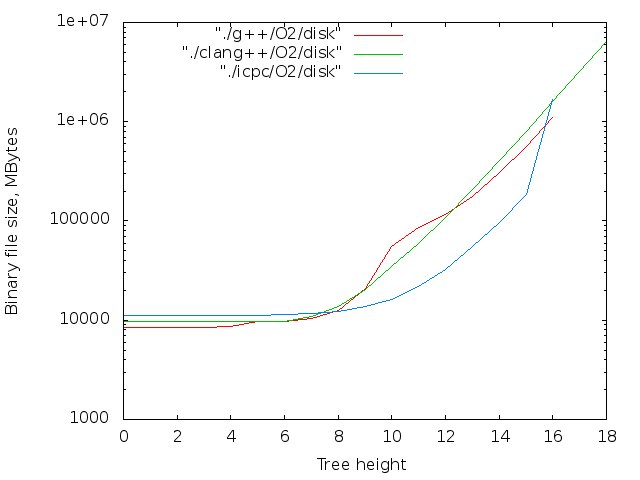
- バイナリファイルのサイズ。 判明した最大値-14MB
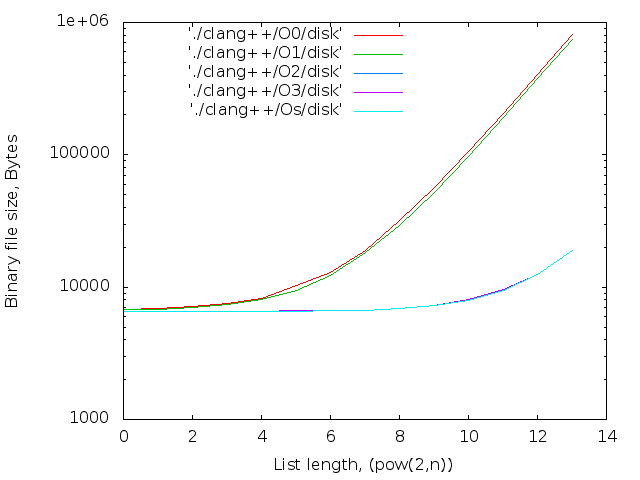
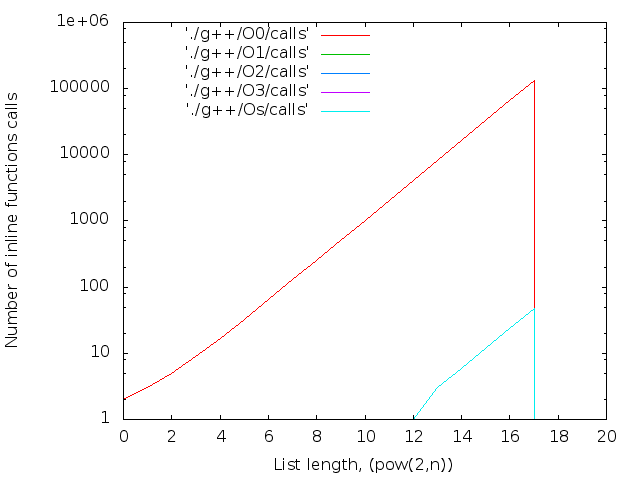
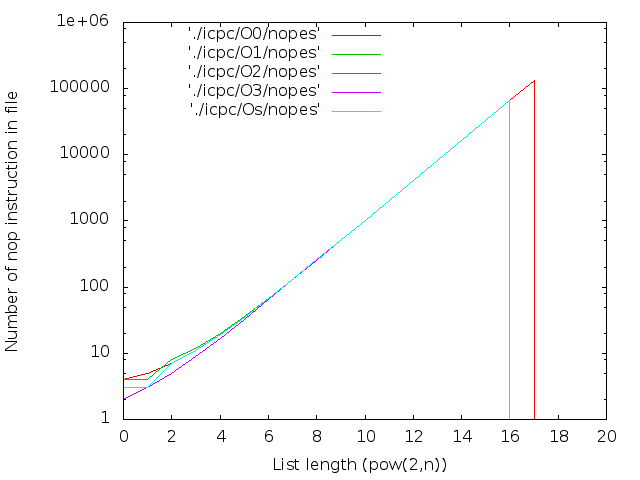
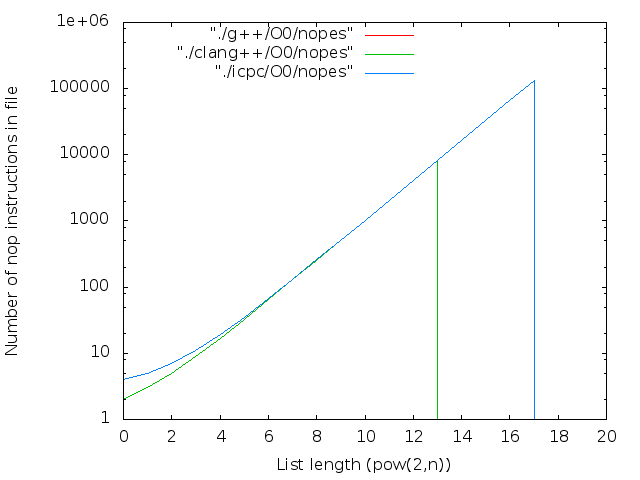
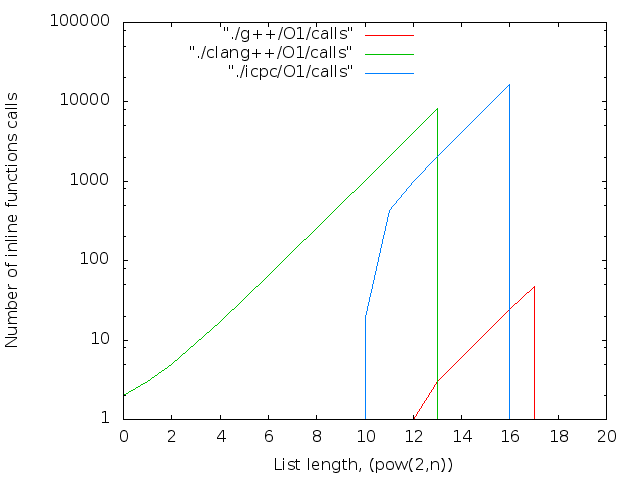
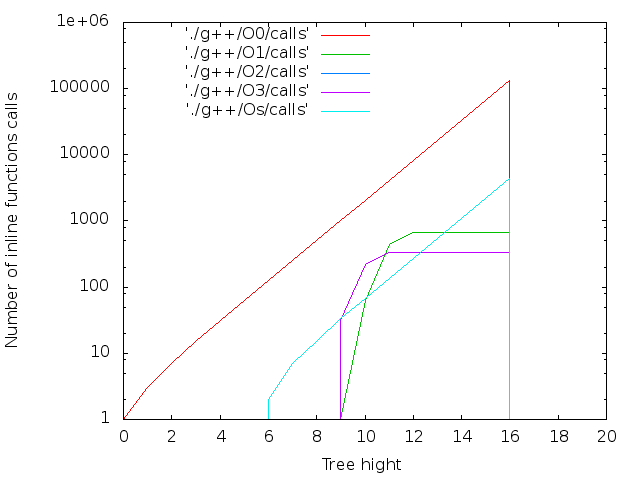
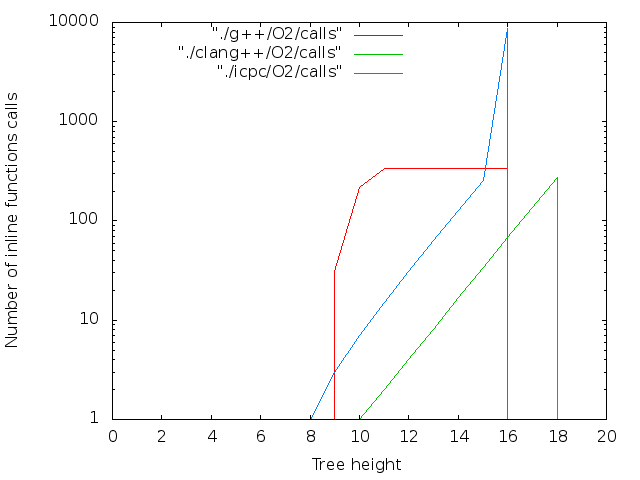
- 文字数。 inlineキーワードはコンパイラへの単なる推奨事項であるため、大きなNの場合、Nopsは通常の関数にグループ化されます。 それらは次のように計算されます。
nm --demangle ./list$i|grep nop|wc -l
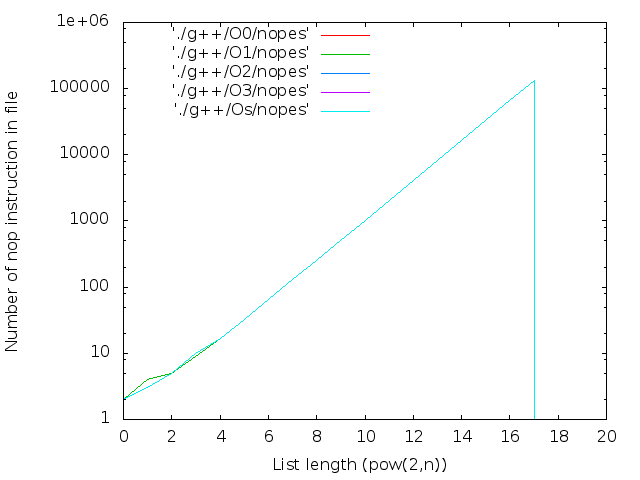
- 正直なnopsの数。 逆アセンブラーから計算:
objdump -d ./list$i|grep 'nop$'|wc -l
画像はクロムでのみ正しく拡大縮小するようです。
他のブラウザの場合
スクリーンショット 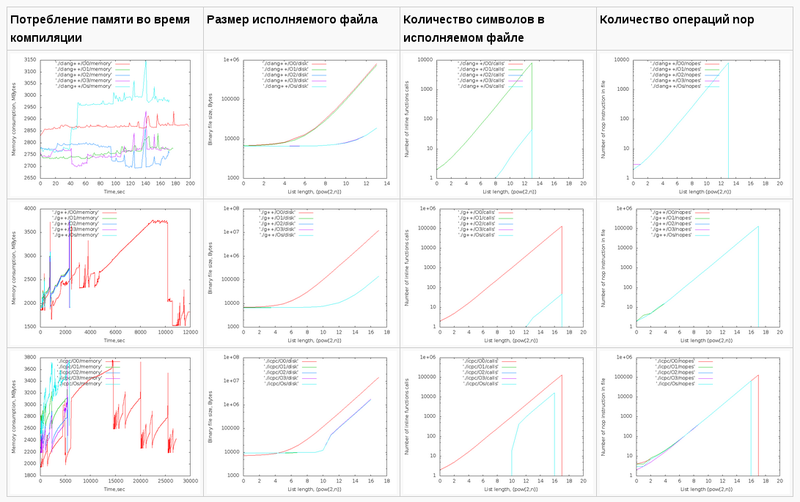
すべての画像を含むアーカイブへのリンク
写真
2 17個のicpcコンパイラの最大ファイルサイズは14MBです。 g ++の場合-12 MB。 両方ともO0。 最適化レベルO0はインライン置換を実行しないため、nop <long>文字の数はnop操作の数と一致します。
同じコンパイラーの異なる最適化レベルの比較
| コンパイル時のメモリ消費
| 実行可能ファイルサイズ
| 実行可能ファイルの文字数
| 操作数nop
|
|---|---|---|---|
| 
| 
| 
|
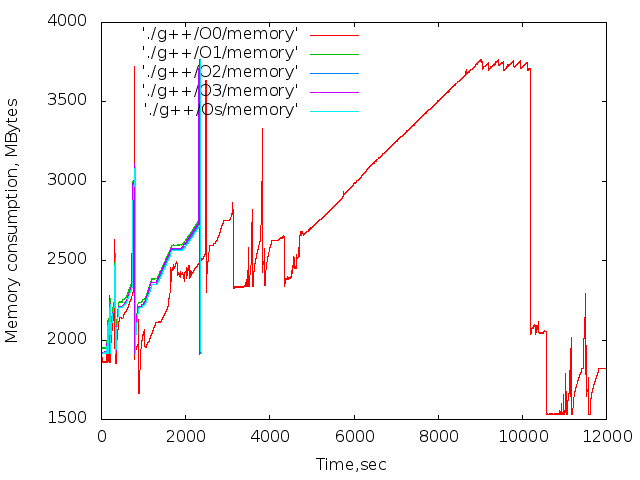
| 
| 
| 
|

| 
| 
| 
|
さまざまな最適化レベルでのさまざまなコンパイラの比較
| コンパイル時のメモリ消費
| 実行可能ファイルサイズ
| 実行可能ファイルの文字数
| 操作数nop
|
|---|---|---|---|
| 
| 
| 
|
| 
| 
| 
|

| 
| 
| 
|

| 
| 
| 
|
| 
| 
| 
|
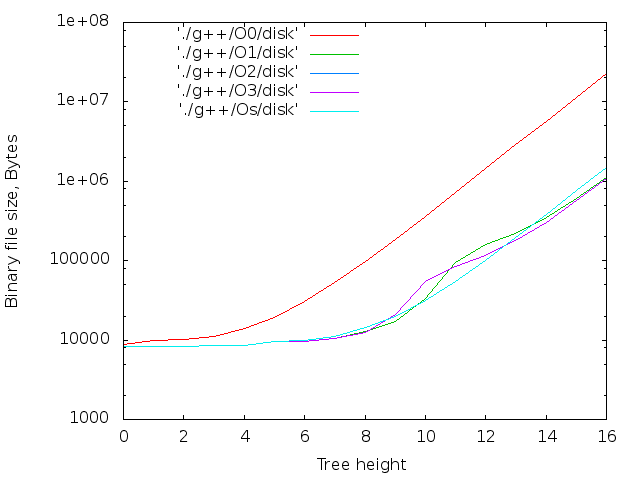
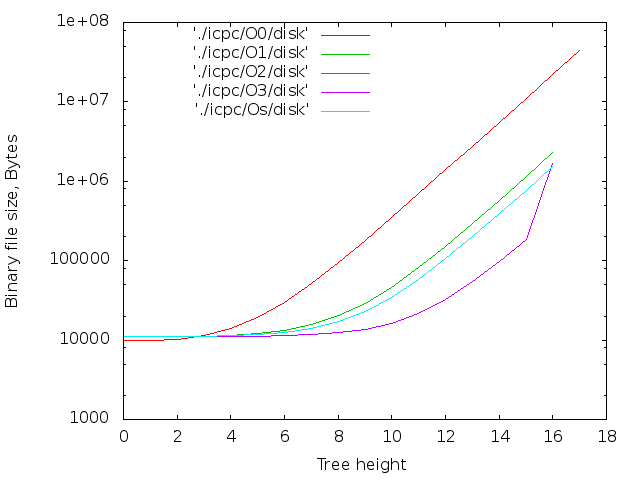
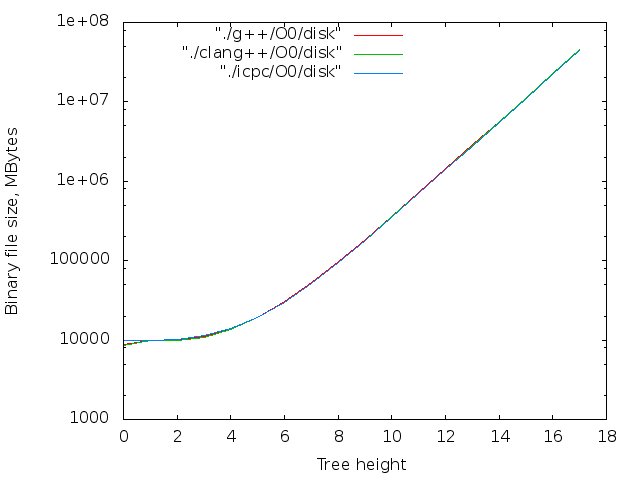
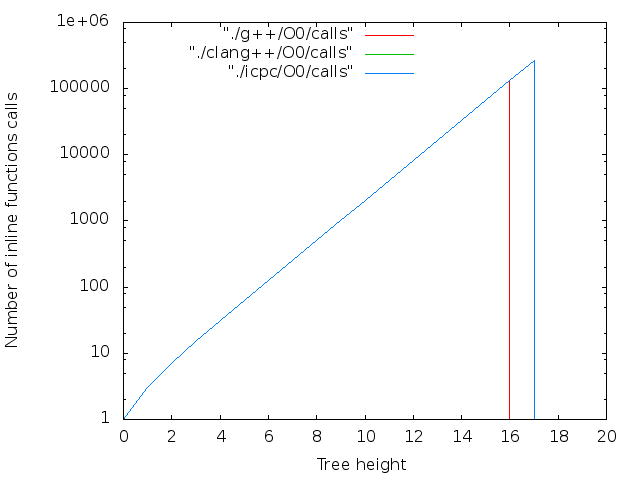
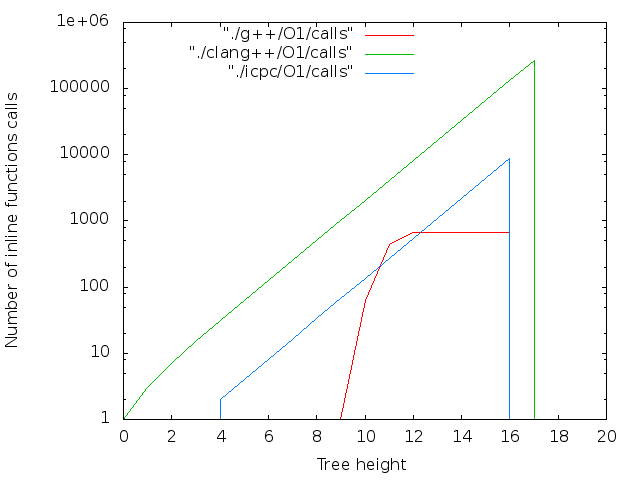
背の高い木
線形データ構造の場合、生成されるファイルのサイズは、少なくともデフォルトの最大再帰深度(clang ++の場合は256、g ++の場合は900)に制限されます。 それを回避するには、ツリーを作成してみてください。 コンパイルステージツリーの理論上の最大の深さは(sizeof(long)-1)== 63です。また、2 64バイトがディスクをオーバーフローさせます。 実際的な制限ははるかに少ないです。ツリーを使用して、再帰の最大深度を超えません。
ソースコードは19行で、次のようになります。
#ifndef LVL # define LVL 3 #endif long x = 0; template<int N=LVL, long I=0> struct foo{ inline static double bar(double m) {x++;return foo<N-1,I>::bar(m) + foo<N-1,((1<<(LVL-N))|I)>::bar(m) + I;}; }; template<long I> struct foo<0,I>{ inline static double bar(double m) {x++; return m;} }; #include <iostream> int main(int argc, char **argv){ double ret = foo<>::bar(argc); std::cout << x << " " << ret << std::endl; return int(ret); }
結果はツリーであり、その各ノードには独自のタイプがあります。 各タイプは、数字のペアで特徴付けられます。
- N-レベル番号。
- Iはレベルのノード番号です。
1つのレベル内の各ノードには、0からNまでの番号が付けられます。
ここではnopを台無しにせず、追加を使用しました。 グローバルlong x-正しいアセンブリを制御するために使用されました。 その結果、2 LVL + 1が返されます。
アセンブリは、チームによって実行されました。
clang++ -DLVL=$n -o fbomb$n ./fbomb.cc -O$x g++ -DLVL=$n -o fbomb$n ./fbomb.cc -O$x icpc -DLVL=$n -o fbomb$n ./fbomb.cc -O$x
上記と同じシナリオで。
clang ++の最大LVLは18でした。 g ++およびicpc-16の場合、オプション--std = c ++ 11が指定されたかどうかに関係なく。 コンパイラがメモリを使い果たしました。
画像はクロムでのみ正しく拡大縮小するようです。
他のブラウザの場合
スクリーンショット 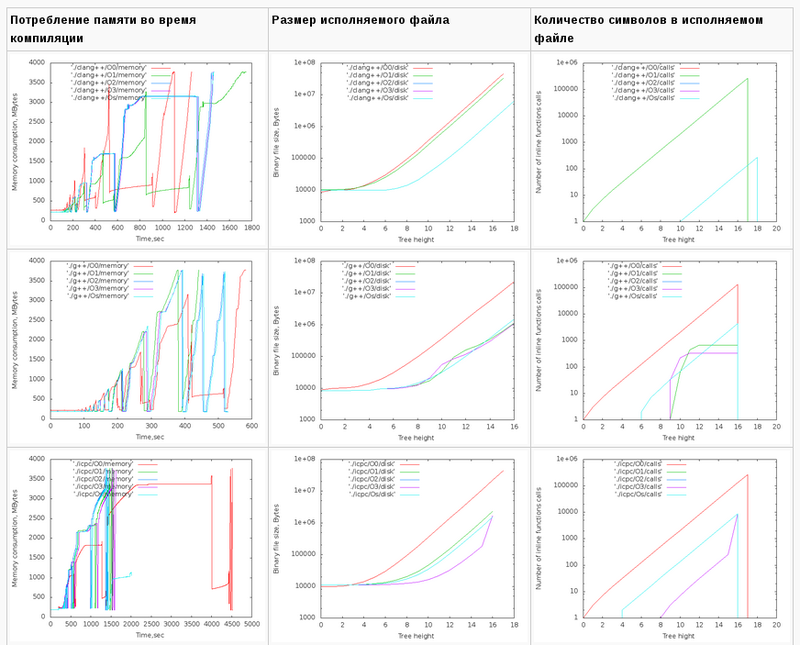
すべての画像を含むアーカイブへのリンク
木の写真
| コンパイル時のメモリ消費
| 実行可能ファイルサイズ
| 実行可能ファイルの文字数
|
|---|---|---|
| 
| 
|

| 
| 
|

| 
| 
|
| コンパイル時のメモリ消費
| 実行可能ファイルサイズ
| 実行可能ファイルの文字数
|
|---|---|---|
| 
| 
|
| 
| 
|
| 
| 
|
| 
| 
|
| 
| 
|
最大ファイルサイズ:
- icpc -O0 -DLVL = 17の場合は43 MB。
- clang ++の場合は42MB -O0 -DLVL = 17;
- g ++ -O0 -DLVL = 16の場合、22MB
明示的なインスタンス化
43MB-それほど小さくはありませんが、一定量のRAMでファイルをさらに大きくすることは可能ですか? 可能になりましたが、3つのコンパイラーのうちの1つだけ-icpc。 このためには、外部テンプレートと明示的なインスタンス生成を使用する必要があります。テンプレートのすべてのパラメーターがその説明に示されるように、ソースコードを少し変更します。 ソースコードを3つのファイルに分割します-テンプレートの説明、メイン関数、サブツリーの部分的なインスタンス化:
fbomb.hh
extern long x; template<int L=LVL, int N=L, long I=0> struct foo{ inline static double bar(double m) {x++;return foo<L,N-1,I>::bar(m) + foo<L,N-1,((1<<(LN))|I)>::bar(m) + I;}; }; template<int L, long I> struct foo<L,0,I>{ inline static double bar(double m) {x++; return m;} };
main.cc
#include "fbomb.hh" //for i in $(seq 0 13);do echo "extern template struct foo<LVL,L,$i>;";done #define L (LVL-5) extern template struct foo<LVL,L,0>; extern template struct foo<LVL,L,1>; extern template struct foo<LVL,L,2>; extern template struct foo<LVL,L,3>; ... extern template struct foo<LVL,L,30>; extern template struct foo<LVL,L,31>; #include <iostream> long x = 0; int main(int argc, char **argv){ double ret = foo<LVL>::bar(argc); std::cout << x << " " << ret << std::endl; return int(ret); }
part.cc
標準のバージョンに関係なく、メモリ不足と完全なインスタンス化により、g ++ -c main.cc -DLVL = 21がクラッシュすることが判明しました。 clang ++についても同じ状況です。 Icpcはmain.ccを1秒未満でコンパイルします。 ただし、サブツリーのコンパイルには4時間以上かかりました。 template class foo<LVL, _L, _I>;
for i in $(seq 0 31);do echo -n "$i:";date; icpc -O2 -c ./part.cc -o part21_16_$io -DLVL=21 -D_L=16 -D_I=$i;sleep 10; done
サブツリーのコンパイル中のメモリ消費 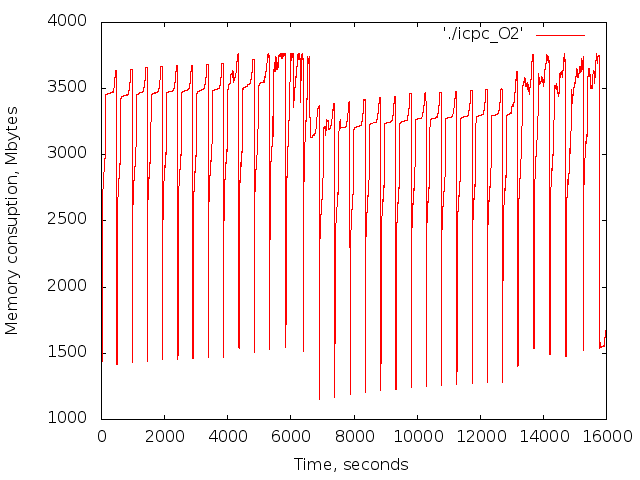
リンクには1分もかかりませんでした。 結果は53MBのファイルです。 このファイルは-O2で作成されました。 -O0はサイズが大きくなります
最初の部分(icpc -O0 list.cc)から配列の最大の比率のボリューム/行数= 2.3MB /行が取得されました
メトリックはもちろん冗談ですが、面白いです。 2.3-発生した最大値。 誰かがより大きな態度をとったかどうかを知りたいです。
私たち全員に幸運を。
Upd :Stripは必要ありませんでしたが、必要です。 数キロバイトあると思いましたが、サイズの割合であり、かなり大きいことが判明しました。 ストリップ後、最大サイズは37MBに低下しました(53から)。 および8.6MB(14個から)。 したがって、比率は1.43MB /行です。