 最初の記事では、Apache Solr検索サーバーをインストールしてDrupal 7で動作するように構成する方法について説明しました。次に、インデックスを構成する方法について説明します。
最初の記事では、Apache Solr検索サーバーをインストールしてDrupal 7で動作するように構成する方法について説明しました。次に、インデックスを構成する方法について説明します。
最初の部分を読んでいない人には、資料をよく理解するために読むことをお勧めします。
- Apache Solrパート1でのDrupal 7検索-基本設定
- Apache SolrでのDrupal 7 Searchパート2-インデックスの調整方法の学習
- Apache SolrでDrupal 7を検索するパート3-カスタムフィールドとオプションをインデックスに追加する方法を学ぶ
- Apache Solrパート4-ファセットフィルターでDrupal 7を検索する
- Apache SolrによるDrupal 7の検索パート5-ファセットフィルターウィジェット
- Apache Solrパート6を使用してDrupal 7で検索する-Apache Solr + Tomcatを構成する
- Apache SolrによるDrupal 7検索パート7-ロシア語の全文検索
search_api_solrモジュールの設定には、サーバーとインデックスという2つの主要なエンティティが表示されます。
インデックス設定では、Apache Solrがサイトのコンテンツにインデックスを付けるためのフィールドと条件を指定できます。 インデックス設定を順番に分析します。
フィールド
まず、フィールドに注意を払う必要があります。 インデックス設定で、Apache Solrがコンテンツのインデックスを作成するフィールドを指定できます。 これを行うには、インデックスを選択し、「フィールド」タブに移動します。 ここで、このページで使用可能なリスト内のインデックス可能なフィールドを選択できます。 すべてのフィールドが一度に使用できるわけではなく、「関連フィールド」要素を使用して追加できる場合があります。 ページの一番下にあります。
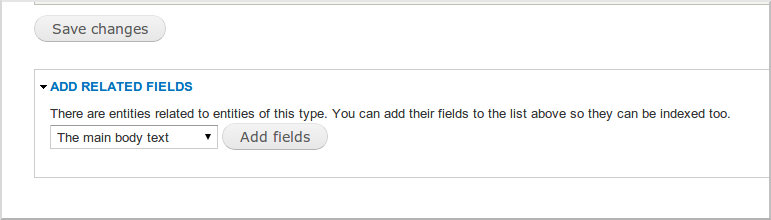
「本文テキスト」フィールドを追加して、インデックス化可能にします。
エンティティ(私の例では、ノード)が他のエンティティへの参照(たとえば、分類法の用語)を持っている場合、分類法のフィールドを含むノードを検索できます。 したがって、関連するエンティティのいくつかのレベルのフィールドをインデックスに追加できます。
選択したフィールドのインデックスの種類を指定できます。 タイプの名前から、それが何のためであるかは明らかです。 フルテキストはフルテキスト検索を意味すると言うことができるだけで、Apache Solrは整数値だけでなく、その部分も検索します。 また、文字列は整数値で検索するために使用されます。 たとえば、見出しの場合は全文を選択するのが理にかなっています。また、本のジャンル(冒険、SF、古典など)の場合は、文字列を選択する方が適切です。
インデックス付けのタイプに加えて、「フィールドウェイト」もあります。 重みを使用して、各フィールドの検索結果の優先度を制御できます。 この場合、重みが大きいほど、フィールドの優先度が高くなります。
必要なフィールドを選択したら、フォームを保存します。 記事のタイトルと本文を選択しました。
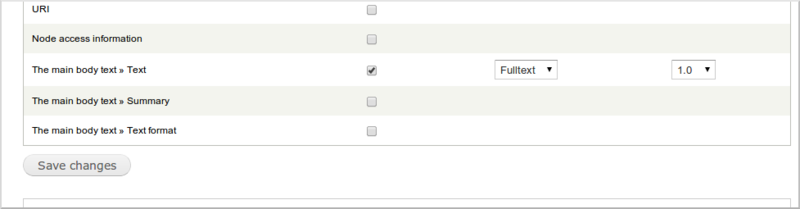
「関連フィールド」を介してフィールドのグループを追加したが、これらのグループで何も選択しなかった場合、これらのグループのフィールドは消え、再度追加する必要があります。
内容
次に、[ワークフロー]タブに移動します。 ここで、コンテンツのインデックス作成ルールを構成できます。 設定の最初のセクションは「データ変更」と呼ばれます。 その中で、ノードのタイプ別にフィルターを追加するか(バンドルフィルター)、インデックスから未公開のノードを除外できます。 バンドルフィルターの場合、デフォルトでは選択されたコンテンツタイプが除外されることに注意してください。 したがって、必要なモードを選択することを忘れないでください(リストされているものを除外するか、逆にリストされているものをインデックス付けしてください)。
2番目のセクションはプロセッサです。 追加のデータ処理を実行できます。 たとえば、Ignore case processorを使用すると、インデックス内で大文字と小文字を区別せずに検索できます。 ほとんどのプロセッサでは、適用するフィールドを選択できます。
必要な設定を選択し、フォームを保存します。 次に、[ステータス]タブに戻り、コンテンツのインデックスを再作成する必要があります。
別の重要なポイント-検索結果を表示するために使用したビューの設定で必要なフィールドによるフィルタリングを有効にする必要があります。 これを行うには、ビュー自体で、検索:全文検索フィルターの設定に移動し、このフィルターが作用するフィールドを選択します。
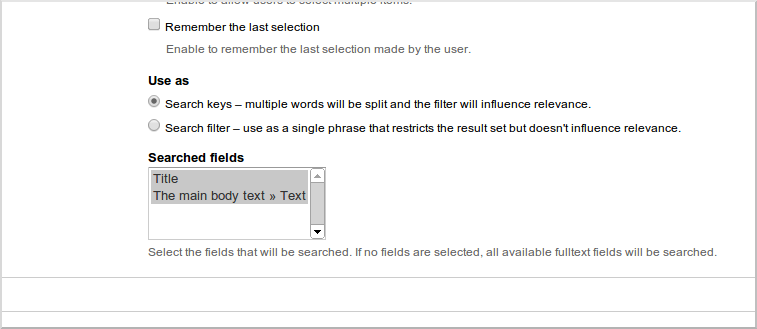
その後、/ search-resultsページ(最初の記事でこのページのプレゼンテーションを設定しました)に移動し、検索結果に感心します。
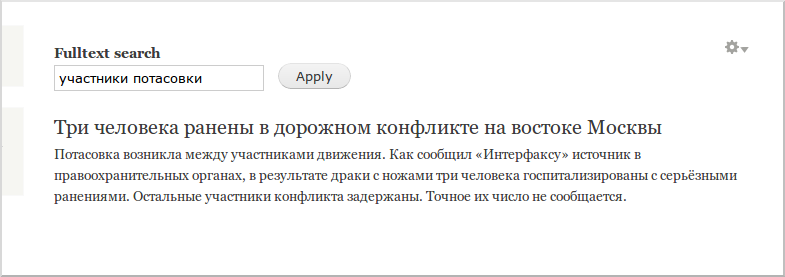
次の記事では、標準のものでは不十分な場合に独自のフィールドとインデックス設定を追加する方法を説明します。