Oleg Gelbukh による最後の記事は、OpenStackの継続性のさまざまな側面の概要を提供しました。 すべてのOpenStackコンポーネントは中断されないように設計されていますが、プラットフォームはデータベースやメッセージングシステムなどの外部リソースも使用します。 そして、稼働時間のためにこれらの外部リソースを展開することはユーザーの関心事です。
OpenStackのすべてのステートフルリソースはメッセージングシステムとデータベースを使用し、他のすべてのコンポーネントは状態情報を保存しないことに注意してください(Glanceを除く)。 データベースとメッセージングシステムは、OpenStackプラットフォームの鍵です。 キュー管理システムではいくつかのコンポーネントがメッセージを交換できますが、データベースにはクラスターの状態が保存されます。 これらのシステムは両方とも、仮想オブジェクトのリストを表示するときと新しい仮想マシンを作成するときの両方で、各ユーザーリクエストに参加します。
デフォルトでは、RabbitMQがメッセージングに使用され、MySQLがデフォルトのデータベースです。 信頼性の高いソリューションは業界で知られており、私たちの経験では、大規模なインストールでも十分に拡張できます。 理論的には、SQLAlchemyをサポートするデータベースが適していますが、ほとんどのユーザーはデフォルトのデータベースを使用します。 メッセージング用にRabbitMQの代替を見つけるのは困難ですが、OpenStack用のZeroMQドライバーを使用するものもあります。
OpenStack Messagingとデータベースの仕組み
OpenStackでデータベースとメッセージングシステムがどのように連携するかを見てみましょう。 まず、最も一般的なユーザーリクエストである仮想マシンのインスタンスの作成時のデータフローについて説明します。
ユーザーは、OpenStackにリクエストを送信し、nova-apiコンポーネントと対話します。 Nova-apiは、nova-compute APIからcreate_instance関数を呼び出すことにより、リクエストを処理してインスタンスを作成します。 この関数は次のことを行います。
-ユーザーが入力したデータを確認します(たとえば、要求されたVMイメージ、種類、ネットワークが存在することを確認します)。 定義されていない場合は、デフォルト値(たとえば、さまざまなデフォルトネットワーク)を取得しようとします。
-ユーザー制限の順守の要求を確認します。
-その後、上記のチェックにより肯定的な結果が得られ、データベースにインスタンスに関するレコードが作成されます(create_db_entry_for_new_instance関数)。
-関数_schedule_run_instanceを呼び出します。これは、AMQPプロトコルを使用して、メッセージキューを介してnova-schedulerコンポーネントにユーザー要求を渡します。 リクエストの本文にはインスタンスパラメータが含まれます。
request_spec = {
'image':jsonutils.to_primitive(image)、
'instance_properties':base_options、
'instance_type':instance_type、
'num_instances':num_instances、
'block_device_mapping':block_device_mapping、
'security_group':security_group、
}
_schedule_run_instance関数は、scheduler_rpcapi.run_instance関数呼び出しでAMQPメッセージを送信することにより完了します。
これで、スケジューラーが作業に入ります。 ノードの仕様が記載されたメッセージを受信し、そのメッセージとその計画ポリシーに基づいて、インスタンスの作成に適したノードを見つけようとします。 これは、この操作中のnova-schedulerログファイルからの抜粋です(ここではFilterSchedulerが使用されます)。
(pid = 15493)からのUbuntuのホストフィルターパスpass_filters /opt/stack/nova/nova/scheduler/host_manager.py:163
フィルター[ホスト 'ubuntu':free_ram_mb:1501 free_disk_mb:5120] from(pid = 15493)_schedule /opt/stack/nova/nova/scheduler/filter_scheduler.py:199
彼は、計量機能を使用して、最低コストのノードを選択します(ノードは1つしかないため、この場合、計量操作は何も変更しません)。
Weighted WeightedHostホスト:ubuntu from(pid = 15493)_schedule /opt/stack/nova/nova/scheduler/filter_scheduler.py:209
インスタンスを実行する必要がある計算ノードが決定されると、スケジューラーはcast_to_compute_host関数を呼び出します。
-novaデータベース内のインスタンスのノードレコードを更新します(node =インスタンスが作成される計算ノード)。
-AMQPを介してこの特定のノードのnova-computeサービスにメッセージを送信して、インスタンスを開始します。 メッセージには、実行するインスタンスのUUIDと次に実行するアクション、つまりrun_instanceが含まれます。
応答として、選択したノードのnova-computeサービスは_run_instanceメソッドを呼び出し、データベースからインスタンスパラメーターを(転送されたUUIDに基づいて)受信し、適切なパラメーターでインスタンスを開始します。 インスタンスのセットアップ中、nova-computeはAMQPプロトコルを介してnova-networkサービスとも通信し、ネットワークの相互作用を構成します(IPアドレスの割り当てとDHCPサーバーの構成を含む)。 作成プロセスのさまざまな段階での仮想マシンの状態は、_instance_update関数を使用してnovaデータベースに記録されます。
ご覧のとおり、AMQPプロトコルはOpenStackのさまざまなコンポーネント間の通信に使用されます。 また、データベースは数回更新され、仮想マシン(VM)の初期化ステータスが表示されます。 したがって、次のコンポーネントのいずれかを失うと、OpenStackクラスターの主な機能に大きく違反します。
-RabbitMQが失われると、ユーザータスクを実行できなくなります。 また、一部のリソース(デプロイ可能なVMなど)は分解されたままになります。
-データベースを失うと、さらに壊滅的な結果につながります。すべてのインスタンスは動作しますが、誰が属しているか、どのノードに到達したか、またはIPアドレスが何であるかを判別できません。 クラウドで起動できるVMの数(おそらく数千)を考慮すると、この状況は修正できません。
データベース向けHAソリューション
データを慎重にバックアップおよび複製することにより、データベースのクラッシュを防ぐことができます。 MySQLの場合、MySQL Cluster(MySQLクラスタリングの「公式」セット)、MMM(複数のメインレプリカを備えたレプリケーション管理ツール)、PerconaのXtraDBなど、詳細な説明を含む多くのソリューションがあります。
MySQL Cluster
MySQLクラスターは、NDB(ネットワークデータベース)と呼ばれる特別なストレージエンジンに基づいています。 エンジンは、「データノード」と呼ばれるサーバーのクラスターであり、「コントロールノード」によって制御されます。 データはセグメント化され、データノード間で複製され、各データユニットには少なくとも2つのレプリカが存在します。 すべてのレプリカは、必ず異なるデータノードに配置されます。 データノードの上部で、サーバー部分にNDBストレージを備えたMySQLサーバーファームが起動しました。 各mysqldプロセスには読み取り/書き込み機能があり、負荷を分散して効率と継続性を確保できます。
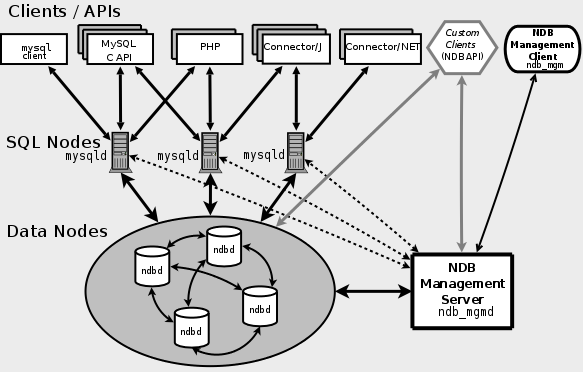
MySQLクラスターは、 同期レプリケーションを保証します。これは、従来のレプリケーションメカニズムの明らかな欠点です。 他のストレージエンジンと比較して、いくつかの制限があります(このリンクで概要を確認できます)。
XtraDBクラスター
これは、業界で認められているPerconaのソリューションです。 XtraDBクラスターはノードのセットで構成され、各ノードは、レプリケーションをサポートするアドオンのセットを使用してPercona XtraDBのインスタンスを実行します。 アドオンには、InnoDBストレージエンジンとデータを交換するための一連の手順が含まれており、 WSREP仕様に準拠した下位レベルでレプリケーションシステムを作成できます。
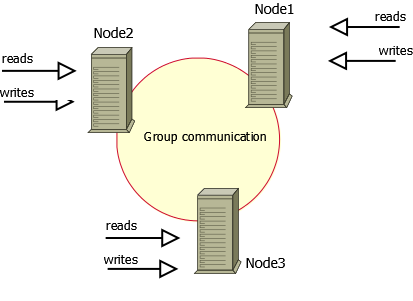
Perconaのアドオンを含むmysqldバージョンが各クラスターノードで実行されています。 それぞれには、データの完全なコピーも含まれています。 各ノードは読み取りおよび書き込み操作を許可します。 MySQL Clusterと同様に、XtraDB Clusterにはここで説明するいくつかの制限があります 。
MMM
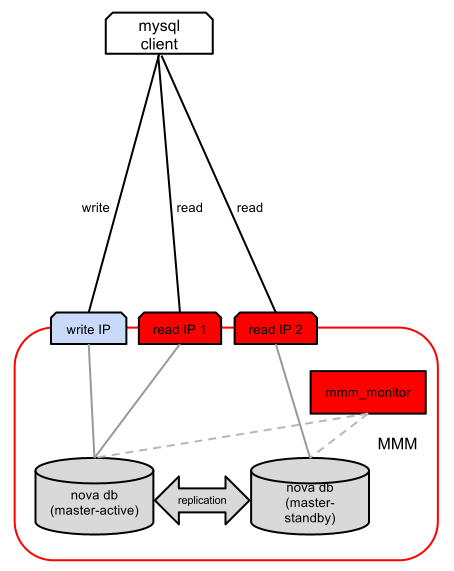
MultiMaster Replication Managerは、 レプリケーションに従来のマスタースレーブメカニズムを使用します。 これは、一連の従属レプリカを備えた少なくとも2つのメインレプリカと、専用の監視ノードを備えたMySQLサーバーのセットに基づいて動作します。 ホストのこのセットの上に、MMMが可用性に応じてホストからホストに動的に移動できるようにIPアドレスのプールが構成されます。 これらのアドレスには2つのタイプがあります。
-「記録」:クライアントは、このIPアドレスに接続することでデータベースに書き込むことができます(クラスター全体では、記録ノードアドレスは1つしか存在できません)。
-「読み取り」:クライアントは、このIPアドレスに接続することでデータベースを読み取ることができます(読み取りをスケーリングするために複数の読み取りノードがある場合があります)。
監視ノードは、MySQLサーバーの可用性をチェックし、サーバーに障害が発生した場合の「記録」および「読み取り」IPアドレスの転送を含めます。 一連のチェックは比較的単純です。これには、ネットワークの可用性のチェック、ホスト上のmysqldの存在、レプリケーションブランチの存在、およびレプリケーションログのサイズのチェックが含まれます。 「読み取り」IPアドレス間の読み取りの負荷分散は、ユーザーによって行われます(HAProxyまたはDNSラウンドロビンなどを使用して行うことができます)。
MMMは従来の非同期レプリケーションを使用します。 これは、障害発生時に、レプリカマスターがマスターの背後にある可能性が常にあることを意味します。 現在、1つのレプリケーションブランチが使用されています。これは、特に長い書き込み要求が実行される場合に、大量のトランザクションがあるマルチコアの世界では十分でない場合があります。 これらの考慮事項は、バイナリログ (binlog)とHAの継続性を最適化するための一連の関数を実装するMySQLの将来のバージョンではなくなりました。
MySQLの稼働時間に関するOpenStackのトレーニング資料に関して、Alessandro Tagliapietraは、マスタースレーブレプリケーションとPerconaのPacemakerエージェントを使用したPacemakerを通じてMySQLにアクセスできるようにする興味深いアプローチです(記事ではOpenStackについてのみ説明しています)。
メッセージキューのサービスの継続性(HA)
その性質上、RabbitMQデータは頻繁に変更されます。 データの速度と量はメッセージングにとって重要であるため、キューを「安定」として定義していない限り、すべてのメッセージはRAMに保存されます。この場合、RabbitMQはメッセージをディスクに書き込みます。 この機能は、nova.confのrabbit_durable_queues = Trueパラメーターを使用してOpenStackでサポートされています。 メッセージはディスクに書き込まれるため、RabbitMQサーバーがクラッシュまたは再起動しても消えることはありませんが、これは次のように、中断のない動作を保証する実際のソリューションではありません。
-RabbitMQは各メッセージの受信時にディスク上でfsyncを実行しません。したがって、サーバーに障害が発生した場合、ファイルシステムバッファー内のディスクに書き込まれていないメッセージが存在する可能性があります。 再起動後、それらは失われます。
-RabbitMQはまだ1つのノードにのみ配置されています。
RabbitMQ クラスタリングを実行できます。クラスター化されたRabbitMQは「プロキシ」と呼ばれます。 クラスタリング自体は、継続性を確保することよりもスケーリングの方が重要です。 ただし、大きな欠点があります。メッセージキュー自体を除き、すべての仮想ノード、スイッチング要素、ユーザーを複製します。 この欠点を修正するために、 キューをミラーリングする機能が実装されました。 RabbitMQの完全なフォールトトレランスを実現するには、ブローカーの作成とキューのミラーリングを組み合わせる必要があります。
Pacemakerに基づいたソリューションもありますが、上記のソリューションと比較すると時代遅れと見なされます。
上記のクラスタリングモードはいずれもOpenStackで直接サポートされていないことに注意してください。 それにもかかわらず、Mirantisはこの分野で豊富な経験を持っています(これについては以下で詳しく説明します)。
Mirantisでの展開経験
Mirantisは、複数のクライアントに対してMMM(複数のコアレプリカを備えたレプリケーション管理ツール)を使用して、可用性の高いMySQLをインストールしています。 一部の開発者は、オンラインディスカッションでMMMのエラーについて懸念を表明していますが、私たちの経験では、このツールの重大な失敗は見ていません。 私たちはそれを十分かつ許容できる解決策と考えています。 それにもかかわらず、 このソリューションには多くの問題がある人がいることを知っています。したがって、定義によりデータの整合性と管理性が向上し、設定が簡単になるため、WSREP同期レプリケーションアプローチに基づいたアーキテクチャを検討しています、 Galera Cluster 、 XtraDB Cluster )。
以下は、OpenStackの大規模なインストールのために行ったカスタマイズの図です。
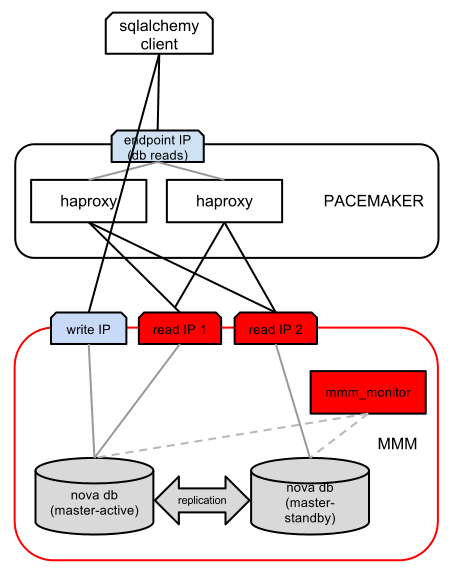
データベースの継続性は、MMMによって保証されます:スタンバイモードの1つのメインレプリカによるマスターマスタレプリケーション(アクティブレプリカのみが記録をサポートし、両方のウィザードが読み取りをサポートするため、1つの「記録」IPアドレスと2つの「読み取り」IPアドレスがあります)。 mmm_monitorモジュールは、両方のマスターの可用性をチェックし、それに応じて「読み取り」IPアドレスと「書き込み」IPアドレスを混合します。
MMM HAproxyの上で、両方のIPアドレス間の負荷分散を読み取ることにより、パフォーマンスが向上します。 もちろん、スケーラビリティを高めるために、読み取り用に追加のIPアドレスを持つ複数の下位ノードを追加できます。 HAproxyはトラフィックを適切に分散しますが、それ自体では中断されない操作を提供しません。そのため、HAproxyの別のインスタンスが作成され、Pacemakerの両方のインスタンスに対してリソースが作成されます。 したがって、HAproxyプロキシの1つに障害が発生すると、Pacemakerはアイドル状態の「記録サーバー」から別のIPアドレスにIPアドレスを転送します。
「記録」IPアドレスは1つしかないため、負荷を分散して書き込み要求を直接送信する必要はありません。
このアプローチでは、データベースファームにスレーブを追加することで書き込み要求のスケーラビリティを確保でき、HAproxyを使用した負荷分散も可能です。 さらに、Pacemaker(HAproxy障害の検出用)とMMM(データベースノード障害の検出用)を使用して高可用性を維持します。
MirantisはRabbitMQ HAとOpenStackを比較して、キューミラーリングをサポートするnovaのアドオンを提案しました。 ユーザーの観点から、このアドオンはnova.confに2つの新しいオプションを追加します。
-rabbit_ha_queues = True / False-キューのミラーリングを有効にします。
-rabbit_hosts = ["rabbit_host1"、 "rabbit_host2"]-ユーザーがクラスター化されたRabbitMQ HAノードのペアを定義できるようにします。
技術的には、次のことが発生します。nova内の各queue.declare呼び出し、x-ha-policy:すべてが追加され、ラウンドロビンクラスターロジックが接続されます。 RabbitMQクラスターの構成はユーザーが実行します。
追加情報
データベースとメッセージングシステムにいくつかの高可用性オプションを導入しました。 以下は、このテーマに関するさらなる研究のためのリンクのリストです。
http://wiki.openstack.org/HAforNovaDB/:OpenStack DBの継続性
http://wiki.openstack.org/RabbitmqHA:中断されないキューシステム
http://www.hastexo.com/blogs/florian/2012/03/21/high-availability-openstack:OpenStackの継続性のさまざまな側面に関する記事
http://docs.openstack.org/developer/nova/devref/rpc.html:OpenStack Messagingの仕組み
http://www.laurentluce.com/posts/openstack-nova-internals-of-instance-launching/:インスタンスを開始するときの一連のステップの興味深い説明
https://lists.launchpad.net/openstack/pdfGiNwMEtUBJ.pdf:novaの連続性に関するプレゼンテーション
http://openlife.cc/blogs/2011/may/different-ways-doing-ha-mysql/:タイトルはすべてを説明しています
http://www.linuxjournal.com/article/10718:MySQLレプリケーションの記事
http://www.mysqlperformanceblog.com/2010/10/20/mysql-limitations-part-1-single-threaded-replication/:レプリケーションパフォーマンスの問題について
https://github.com/jayjanssen/Percona-Pacemaker-Resource-Agents/blob/master/doc/PRM-setup-guide.rst:MySQLレプリケーションの記事:Percona Replication Managerの記事
http://www.rabbitmq.com/clustering.html:RabbitMQクラスタリング
http://www.rabbitmq.com/ha.html:ミラー化されたRabbitMQリクエスト
英語の オリジナル記事