WASは、お客様が実質的に無制限の量のデータを任意の期間保存できるようにするクラウドストレージシステムです。 WASは、2008年11月に製品版で導入されました。以前は、ビデオ、音楽、ゲームの保存、医療記録の保存などのアプリケーションの内部Microsoft目的で使用されていました。これらのサービスの仕事。
WASのお客様は、いつでもどこからでもデータにアクセスでき、使用および保存したものに対してのみ支払います。 WASに保存されたデータは、ローカルと地理の両方の複製を使用して、深刻な混乱からの回復を実装します。 現時点では、WASリポジトリは、ブロブ(ファイル)、テーブル(構造化ストレージ)、キュー(メッセージ配信)の3つの抽象化で構成されています。 これらの3つのデータ抽象化は、ほとんどのアプリケーションで異なるタイプの保存データの必要性をカバーしています。 一般的な使用シナリオは、ブロブにデータを保存することですが、キューの助けを借りて、これらのブロブにデータが転送され、中間データ、状態、および同様の一時データがテーブルまたはブロブに保存されます。
WASの開発中に、顧客の要望が考慮され、鉄鋼のアーキテクチャの最も重要な特徴は次のとおりでした。
- 厳密な一貫性 -多くの顧客は、特に企業クライアントがインフラストラクチャをクラウドに移行する場合、厳密な一貫性を求めています。 また、厳密に一貫性のあるデータを楽観的に制御するための特定の条件に従って、読み取り、書き込み、および削除の操作を実行できるようにしたいと考えています。このため、Windows Azureストレージは、CAP定理(一貫性、可用性、パーティショントレランス)が一度に達成するのが難しいと説明するものを提供しますタイミング:厳密な一貫性、高可用性、およびパーティション許容度。
- グローバルで非常にスケーラブルな名前空間 -ストレージの使用を簡素化するために、WASにはデータを保存し、世界中のどこからでもアクセスできるグローバル名前空間があります。 WASの主な目標の1つは、大量のデータを保存する機能を提供することであるため、このグローバル名前空間は、エクサバイトのデータに対処できる必要があります。
- 災害復旧 -WASは、数百キロメートル離れた複数のデータセンターに顧客データを保存します。この冗長性により、地震、火災、竜巻などのさまざまな状況によるデータ損失から効果的に保護されます。
- マルチテナントおよびストレージのコスト - ストレージのコストを削減するために、1つの共有ストレージインフラストラクチャから多くのクライアントにサービスを提供します。このモデルでは、必要なストレージボリュームが異なる多くのクライアントのストレージを1か所にまとめると、必要なストレージボリューム全体が大幅に削減されますWASが各クライアントに個別の機器を割り当てた場合。
グローバルパーティション化された名前空間についてさらに詳しく考えてみましょう。 Windows Azureストレージシステムの主要な目標は、顧客がクラウド内の任意の量のデータをホストおよびスケーリングできるようにする1つのグローバル名前空間を提供することです。 グローバルな名前空間を提供するために、WASは名前空間の一部としてDNSを使用し、名前空間はストレージアカウントの名前、パーティション名、オブジェクト名の3つの部分で構成されます。
例:
http(s)://AccountName..core.windows.net/PartitionName/ObjectName
AccountName-クライアントが選択したボールトアカウントの名前は、DNS名の一部です。 この部分を使用して、ストレージのメインクラスター、実際には、必要なデータを保存し、このアカウントのデータに対するすべてのリクエストを送信する必要があるデータセンターを見つけます。 1つのアプリケーションのクライアントは、複数のアカウント名を使用して、まったく異なる場所にデータを保存できます。
PartitionName-ストレージクラスターが要求を受信したときにデータの場所を決定するパーティション名。 PartitionNameは、トラフィックに応じて複数のストレージノード間でデータアクセスをスケーリングするために使用されます。
ObjectName-パーティションに多くのオブジェクトがある場合、ObjectNameを使用してオブジェクトを一意に識別します。 システムは、同じPartitionName内のオブジェクトのアトミックトランザクションをサポートします。 ObjectNameはオプションです;一部のデータ型では、PartitionNameはアカウント内のオブジェクトを一意に識別できます。
WASでは、ブロブのPartitionNameとして完全なブロブ名を使用できます。 テーブルの場合、テーブル内の各エンティティには、PartitionNameとObjectNameで構成されるプライマリキーがあることを考慮する必要があります。これにより、アトミックトランザクションのエンティティを1つのパーティションにグループ化できます。 キューの場合、PartitionNameはキュー名の値です。キューに配置される各メッセージには、キュー内のメッセージを一意に識別する独自のObjectNameがあります。
WASアーキテクチャ
ファブリックコントローラーは、データセンター内のフォールトトレランスやその他の多くのタスクを管理、監視、提供します。 これは、ネットワーク接続で始まり、仮想マシン上のオペレーティングシステムの状態で終わる、システムで発生するすべてのことを認識するメカニズムです。 コントローラは、オペレーティングシステムにインストールされた独自のエージェントと常に通信し、OSバージョン、サービス構成、構成パッケージなど、このオペレーティングシステムで何が起こっているかについての完全な情報を送信します。 ストレージに関しては、Fabric Controllerはリソースを割り当て、ディスク全体のデータの複製と配布、および負荷とトラフィックのバランスを管理します。 Windows Azureストレージアーキテクチャを図1に示します。
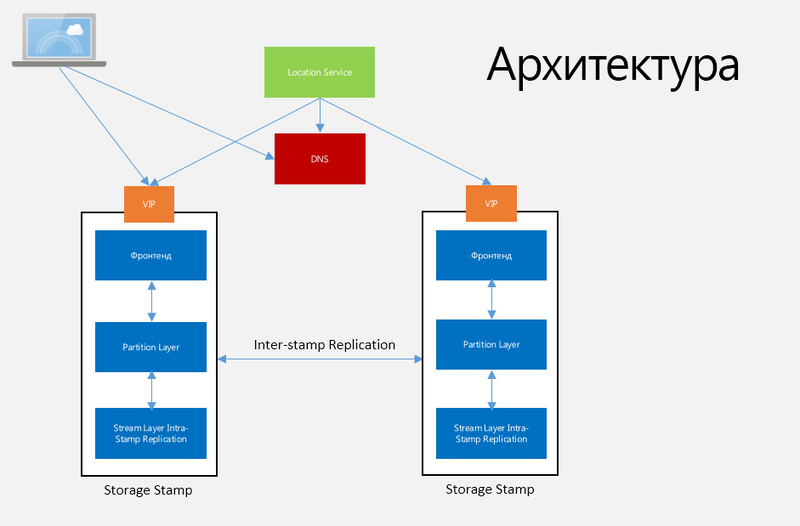
図 1. Windows Azureストレージアーキテクチャ
ストレージスタンプ(SS)。 この用語は、N個の河川(ラック)ストレージノードで構成されるクラスターを指します。各河川は、過剰なネットワーク電力と電力を備えた独自のエラー領域にあります。 通常、クラスターには10から20の川があり、川ごとに18のノードがあり、第1世代のストレージスタンプには約2ペタバイトが含まれています。 以下は最大30ペタバイトです。 また、ストレージスタンプを最もよく使用しようとします。つまり、各SSの使用率は、容量の使用率、トランザクション数、スループットの観点から約70にする必要がありますが、より効率的なディスク操作のために予約する必要があります。 SSの使用率が70%に達すると、ロケーションサービスはSS間レプリケーションを使用してアカウントを他のSSに移行します。
位置情報サービス(LS)。 このサービスは、すべてのSSおよびすべてのSSのアカウント名前空間を管理します。 LSは、SSによってアカウントを配布し、負荷分散およびその他の管理タスクを実装します。 サービス自体は、独自のセキュリティのために地理的に離れた2つの場所に分散されています。
ストリーム層(SL)。 このレイヤーはデータをディスクに保存し、SS内にデータを保存するためにサーバー間でデータを配布および複製します。 SLは、各SS内の分散ファイルシステムのレイヤーであり、「ストリーム」、これらのファイルの保存方法、複製方法などを理解しています。 データはSLに保存されますが、パーティションレイヤーでアクセスできます。 実際、SLは、PLのみが使用するインターフェイスと、追加専用タイプの書き込み操作のみを許可するAPIファイルシステムを提供します。これにより、PLは、パーツのオープン、クローズ、削除、名前変更、読み取り、ストリーム」、「エクステント」と呼ばれる大きなデータチャンクの順序付きリスト(図2)。

図 2.エクステントで構成されるストリームの視覚的表現
ストリームには複数のエクステントポインターを含めることができ、各エクステントにはブロックのセットが含まれます。 さらに、エクステントは「封印」できます。つまり、エクステントに新しいデータを追加することはできません。 Streamからデータを読み取ろうとすると、データはエクステントE1からエクステントE4まで順番に取得されます。 各ストリームはパーティションレイヤーによって1つの大きなファイルとして表示され、ストリームの内容はランダムモードで変更または読み取ることができます。
ブロックする 書き込みおよび読み取りに使用可能なデータの最小単位。特定のNバイトまで可能です。 記録されたデータはすべて、1つ以上の結合ブロックとしてエクステントに書き込まれ、ブロックは同じサイズである必要はありません。
範囲 エクステントは、ストリームレイヤー上のレプリケーションの単位であり、デフォルトでは、ストレージスタンプは、NTFSファイルに格納され、ブロックで構成されるエクステントごとに3つのレプリカを格納します。 パーティションレイヤーで使用されるエクステントサイズは1 GBですが、より小さいオブジェクトはパーティションレイヤーによって1つのエクステント、場合によっては1つのブロックに追加されます。 非常に大きなオブジェクト(ブロブなど)を格納するために、オブジェクトはパーティションレイヤーによっていくつかのエクステントに分割されます。 この場合、もちろんパーティションレイヤーは、どのエクステントとブロックがどのオブジェクトに属するかを監視します。
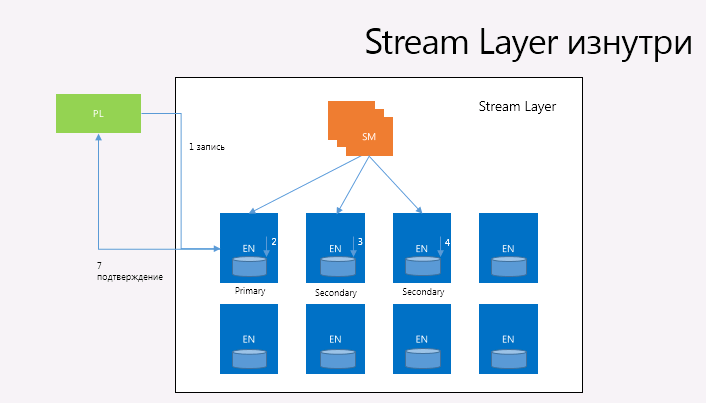
ストリームマネージャー(SM)。 Stream Managerは、ストリームのストリーム名前空間を監視し、すべてのアクティブなストリームとエクステントの状態とExtend Node間のそれらの位置を管理し、すべてのExtendノードの健全性を監視し、エクステントを作成および配布します(ただし、ブロックはストリームマネージャはそれらについて何も知りません)ハードウェアエラーまたは単にアクセスできないためにレプリカが失われたエクステントのレイジーレプリケーションを実行し、「ガベージエクステント」を収集します。 Stream Managerは、それらが保存するすべての拡張ノードとエクステントのステータスを定期的にポーリングおよび同期します。 SMがエクステントが予想されるENの量よりも少なく複製されることを検出すると、SMは複製します。 同時に、状態の量は、1つのStream Managerのメモリに収まるほど小さくすることができます。 ストリームレイヤーの唯一の消費者と顧客はパーティションレイヤーであり、1つのストレージスタンプに5000万を超えるエクステントと100,000を超えないストリームを使用できないように設計されています(絶対に無数の数があるため、ブロックは考慮されません) 32ギガバイトのStream Managerメモリに収まります。
エクステントノード。 各ENは、SMによって割り当てられたエクステントレプリカのセットのリポジトリを管理します。 ENにはN個のマップされたドライブがあり、エクステントとそのブロックのレプリカを維持するために完全に制御されています。 同時に、ENはStreamについて何も知らず(ブロックについて何も知らないStream Managerとは異なり)、エクステントとブロックのみを管理します(エクステント)は、実際にはデータブロックとそのチェックサムを含むディスク上のファイルです+エクステントのシフトと対応するブロックおよびそれらの物理的な位置との関連付けのマップ。 各ENには、そのエクステントと、特定のエクステントのレプリカがどこにあるかのいくつかのアイデアが含まれています。 ストリームが特定のエクステントを参照しなくなった場合、Stream Managerはこれらのガベージエクステントを収集し、スペースを解放する必要があることをENに通知します。 同時に、Streamのデータは追加のみ可能で、既存のデータは変更できません。 追加操作はアトミックです。データブロック全体が追加されるか、何も追加されません。 ある時点で、同じアトミック操作内で複数のブロックを追加できます(「複数のブロックの追加」)。 Streamから読み取ることができる最小サイズは1ブロックです。 複数のブロックを追加する操作により、クライアントは1回の操作で大量のシーケンシャルデータを記録できます。
すでに述べたように、各エクステントにはサイズに一定の上限があり、満杯になるとエクステントが封印され、新しいエクステントでさらに書き込み操作が行われます。 封印された範囲にデータを追加することはできず、不変です。
エクステントに関するいくつかのルールがあります。
1.レコードを追加し、クライアントへの操作を確認した後、レプリカからこのレコードを読み取る以降のすべての操作では、同じデータが返されます(データは不変です)。
2.エクステントが封印された後、封印されたレプリカからのすべての読み取り操作は、同じエクステントコンテンツを返す必要があります。
たとえば、ストリームが作成されると、SMは3つのエクステントノードの最初のエクステント(1つのプライマリと2つのセカンダリ)に3つのレプリカを割り当てます。これらのエクステントノードは、ロードバランシングの可能性を考慮して、異なる更新ドメインとエラードメイン間のランダム分散のためにSMによって選択されます。 さらに、SMはどのレプリカをエクステントのプライマリにするかを決定し、エクステントへのすべての書き込み操作はプライマリENで最初に実行され、その後プライマリENでのみ2つのセカンダリENでレコードが作成されます。 プライマリENおよび3つのレプリカの場所は、エクステントによって変化しません。 SMがエクステントを配置すると、エクステント情報がクライアントに送り返され、クライアントはどのENに3つのレプリカが含まれ、どのレプリカがプライマリであるかを認識します。 この情報はStreamメタデータの一部になり、クライアントにキャッシュされます。 Streamの最後のエクステントがシールされると、プロセスが繰り返されます。 SMは別のエクステントを配置し、そのエクステントがStreamの最後のエクステントになり、すべての新しい書き込み操作は新しい最後のエクステントで実行されます。 エクステントの場合、各追加操作はすべてのエクステントレプリカにわたって3回レプリケートされ、クライアントはすべての書き込み要求をプライマリENに送信しますが、読み取り操作は、シールされていないエクステントに対しても任意のレプリカから実行できます。 追加操作はプライマリENに送信され、プライマリENはエクステントのシフトを決定し、1つのエクステントで並列記録が発生した場合にすべての書き込み操作を順序付け、2つのセカンダリENによる必要なシフトを伴う追加操作を送信し、クライアントに操作確認を送信します、3つのレプリカすべてで追加操作が確認された場合にのみ送信されます。 レプリカの1つが応答しないか、何らかのハードウェアエラーが発生した(または発生した)場合、書き込みエラーがクライアントに返されます。 この場合、クライアントはSMにアクセスし、書き込み操作が発生した範囲であるSMは封印されます。
次に、SMは他の使用可能なENにレプリカを持つ新しいエクステントを配置し、このエクステントをストリームの最後としてマークします。この情報はクライアントに返され、クライアントは新しいエクステントに追加する操作を実行し続けます。 新しいエクステントの封印と配置の一連のアクションは、平均でわずか20ミリ秒で実行されることに注意してください。
シーリングプロセス自体については。 エクステントを封印するために、SMは現在の長さについて3つすべてのENをポーリングします。 2つのシナリオを封印するプロセスで-同じサイズのすべてのレプリカ、またはレプリカの1つが他のレプリカより長いか短い。 2番目の状況は、ENの一部(すべてではない)が使用できなかったときに追加操作が失敗した場合にのみ発生します。 エクステントをシーリングするとき、SMは利用可能なENに基づいて最短の長さを選択します。 これにより、クライアントに対して確認されたすべての変更が封印されるように、範囲を封印することができます。 シーリング後、確認されたエクステントの長さは変化せず、SMがシーリング中にENに接触できず、ENが使用可能になると、SMはこのENを確認された長さに強制的に同期させ、ビットのセットを同一にします。
ただし、ここでは異なる状況が発生する可能性があります-SMはENに接続できませんが、クライアントであるパーティションサーバーは接続できます。 パーティションレイヤーには、少し後で2つの読み取りモードがあります。既知の位置でレコードを読み取り、ストリーム内のすべてのレコードを反復処理します。 最初の場合-パーティションレイヤーは、記録とblobの2種類のストリームを使用します。 これらのストリームでは、特定の位置(範囲+シフト、長さ)で常に読み取り操作が発生します。 パーティションレイヤーは、ストリームレイヤーでの前回の正常な追加操作の後に返される位置情報を使用して、これら2つのタイプの読み取り操作を実行します。 2番目のケースでは、ストリーム内のすべてのレコードが順番にソートされると、各パーティションには2つの個別のストリーム(メタデータと確認ログ)があり、パーティションレイヤーは最初から最後まで順番に読み取ります。
Windows Azureストレージでは、データの可用性レベルを低下させることなく、使用済みのディスク領域とトラフィックを節約できるメカニズムが導入されました。これは消去コードと呼ばれます。 このメカニズムの本質は、エクステントがほぼ同じサイズのN個のフラグメントに分割され(実際にはこれらもファイルである)、その後リードソロモンアルゴリズムに従って、エラー訂正コードのM個のフラグメントが追加されることです。 これはどういう意味ですか? XのNフラグメントのサイズは元のファイルと同じです。元のファイルを復元するには、フラグメントのXを収集してデコードすれば十分で、残りのNXフラグメントは削除、破損などが可能です。 エラー修正コードのMを超えるフラグメントがシステムに保存されている限り、システムは元のエクステントを完全に復元できます。
クラウドエクステントに保存された膨大な量のデータでは、使用されるフラグメントの数に応じてソースデータの3つの完全なレプリカから1.3-1.5ソースデータにデータを保存するコストを削減でき、データの「安定性」を高めることができるため、このようなシールエクステントの最適化は非常に重要ですストレージスタンプ内に3つのレプリカを保存するのと比較して。
3つのレプリカを持つエクステントに対して書き込み操作を実行する場合、すべての操作は特定の時間値で実行されます。この時間内に操作が完了しない場合、この操作は実行しないでください。 ENは、一定時間内に読み取り操作を完全に完了できないと判断した場合、すぐにクライアントに報告します。 このメカニズムにより、クライアントは読み取り操作で別のENにアクセスできます。
同様に、消去コーディングが使用されるデータの場合-読み込み操作が重い負荷のために期間内に完了する時間がない場合、この操作はデータの完全な断片の読み込みには使用できませんが、データ再構築オプションを利用する場合があり、その場合は読み込み操作が参照します消去コードを含むエクステントのすべてのフラグメント、および最初のN個の回答を使用して、必要なフラグメントが再構築されます。
WASシステムが非常に大きなストリームを処理できることを考えると、次の状況が発生する可能性があります。 この状況を防ぐために、WASは、100ミリ秒を超える実行可能な操作が既に割り当てられている場合、または既に割り当てられている操作が割り当てられているが200ミリ秒で完了していない場合、新しいI / O操作をディスクに割り当てません。
書き込むストリームレイヤーによってデータが決定されると、追加のディスク全体またはSSDがすべてのEN書き込み操作のログのストレージとして使用されます。 ジャーナリングディスクは1つのジャーナル用に完全に予約されており、すべての書き込み操作が順次記録されます。 各ENは追加操作を実行すると、すべてのデータをジャーナリングディスクに書き込み、ディスクへのデータの書き込みを開始します。 ジャーナリングディスクが成功したオペレーションコードを早く返す場合、データはメモリにバッファリングされ、すべてのデータがデータディスクに書き込まれるまで、すべての読み取りオペレーションはメモリから提供されます。 たとえば、追加操作は、クライアントの操作を確認するためにデータディスクからの読み取り操作と「競合」してはならないため、ジャーナリングディスクを使用すると重要な利点が得られます。 このログにより、パーティションレイヤーを使用した追加操作の一貫性が高まり、遅延が少なくなります。
パーティション層(PL)。 このレイヤーには特別なパーティションサーバー(デーモンプロセス)が含まれ、実際のストレージ抽象化(ブロブ、テーブル、キュー)、名前空間、トランザクションの順序、オブジェクトの厳密な一貫性、SLへのデータの保存、I / O操作の数を減らすためのデータのキャッシュを管理することを目的としていますディスクに。 PLは、PartitionNameに従ってSS内のデータオブジェクトをパーティション化し、パーティションサーバー間で負荷をさらに分散することにも関与します。 パーティションレイヤーは、オブジェクトテーブル(OT)と呼ばれる内部データ構造を提供します。これは、数ペタバイトに拡大できる大きなテーブルです。 OTは、負荷に応じて、RangePartitionsに動的に分割され、ストレージスタンプ内のすべてのパーティションサーバーに分散されます。 RangePartitionは、OTのレコードの範囲であり、提供された最小のキーから最大のキーまでです。
OTにはいくつかの異なるタイプがあります。
•アカウントテーブルには、ストレージスタンプに関連付けられている各ストレージアカウントのメタデータと構成が保存されます。
•Blobテーブルには、ストレージスタンプに関連付けられたすべてのアカウントのすべてのBlobオブジェクトが保存されます。
•エンティティテーブルは、ストレージスタンプに関連付けられたすべてのストレージアカウントのすべてのエンティティレコードを格納し、Windows Azureテーブルストレージサービスに使用されます。
•メッセージテーブルには、ストレージスタンプに関連付けられているすべてのストレージアカウントのすべてのキューのすべてのメッセージが格納されます。
•スキーマテーブルは、すべてのOTのスキーマを追跡します。
•パーティションマップテーブルは、すべてのオブジェクトテーブルの現在のすべてのRangePartitionと、どのRangePartitionにサービスを提供しているPartition Serverを追跡します。 このテーブルは、要求を必要なパーティションサーバーにリダイレクトするためにFEサーバーによって使用されます。
すべてのタイプのテーブルには固定スキーマがあり、スキーマテーブルに保存されます。
すべてのOTスキームには、bool、binary、string、DateTime、double、GUID、int32、int64のプロパティタイプの標準セットがあります。さらに、システムは2つの特別なプロパティDictionaryTypeとBlobTypeをサポートします。 。 これらのプロパティは、ディクショナリタイプ内に次のように保存されます。
(名前、タイプ、値)。 2番目の特別なプロパティは、大量のデータを保存するために使用され、現在Blob Tableにのみ使用されていますが、blobデータは一般的なレコードのストリームには保存されず、blobデータの別のストリームに保存され、実際にはblobデータへのリンクのみが保存されます(リストリンク「エクステント+シフト、長さ」)。 OTは、単一のPartitionName値を持つレコードのバッチトランザクションだけでなく、挿入、更新、削除、読み取りなどの標準操作をサポートします。単一のバッチでの操作は、単一のトランザクションとして確認されます。OTは、読み取り操作を書き込み操作と並行して実行できるようにするために、スナップショット分離もサポートしています。
パーティションレイヤーアーキテクチャ
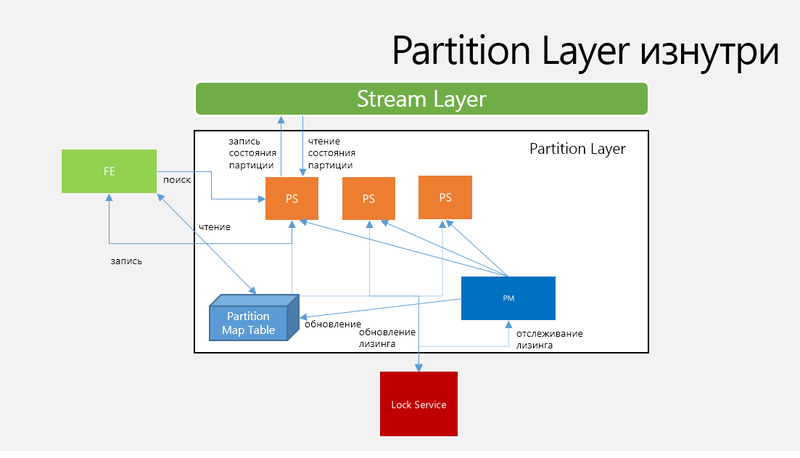
図4.アーキテクチャとワークフローPartition Layer
Partition Manager(PM)は、ストレージスタンプ内のN RangePartitionで大きなOTを監視および共有し、RangePartitionを特定のパーティションサーバーに割り当てます。保存場所に関する情報は、パーティションマップテーブルに保存されます。1つのRangePartitionは1つのアクティブなパーティションサーバーに割り当てられ、2つのRangePartitionが交差しないようにします。
各ストレージスタンプにはPMのインスタンスがいくつかあり、それらはすべて、ロックサービスに格納されている1つのリーダーロックを「競合」します。
パーティションサーバー(PS)このPMサーバーに割り当てられたRangePartitionsの要求を処理し、すべてのパーティションステータスをStreamsに保存し、メモリ内のキャッシュを管理します。 PSは、複数のOTから複数のRangePartitionにサービスを提供することができ、場合によっては平均で最大12個のサービスを提供できます。 PSは次のコンポーネントを提供し、それらをメモリに保存します。
• Memory Table、RangePartitionの確認ログのバージョン。チェックポイントによってまだ確認されていない最近のすべての変更が含まれます。
• インデックスキャッシュ。レコードのデータストリームのコントロールポイントの位置を含むキャッシュ。
• 行データキャッシュ、チェックポイントのレコードデータページ用のメモリ内のキャッシュ。このキャッシュは読み取り専用です。キャッシュにアクセスすると、行データキャッシュとメモリテーブルがチェックされ、2番目が優先されます。
• ブルームフィルター -行データキャッシュとメモリテーブルにデータが見つからない場合、データストリーム内の位置とコントロールポイントが調べられ、それらの大まかな列挙は無効になるため、各コントロールポイントに特別なブルームフィルターが使用されます。コントロールポイントのレコードへのアクセス。
ロックサービス担当PMの選択に使用されます。各PSは、パーティションを提供するロックサービスを使用してリースも管理します。 PSエラーでは、このPSにサービスを提供するすべてのN RangePartitionsが利用可能なPSに再割り当てされます。 PMは負荷に基づいてN PSを選択し、PMはRangePartitions PSを割り当て、適切なデータでパーティションマップテーブルを更新します。これにより、フロントエンドレイヤーはパーティションマップテーブルにアクセスしてRangePartitionsの場所を見つけることができます。 RangePartitionはLog-Structured Merge-Treeを使用してデータを保存します。各RangePartitionはStream Layer上の独自のStreamセットで構成され、Streamは特定のRangePartitionを完全に参照します。
各RangePartitionは、次のいずれかのストリームで構成できます。
• メタデータストリーム-このストリームは、RangePartitionのメインです。 PMは、そのPSのメタデータストリーム名を提供することにより、PSパーティションを割り当てます。
• コミットログストリーム -このストリームは、RangePartitionに対して生成された最後のポイントからRangePartitionに適用された確認済みの挿入、更新、および削除操作のログを保存するように設計されています。
• 行データストリームは、RangePartitionsの記録データと位置を保存します
。• Blobデータストリームは、Blobデータを保存するためにBlobテーブルにのみ使用されます。
リストされているすべてのストリームは、OT RangePartitionによって管理されるストリームレイヤーの異なるストリームです。OTの各RangePartitionには、Blob Tableを除くデータストリームが1つだけあります-Blob TableのRangePartitionには、記録の最後のコントロールポイント(blob位置)を保存するためのレコードデータストリームと、特別なBlobTypeタイプのデータを保存するためのblobの個別のデータストリームがあります。
RangePartitionsロードバランシング
パーティションサーバー間で負荷を分散し、ストレージスタンプ内のパーティションの総数を決定するために、PMは次の3つの操作を実行します。
• 負荷分散。この操作を使用して、特定のPSの負荷が高すぎる場合に判断され、1つ以上のRangePartitionsが負荷の低いPSに再割り当てされます。
• 分割。この操作は、特定のRangePartitionが過負荷になり、このRangePartitionが2つ以上の小さなパーティションに分割された後、これらのRangePartitionが2つ以上のPSに分散されるタイミングを決定します。 PMはSplitコマンドを送信しますが、AccountNameとPartitionNameに基づいて、パーティションを分割する場所PSを決定します。この場合、たとえば、RangePartition Bを2つのRangePartition CとDに分割するには、次の操作が実行されます
。o PMはPSコマンドを送信してBをCとDに分割
します。o PSはBのブレークポイントを作成し、トラフィックの受信を停止します。
o PSは特別なMultiModifyコマンドを実行し、Bからストリーム(メタデータ、確認ログ、データ)を収集し、Bと同じ順序でCとDの新しいストリームセットを作成します(実際には、データへのポインター)。 PSは、CおよびDの新しいパーティションキー範囲をメタデータに追加します。
o PSは、新しいパーティションCおよびDのトラフィックサービスを再開します
。o PSは、パーティションの完了をPMに通知し、パーティションマップテーブルとメタデータを更新して、パーティションパーティションを異なるPSに転送します。
• マージ。この操作では、2つの「コールド」または軽負荷のRangePartitionsが組み合わされて、OTのキー範囲が形成されます。これを行うために、PMは、低負荷の隣接するPartitionName範囲を持つ2つのRangePartitionsを選択し、次のアクションのシーケンスを実行します:
o PMがCとDを転送して、1つのPSにサービスを提供し、PSコマンドにCとDをEに結合するよう指示します
o PS CおよびDのブレークポイントを保存し、CおよびDへのトラフィックの提供を一時的に停止します
.o PSはMultiModifyコマンドを実行して、新しい確認ログとデータストリームEを作成します。これらのストリームはそれぞれ、CおよびDからの対応するストリームのすべてのエクステントの結合です。
o PSは、確認ログとデータストリームの名前を含むEメタデータストリームを作成し、Eのキーの組み合わせ範囲と確認ログのポインター(範囲+シフト)(CおよびDから)を作成します。
o RangePartition Eのトラフィックサービスが開始されます
。o PMはパーティションマップテーブルとメタデータを更新します。
負荷を分散するために、次のメトリックが追跡されます
。•1秒あたりのトランザクション数。
•保留中のトランザクションの平均数。
•CPUの負荷。
•ネットワーク負荷。
•要求の遅延。
•RangePartitionデータのサイズ。
同時に、PMは各PSのハートビートを制御し、これに関する情報はハートビートに応じてPMに送信されます。 PMは、RangePartitionの負荷が大きすぎる(メトリックに基づいて)と判断した場合、パーティションを共有し、PSコマンドを送信して分割操作を実行します。 PS自体がRangePartitionではなく高負荷になっている場合、PMは既存のRangePartition PSを負荷の少ないPSに再割り当てします。 RangePartitionの負荷を分散するために、PMはRangePartitionでPSコマンドを送信して現在のブレークポイントを記録します。その後、PSはPM確認を送信し、PMはRangePartitionを別のPSにオーバーライドし、パーティションマップテーブルを更新します。
ハッシュベースのインデックス付け(キーハッシュによってサーバーにオブジェクトが割り当てられる場合)ではなく、範囲ベースのパーティションメカニズム(RangePartitionが実行される)を選択する決定は、特定のアカウントのオブジェクトのために、範囲ベースのパーティション分割によりパフォーマンス分離の実装が容易になるという事実によって正当化されましたRangePartitionsセット内に並べて保存されるハッシュベースのインデックス作成は、サーバーの負荷を分散するタスクも簡素化しますが、同時に、オブジェクトを分離する目的での局所性の利点を奪います効率的なリスト。範囲に基づいたパーティション分割により、1つのクライアントのオブジェクトを1つのパーティションセットにまとめて格納できます。これにより、潜在的に安全でないアカウントを効果的に制限または分離することもできます。このアプローチの欠点の1つは、シーケンシャルアクセスシナリオでのスケーリングです。たとえば、クライアントがすべてのデータをテーブルキー範囲の最後に書き込む場合、すべての書き込み操作はクライアントテーブルの最新のRangePartitionにリダイレクトされます。この場合、システムのパーティション化と負荷分散の利点は使用されません。クライアントが書き込み操作を多数のPartitionNamesに分散する場合、システムはテーブルを一連のRangePartitionsにすばやく分割し、それらを複数のサーバーに分散するため、効率が直線的に向上します。その後、すべての書き込み操作は、クライアントテーブルの最新のRangePartitionにリダイレクトされます。この場合、システムのパーティション化と負荷分散の利点は使用されません。クライアントが書き込み操作を多数のPartitionNamesに分散する場合、システムはテーブルを一連のRangePartitionsにすばやく分割し、それらを複数のサーバーに分散するため、効率が直線的に向上します。その後、すべての書き込み操作は、クライアントテーブルの最新のRangePartitionにリダイレクトされます。この場合、システムのパーティション化と負荷分散の利点は使用されません。クライアントが書き込み操作を多数のPartitionNamesに分散する場合、システムはテーブルをRangePartitionsのセットにすばやく分割し、それらを複数のサーバーに分散します。これにより、効率が直線的に向上します。
フロントエンド(FE)。フロントエンド層は、着信要求を受け入れるステートレスサーバーのセットで構成されます。 FEは、リクエストを受信すると、AccountNameを読み取り、リクエストを認証および承認し、PL上のパーティションサーバーに(受信したPartitionNameに基づいて)転送します。 FEが所有するサーバーは、いわゆるパーティションマップをキャッシュします。このマップでは、システムがPartitionName範囲の追跡を管理し、パーティションサーバーが提供するPartitionNameを管理します。
スタンプ内複製(ストリーム層)。このメカニズムは、同期レプリケーションとデータセキュリティを制御します。エラーが発生した場合にこのデータを保存するために、異なるエラードメインの異なるノードに十分なレプリカを保存し、SLで完全に実行します。クライアントから受信した書き込み操作の場合、レプリケーションが正常に完了した後にのみ確認されます。
スタンプ間複製(パーティション層)。この複製メカニズムは、SS間の非同期複製を実行し、この複製をバックグラウンドで実行します。レプリケーションはオブジェクトレベルで発生します。つまり、オブジェクト全体がレプリケートされるか、その変更(デルタ)がレプリケートされます。
これらのメカニズムは、イントラスタンプが大規模システムで定期的に発生する鉄エラーに対する安定性を提供し、インタースタンプがまれにしか発生しないさまざまな災害に対して地理的な冗長性を提供するという点で異なります。このタイプのレプリケーションの主なシナリオの1つは、自然災害から回復するための2つのデータセンター間のストレージアカウントデータの地理的レプリケーションです。
BLOBおよびテーブルストレージサービスのすべてのデータは地理的に複製されます(ただし、キューはありません)。地理的に冗長なストレージを使用すると、プラットフォームは再び3つのレプリカを2つの場所に保存します。ストレージアカウントを展開すると、LSは各地理的場所でストレージスタンプを選択し、選択したAccountNameをすべてのストレージスタンプに登録します。一方、ロケーションの1つはライブトラフィックを受信し、2番目のセカンダリはスタンプ間レプリケーションのみを実行します(実際には地理的複製があります)。次に、LSはメインの場所のVIPにつながる新しいAccountName.service.core.windows.netエントリのDNSを更新します。したがって、データセンターで何かが発生した場合、データは2番目の場所から利用できます。書き込み操作がボールトアカウントのメインの場所に到着すると、変更はStream Layerのスタンプ内複製を使用して完全に複製され、その後、操作の正常終了に関するコードがクライアントに返されます。非同期モードでの操作を確認すると、別の地理的場所への複製が行われ、そこでトランザクションはすでにパーティションレイヤーに適用されます。
地理的な耐障害性と、深刻な混乱が発生した場合のすべての復元方法について。主要な地理的位置で重大なグリッチが発生した場合、企業が結果を最大限になだめようとするのは当然です。ただし、すべてが非常に悪く、データが失われた場合、地理的フォールトトレランスのルールを適用する必要があります-クライアントはメインロケーションで災害を通知され、その後、対応するDNSレコードがメインロケーションから2番目(account.service.core.windows.net)に割り込まれます)もちろん、DNSレコードを変換するプロセスでは、何かが機能する可能性は低いですが、完了すると、既存のBLOBとテーブルがURLで利用可能になります。翻訳プロセスが完了すると、2番目の地理的な場所がメインの場所にアップグレードされます(地球を介したデータセンターの別の障害が発生するまで)。また、データセンターのステータスを上げるプロセスが完了した直後に、同じ地域に新しい2番目の地理的な場所を作成し、さらにデータを複製するプロセスが開始されます。開発チームは、1つの地域に2つ以上のデータセンターがある場合、ユーザーは2番目の地理的な場所を選択できると発表しましたが、これまでのところ、この可能性に気付いていません(おそらく、そのような地域を知らないため)。1つの地域に2つ以上のデータセンターがあるが、これまでのところ、そのような機会に気付いていません(おそらく、そのような地域を知らないため)。1つの地域に2つ以上のデータセンターがあるが、これまでのところ、そのような機会に気付いていません(おそらく、そのような地域を知らないため)。
地理的複製のプロセスは、データセンターを食べた一時的な恐竜よりも頻繁に行動に影響を与え、地理的フェールオーバーにつながったという理由だけで、より興味深いものになります。
そのため、たとえば、ストレージアカウントには、fooとbarといういくつかのブロブ(開発者のブログの例)があります。 BLOBの場合、完全なBLOB名はPartitionKey値と等しくなります。 BLOB fooで2つのトランザクションAとBを実行し、その後BLOBバーで2つのトランザクションXとYを実行します。システムは、トランザクションAがトランザクションBの前に地理的に複製されることを保証するため、トランザクションXはトランザクションYの前に地理的に複製されます。それ以外の場合、保証はありません-fooのトランザクションとbarのトランザクション間の地理的複製にどのくらいの時間がかかるかは不明です。また、レプリケーション時にデータセンターが何らかの理由で故障し、最近のトランザクションを地理的に複製できない場合、トランザクションAとXが複製される可能性があります。トランザクションBとYは失われます。または、AとBのみが複製され、XとYは消えます。同じことがテーブルサービスでも発生する可能性があります(テーブル内のパーティションがBLOB名ではなく、エンティティのPartitionKeyアプリケーションによって決定される場合)。
まとめ
Windows Azureストレージサービスはプラットフォームの重要なコンポーネントであり、クラウドストレージサービスを提供し、マルチテナント環境での強力な一貫性、グローバルネームスペース、高いデータ復元力などの機能を組み合わせます。