RSSフィードからWebページを自動的に分類する
SurfingbirdでWebページ(または、むしろそれらへのリンク)を追加するための通常のスキームは次のとおりです。新しいリンクを追加するとき、ユーザーはこのリンクが属する最大3つのカテゴリを指定する必要があります。 このような状況では、カテゴリを自動的に決定するタスクに価値がないことは明らかです。 ただし、手動での追加に加えて、リンクは多くの人気サイトで提供されているRSSフィードからデータベースにアクセスします。 RSSフィードには多くのリンクが含まれているため、多くの場合、モデレーター(およびこの場合はカテゴリーを強制することを余儀なくされます)は、単にそのようなボリュームに対処できません。 問題は、カテゴリへの自動分類のインテリジェントシステムを作成するときに発生します。 多くのサイト(たとえば、lenta.ruやsueta.ru)の場合、カテゴリをrss-xmlから直接取得し、内部カテゴリに手動でリンクできます。
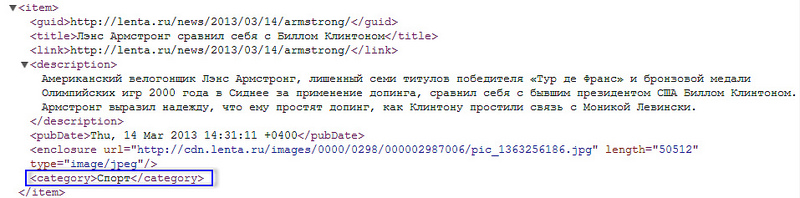
カテゴリが固定されておらず、代わりにカスタムタグを使用しているRSSフィードの場合、事態はさらに悪化します。 任意に入力されたタグ(典型的な例はLJ投稿のタグ)は、手動でカテゴリに関連付けることはできません。 そして、ここでは、より微妙な数学がすでに含まれています。 テキストコンテンツ(タイトル、タグ、有用なテキスト)がページから抽出され、 LDAモデルが適用されます。その簡単な説明は、 以前の記事で確認できます。 その結果、テーマLDAトピックに属するWebページの確率ベクトルが計算されます。 結果のLDAサイトトピックのベクトルは、カテゴリごとの分類問題を解決するための特徴ベクトルとして使用されます。 さらに、分類の対象はサイトであり、クラスはカテゴリです。 ロジスティック回帰が分類方法として使用されましたが 、 単純ベイズ分類器などの他の方法も使用できます。
この方法をテストするために、モデレーターがRSSフィードから分類した5,000のサイトでモデルトレーニングが行われました。これらのサイトでは、LDAトピックによる配信も知られていました。 テストサンプルのトレーニングの結果を表に示します。
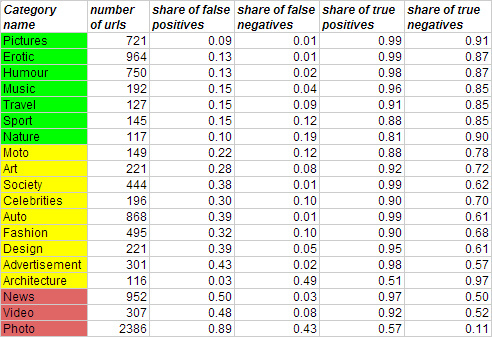
その結果、許容できる分類品質(誤検出の割合と偽パスの割合による)は、写真、エロチック、ユーモア、音楽、旅行、スポーツ、自然のカテゴリでのみ得られました。 写真、ビデオ、ニュースなどの一般的なカテゴリが多すぎると、エラーが大きくなります。
結論として、外部カテゴリへの緊密なバインドの場合、原則として完全自動モードで分類が可能な場合、最も可能性の高いカテゴリがモデレーターに提供されるときに、テキストコンテンツによる分類は必然的に半自動モードで行われる必要があると言えます。 ここでの目標は、モデレーターの作業を可能な限り簡素化することです。
Webページ間の重複と盗作を検索する
テキストマイニングが解決できるもう1つのタスクは、重複コンテンツを含むリンクを見つけてフィルタリングすることです。 次のいずれかの理由で、繰り返しコンテンツが可能です。
- いくつかの異なるリンクの場合、同じエンドリンクへのリダイレクトが発生します。
- コンテンツはさまざまなWebページに完全にコピーされます。
- コピーされたコンテンツの一部またはわずかな変更。
最初と2番目のポイントは技術的であり、終了リンクを取得し、データベース内のすべてのページの有用なコンテンツを文字通り比較することで解決されます。 ただし、完全なコピーと貼り付けを行っても、明らかな理由(たとえば、サイトメニューのランダムな文字や単語が含まれるなど)により、有用なテキストの正式な比較が機能しない場合があります。 この3番目のオプションをさらに詳しく検討します。 典型的なdoubleは次のようになります。
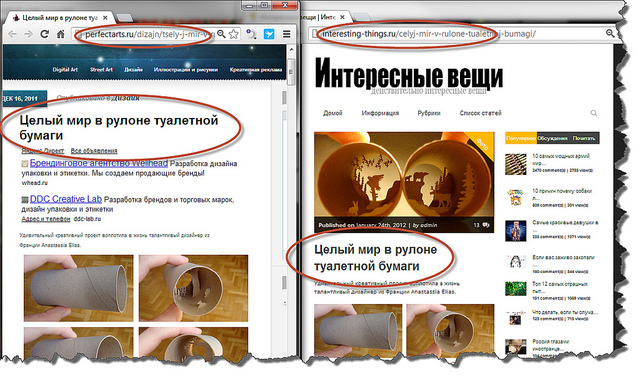
広い意味での借用を決定する問題はかなり複雑です。 彼女は、より狭い声明に興味を持っています。テキストの各フレーズで盗作を検索する必要はありませんが、コンテンツ全体のドキュメントを比較するだけです。
これを行うには、既存のバッグオブワードモデルと、すべてのサイト用語の計算されたTF-IDF重みを効果的に使用できます。 いくつかの異なるテクニックがあります。
まず、次の表記法を紹介します。
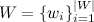 -すべての異なる単語の辞書。
-すべての異なる単語の辞書。
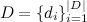 -テキストの本文(Webページのコンテンツ);
-テキストの本文(Webページのコンテンツ);
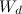 -ドキュメント内の多くの単語。
-ドキュメント内の多くの単語。
2つのドキュメントを比較するには
 そして
そして 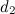 最初に、単語の結合ベクトルを構築する必要があります
最初に、単語の結合ベクトルを構築する必要があります 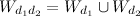 両方の文書に現れる言葉から:
両方の文書に現れる言葉から:
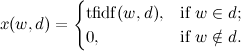
テキストの類似性は、正規化されたスカラー積として計算されます。
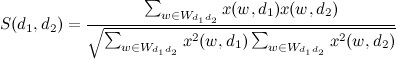
もし
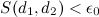 (類似度のしきい値)、ページは二重と見なされます。
(類似度のしきい値)、ページは二重と見なされます。
別のアプローチでは、TF-IDFの重みを考慮しませんが、バイナリデータを使用して類似性を構築します(ドキュメントに単語があるかどうか)。 ページの違いを評価するために、ジャカード係数が使用されます:
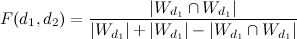 、
、
どこで
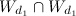 -ドキュメント内の多くの一般的な単語。
-ドキュメント内の多くの一般的な単語。
これらの方法を適用した結果、数千の双子が特定されました。 正式な品質評価を行うには、トレーニングセットでダブルスを専門的にマークする必要があります。
これですべてです。この記事がお役に立てば幸いです。 そして、推奨事項を改善するためにテキストマイニングを適用する方法に関する新しいアイデアを喜んでいます!