すべてのアレイは、0、1、10、5、50、6の基本RAIDレベルをサポートします。ハイエンドには、RAIDグループ内のディスクの数と使用可能なRAIDレベルに関する厳しい要件があります。 同時に、1つのRAIDグループのディスクをディスクシェルフ間に配置する方法に関して、多くの要件もあります。 ミッドレベルおよびエントリーレベルのシステムには、このような厳しい制限はありません。 ストレージのパフォーマンスと信頼性の両方の観点から、1つのグループのディスクを別のディスクシェルフに配置する方がはるかに優れていることは明らかです。たとえば、ディスクシェルフコントローラーまたはディスクシェルフ全体の障害により、グループデータの操作を続行できます。 一方、エントリーレベルおよび中間レベルのシステムに対するこのような厳格なルールは、システム全体の柔軟性を大幅に低下させます。 したがって、たとえば、エントリーレベルまたはミッドレンジシステム用の1つのシェルフ上のすべてのディスクからディスクグループを作成しても問題はありませんが、同時に、ハイエンドアレイではそのようなグループを作成できません。 繰り返しますが、エントリーレベルおよび中間レベルのシステムでは、同じグループのディスクを異なるシェルフに分散することもお勧めします-それは確かに悪化しません。
すべてのシステムは、SAS、NL-SAS、およびSSDドライブをサポートしています。 さらに、2.5インチおよび3.5インチのドライブシェルフがサポートされています。 さまざまなタイプのディスクをシェルフに任意の順序でインストールできます。 異なるタイプのディスクを1つのグループにまとめることは、控えめに言ってもお勧めできないことは明らかです。 システム内のSSDの数に制限はありません。 予算の制約、便宜、常識に加えて。
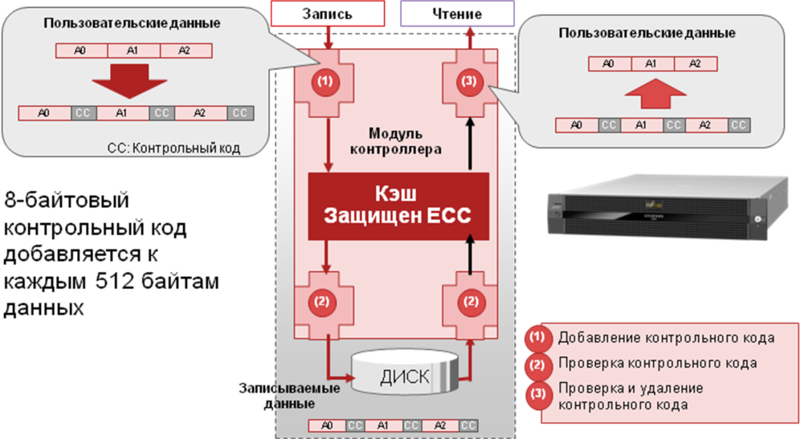
すべてのディスクは、520バイトのブロックで特別な方法で低レベルにフォーマットされています。 これらのうち、512はデータ用、8は整合性制御用です。 記録時に、システムは512バイトの各ブロックの制御コードを計算し、ブロックの後に書き込みます。 ブロックを読み取る段階で、データの整合性が必ずチェックされ、制御ブロックが破棄され、制御コードのない元のブロックがホスト出力に送信されます。 また、システムに空きコンピューティングリソースがあり、I / Oリソースが100%ロードされていない場合、制御コードの正確性もバックグラウンドでチェックされます。 このメカニズムは、データブロックガードと呼ばれます。
ストレージの信頼性を高める次のメカニズムは、冗長コピーです。 このメカニズムについて話す前に、いくつかのホラーストーリーを紹介します。 もちろん、ハードドライブの故障は悪いです。 さらに、ハードディスクの容量の増加に伴ってブロックとセクターの数が増加するため、デバイス全体の故障の可能性も増加します。 もちろん、3TBドライブが故障する確率は1TBドライブの3倍ではありませんが、それにもかかわらず、比較的最近、産業グレードのRAID6が登場しました。 ここで、平均的なRAIDグループの寿命を見てみましょう-高い確率で、これらは同じ条件下で同じ時間数で動作した1つの工場バッチからのディスクであり、そのうちの1つが故障し、グループの再構築プロセスが開始されたため、残りのディスクの負荷が増加しました。 さて、失敗の理論、統計、偶然の神秘主義が彼らの仕事を始めます。 時々、バックアップの可用性と整合性を同時にチェックします:)。
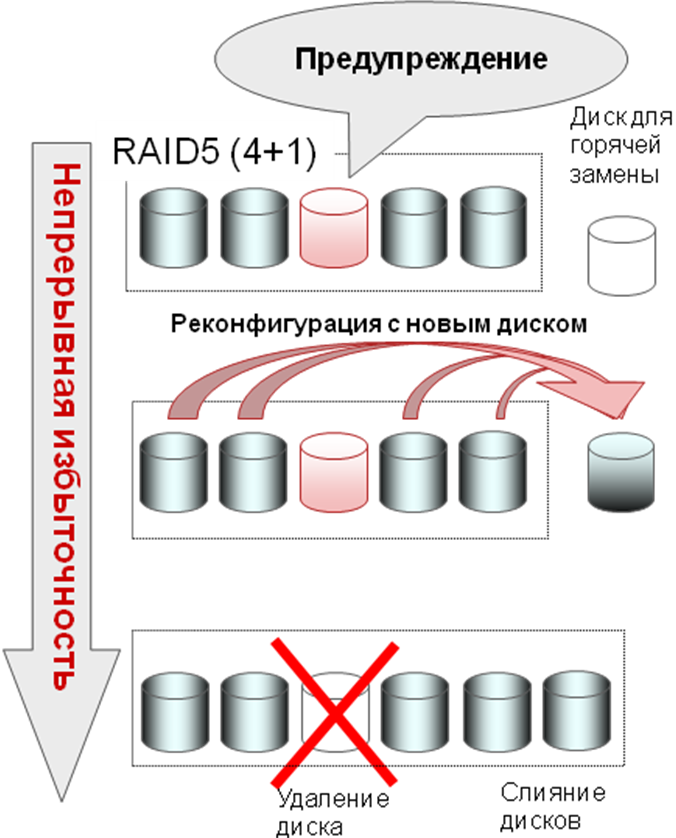
悪いシナリオの可能性を大幅に減らすために、ETERNUS DXに実装されているものを見てみましょう。 ディスクシステムは、ハードドライブの状態を常に監視します。 今日、ディスクからの平均応答時間の増加、ディスクが特定のブロックを初めて読み取り/書き込みできなかったときに繰り返される読み取り/書き込みサイクルの数の増加、Data Block Guardがトリガーされた回数、ディスクアレイ自体の増加など、かなりの兆候によるすべてのハードドライブからのこの情報の継続的な収集と分析の結果によれば、特定のハードドライブがまもなく故障することを非常に予測可能に予測できます。 そして、事前に、このドライブからホットスワップドライブへのデータ転送を開始します。 さらに、このプロセスの間、「疑わしい」ディスクは完全に読み取り可能なままであり、書き込み操作のみがブロックされ、新しいディスクにリダイレクトされます。 したがって、ディスクグループの信頼性は大幅に向上します。
さらに、そのようなイベントは完全に保証されたケースです。 ちなみに、すべてのETERNUS DXの標準保証は3年です。