
その他のパーツ: パート1 。 パート3 。
この投稿は、 「暗黒の「シリコン」の時代の生活」というストーリーの続きです。 前のパートでは、「ダーク」シリコンとは何か、なぜ登場したのかを説明しました。 「暗い」シリコンの時代にマイクロエレクトロニクスを繁栄させる4つの主要なアプローチのうち2つも検討されました。 生産技術分野での新たな発見の役割、並列処理によるエネルギー効率の向上方法、およびプロセッサクリスタルの面積を縮小できない可能性について説明されました。 今回は、次のアプローチがアジェンダにあります。
「The Dim Horseman」またはエネルギーおよび温度管理。
「チップに均一なコアを充填します
それは電力バジェットを超えるだろう
しかし、我々はそれらをアンダークロックします(空間調光)、
またはそれらをすべてバーストでのみ使用します(一時的な調光)
...「薄暗いシリコン。」
結晶面積が縮小する可能性は低いため、シリコンの「暗い」領域を効果的に使用する方法を検討します。 ここで、開発者には選択肢があります:汎用または特別な目的のロジックを使用しますか? 今回は、時間のごく一部で仕事に忙しく、幅広いタスクに使用できるユニバーサルロジックのバリアントを検討します。 ほとんどの場合、より低い周波数で動作するロジックの場合、調光シリコンという用語が使用されます。 [1]
「鈍い」シリコンの使用に関連するいくつかの設計方法を検討してください。
近しきい値電圧プロセッサ。 最近のアプローチの1つは、しきい値(Near-Threshold Voltage、NTV)に近い低電圧レベルで動作するロジックの使用です[2]。 このモードで動作するロジックは、絶対的なパフォーマンスの面では低下しますが、消費電力の単位ごとに最高のパフォーマンスを提供します。
前のパートでは、このアイデアは1つのコンパレータの例で検討されました。 その大きな用途について話すと、最近、SIMDプロセッサのNTV実装が注目を集めています[3]。 SIMDは、このアプローチで最も成功した並行性の形式です。 マルチコア[4]およびx86(IA32)[5] NTVプロセッサーについても研究しました。
NTVプロセッサのパフォーマンスは、1回の操作で対応するエネルギー節約よりも速く低下します。 たとえば、パフォーマンスが8倍低下し、全体の消費電力が40倍減少するか、各操作で5倍減少します。 パフォーマンスの損失は、より多くの並列プロセッサを使用することで補償できます。 ただし、これは完全な並列化を想定した場合にのみ有効であり、他のアーキテクチャよりもSIMDとの一貫性があります。
ムーアの法則に戻ると、NTVは生産性を5倍に高め、同じ消費電力を維持しながら、40倍の面積(約11世代のプロセステクノロジー)を使用できます。
NTVを使用すると、さまざまな技術的な問題が発生します。 これらの問題の1つは、プロセスパラメータの変動に対する回路の感度の増加です。 リソグラフィプロセスは、シリコン表面にトポロジの複数の層を適用することで構成されています( ドーピング )。 しかし、結果として生じる層の線の太さと幅はわずかに異なる場合があり、これはトランジスタのしきい値電圧の広がりにつながります。 動作電圧を下げると、トランジスタが動作できる周波数の広がりが大きくなります。 これは多くの不便をもたらします-通常、SIMDは緊密に同期された並列ブロックを使用しますが、このような状況では達成が困難です。
他の問題、たとえば、より低い電圧で動作するSRAMメモリを作成することの難しさがあります。
キャッシュの増加。 しばしば提案される代替案は、単純にシリコンの暗い領域を使用してキャッシュを配置することです。 結局のところ、プロセステクノロジの各世代について、1.4倍から2倍の速度でキャッシュが増加することは容易に想像できます。 キャッシュミスが頻繁に発生するタスクのキャッシュを大きくすると、パフォーマンスと経済性の両方が向上します。チップの外部のメモリにアクセスするには多くのエネルギーが必要です。 キャッシュミスの頻度は、主にキャッシュを増やすかどうかを決定します。 最近の調査によると、最適なキャッシュサイズは、システムパフォーマンスが帯域幅によって制限されなくなり、電力消費によって制限されるポイントによって決定されます。 [6]
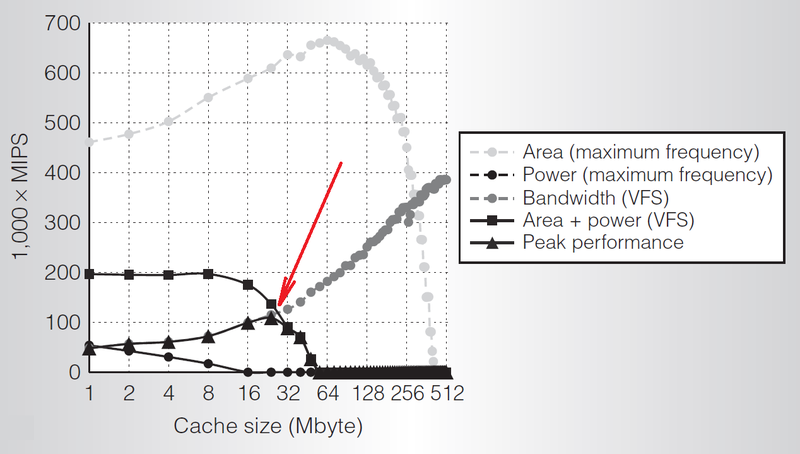
さまざまな制約の下でのパフォーマンスとキャッシュサイズ
ただし、非チップメモリインターフェイスはエネルギー効率が向上しており、3Dメモリ統合によりアクセスが高速化されています。 これは、大きなキャッシュサイズからの将来の利益を減らす可能性があります。
粗視化再構成可能アレイ。 再構成可能なロジックを使用することは新しいアイデアではありません。 しかし、ビットレベルでの使用は、FPGAで発生するように、高いオーバーヘッド消費電力に関連付けられています。 最も有望なオプションは、粗粒度の再構成可能な配列(粗粒度の再構成可能な配列、CGRA)の使用です。 このような配列は、単語全体に対して操作を実行するように構成されています。 アイデアは、論理要素を自然な計算順序に対応する順序で配置することです。これにより、信号接続の長さと通信回線の多重化に関連するコストを削減できます。 [7]さらに、CGRAのデューティサイクルは非常に小さく、ほとんどの場合、そのロジックは非アクティブであるため、「鈍い」ロジックとしての使用が魅力的です。
CGRAの分野での研究は以前に行われましたが、現在もダークシリコンの時代に続けられています。 この技術の商業的成功は非常に限られていたが、新しい問題はしばしば古いアイデアを新鮮に見ざるを得ない。 :)
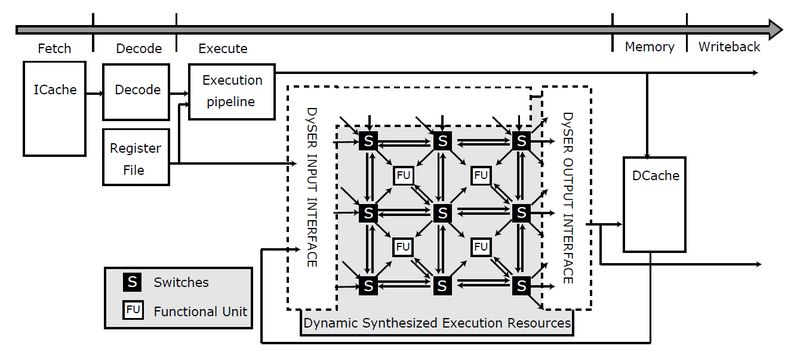
プロセッサの一部として再構成可能なアレイを使用する
計算スプリントとターボブースト。 上記のアプローチは、非常に低い周波数で動作するように、またはほとんどの部分がアイドル状態になるようにロジックの一部の領域が設計されている場合、シリコンの空間的調光を使用しました。 しかし、シリコンの一時的な調光に基づいた多くの方法があります。 たとえば、プロセッサは短い(1分未満)を提供できますが、クロック速度を上げることでパフォーマンスが大幅に向上します。 同時に、サーマルバジェットを一時的に超過します(〜1.2-1.3 TDP)が、温度を上げる手段として、チップとラジエーターの熱容量で計算されます。 しばらくすると、周波数は元の値に戻り、ラジエーターが冷えるようになります。 Turbo Boostテクノロジー[8]は、まさにこのアプローチを使用して、適切なタイミングで生産性を向上させます。
計算スプリント、およびターボブースト2.0バージョンは、元のアイデアと比較して一歩前進し、ほんの一瞬だけパフォーマンスを大幅に(約10倍)向上させることができます。

そして今、 少し練習して、根拠がないようにします。 これらのアプローチやその他のアプローチを使用して、最新のプロセッサーで達成できること。 空間的および時間的両方の調光のさまざまな方法を効果的に使用すると、エネルギー消費は負荷に応じて50倍以上変化する可能性があります。
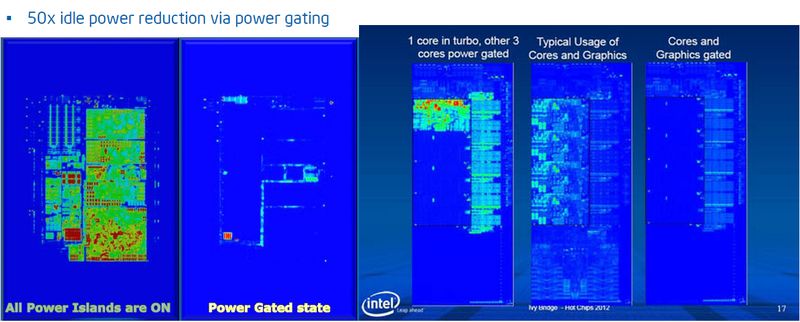
さまざまな電源構成のプロセッサの赤外線画像
ただし、これを提供するシステムは非常に複雑です。 対応する設計ソリューションに加えて、マイクロプロセッサには多くの温度センサーが含まれています(図の右側にある赤い点)。 たとえば、Sandy Bridgeでは、プロセッサコアごとに12個のセンサーがあり、かなりの数のセンサーがプロセッサコアの外部に配置されています。 さらに、プロセッサには、消費電力を制御するファームウェアを実行する専用ユニット(PCU-パッケージコントロールユニット)が含まれています。 同時に、温度センサーは温度制御だけでなく、たとえば漏れ電流を推定するためにも使用され、PCUには外部と通信するためのインターフェイスがあり、オペレーティングシステムとユーザーアプリケーションがデータを監視してエネルギー消費を管理できるようにします。

また興味深いのは、マルチコアプロセッサの次の機能です。 軽負荷では、冗長プロセッサコアをオフにしてエネルギーを節約できます。 ただし、Uncore(プロセッサコアを含まないプロセッサの部分-通信ファクトリ、共有キャッシュ、メモリコントローラなど)は無効にできません。 これにより、プロセッサが完全に停止します。 同時に、Uncoreの消費電力は、いくつかのプロセッサコアの消費電力に匹敵します。

アンコア
Uncoreクロック速度を制御することにより、必要なエネルギーを節約できます。 周波数が必要以上に高い場合(ポイント1)、Uncoreのパフォーマンス要件は完全に満たされますが、エネルギーが無駄になり、パフォーマンスを犠牲にすることなく周波数を下げることができます。 頻度が必要よりも低い場合(ポイント2)、パフォーマンスが低下するため、頻度を増やす必要があります。 私たちの目標は、現在の負荷に最適なポイント(ポイント3)を見つけて維持することです。 これは簡単ではありません、なぜなら 効率的な動作のためには、パフォーマンス要件を予測し、クロック周波数を事前に変更する必要があります。
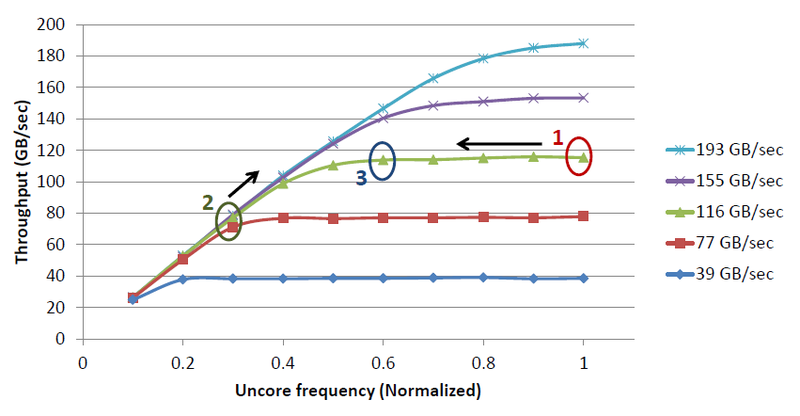
さまざまな負荷でのクロック速度からのパフォーマンス曲線をアンコア
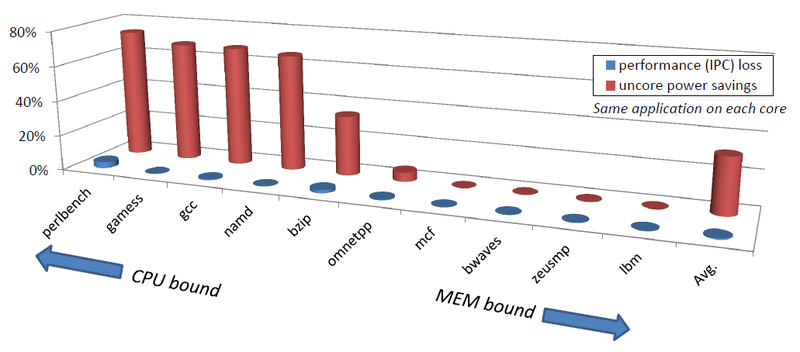
さまざまなタスクのパフォーマンスの低下とエネルギーの節約
さまざまなUncore周波数制御アルゴリズムは、たとえば、それぞれ31%のエネルギー節約を達成し、パフォーマンスのわずか0.6%、またはパフォーマンスの3.5%による73%の節約をそれぞれ達成できます。
継続する 。
ソース
1. W. Huang、K。Rajamani、M。Stan、およびK. Skadron。「設計上の制約によるスケーリング:ビッグチップの将来の予測」IEEE Micro、2011年7月。
2. R. Dreslinskiほか、「しきい値に近いコンピューティング:エネルギー効率の高い集積回路によるムーアの法則の再利用」。IEEE議事録、2010年2月。
3. Hsu、Agarwal、Anders et al。 「22nm CMOSでの2次元シャッフルを備えた280mvから1.2v 256bへの再構成可能なsimdベクトル置換エンジン。」2012年2月、ISSCC
4. D.フィック等。 「Centip3de:64アームcortex-m3コアを備えた3930 dmips / wの設定可能なしきい値に近い3dスタックシステム。」2012年2月、ISSCC
5. Jain、Khare、Yada et al。 「32nm CMOSの280mvから1.2vの広い動作範囲のia-32プロセッサ。」ISSCC、2012年2月。
6. N. Hardavellaset等。 「サーバーのダークシリコンに向けて」IEEE Micro、2011年。
7. V.ゴビンダラジュ、C.-H。 Ho、K。Sankaralingam。 「エネルギー効率の良いコンピューティングのための動的に特化したデータパス。」HPCA、2011年。
8. E. Rotem。 「第2世代のIntelコアマイクロアーキテクチャの電源管理アーキテクチャ、以前はコードネームがサンディブリッジでした。」Proceedings of Hotchips、2011年。