私のプロジェクトの1つは、プライベートクラウドのようなものを使用しています。 これらは、データストレージ用の複数のサーバーと、仮想化を担当するディスクレスのサーバーです。 先日、私はついに、このソリューションのディスクサブシステムの最大パフォーマンスを圧迫する問題に終止符を打ちました。 それは非常に面白く、いくつかの点でさえ-まったく予想外でした。 したがって、「ロシアで最初のクラウドプロバイダー」が登場する前の2008年に始まったhabrasocietyと無料水道メーターを送信するキャンペーンを共有したいと思います。
建築
仮想ハードディスクは、 AoEプロトコルを使用して、別個のギガビットネットワーク経由でエクスポートされます 。 要するに、これはネットワーク経由でATAコマンドの転送を直接実装することを提案したCoraidの発案です。 プロトコル仕様は数十ページしか必要としません! 主な機能は、TCP / IPの欠如です。 データを転送するとき、最小限のオーバーヘッドが得られますが、単純化のための料金として、ルーティングが不可能です。
なぜそのような選択ですか? 公式ソースの転載を省略した場合- そしてありふれた低コスト。
したがって、ストレージでは、7200 rpmの通常のSATAディスクを使用しました。 それらの欠陥は誰にでも知られています-低IOPS。
RAID10
ランダムアクセス速度の問題を解決するための最初で人気のある明白な方法。 mdadmを手に入れ、コンソールに適切なコマンドをいくつか実行し、LVMを最上位に上げ(結果として仮想マシンのブロックデバイスを配布します)、いくつかの素朴なテストを開始しました。
root@storage:~# hdparm -tT /dev/md127 /dev/md127: Timing cached reads: 9636 MB in 2.00 seconds = 4820.51 MB/sec Timing buffered disk reads: 1544 MB in 3.03 seconds = 509.52 MB/sec
正直に言うと、IOPSをチェックするのは怖かったです。SCSIに切り替えるか、独自の松葉杖を書く以外に、問題を解決するオプションはありませんでした。
ネットワークとMTU
ネットワークはギガビットでしたが、ディスクレスサーバーからの読み取り速度は予想される100MiB /秒に達しませんでした。 当然のことながら、ネットワークカードのドライバーは非難されるべきでした(こんにちは、Debian)。 メーカーのウェブサイトから新しいドライバーを使用すると、問題が部分的に修正されたようです...
すべてのAoE速度最適化マニュアルでは、最初の項目は最大MTUの設定を示しています。 現時点では4200でした。これはばかげているように見えますが、標準の1500と比較すると、線形読み取り速度は実際に約120MiB /秒に達しました。 また、すべての仮想サーバーによるディスクサブシステムの負荷が小さい場合でも、ローカルキャッシュによって状況が修正され、各仮想マシン内で線形読み取り速度は少なくとも50MiB /秒に保たれました。 実際、かなり良い! 時間が経つにつれて、ネットワークカードとスイッチを変更し、MTUを最大9Kに引き上げました。
MySQLが登場するまで
はい、24時間365日のプロジェクトのいくつかは、書き込みと読み取りの両方でMySQLをプルしました。 次のようになりました。
Total DISK READ: 506.61 K/s | Total DISK WRITE: 0.00 B/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 30312 be/4 mysql 247.41 K/s 11.78 K/s 0.00 % 11.10 % mysqld 30308 be/4 mysql 113.89 K/s 19.64 K/s 0.00 % 7.30 % mysqld 30306 be/4 mysql 23.56 K/s 23.56 K/s 0.00 % 5.36 % mysqld 30420 be/4 mysql 62.83 K/s 11.78 K/s 0.00 % 5.03 % mysqld 30322 be/4 mysql 23.56 K/s 23.56 K/s 0.00 % 2.58 % mysqld 30445 be/4 mysql 19.64 K/s 19.64 K/s 0.00 % 1.75 % mysqld 30183 be/4 mysql 7.85 K/s 7.85 K/s 0.00 % 1.15 % mysqld 30417 be/4 mysql 7.85 K/s 3.93 K/s 0.00 % 0.36 % mysqld
無害? どんなに。 小さなリクエストの巨大なストリーム、70%のioが仮想サーバーで待機、20%がストレージの各ハードディスク(上から)の負荷、残りの仮想マシンでのこのような退屈な画像:
root@mail:~# hdparm -tT /dev/xvda /dev/xvda: Timing cached reads: 10436 MB in 1.99 seconds = 5239.07 MB/sec Timing buffered disk reads: 46 MB in 3.07 seconds = 14.99 MB/sec
そして、それは速いです! 多くの場合、線形読み取り速度は1〜2 MiB /秒以下でした。
私たちが何に出会ったかは誰もがすでに推測していると思います。 RAID10であっても、低IOPS SATAドライブ。
フラッシュキャッシュ
これらの男たちは時間通りに登場しました! これは救いです、これは同じです! 人生は良くなっています、私たちは救われます!
インテルSSDの緊急購入、ストレージサーバーのライブイメージへのモジュールおよびフラッシュキャッシュユーティリティの組み込み、ライトバックキャッシュ設定、および目に見える火災。 ええ、すべてのカウンターはゼロです。 さて、LVM + Flashcacheの機能はGoogleで簡単に検索でき、問題はすぐに解決されました。
MySQLを使用する仮想サーバーでは、loadavgは20から10に低下しました。他の仮想マシンでの線形読み取りは、安定した15-20 MiB /秒に増加しました。 だまされてはいけません!
しばらくして、次の統計を収集しました。
root@storage:~# dmsetup status cachedev 0 2930294784 flashcache stats: reads(85485411), writes(379006540) read hits(12699803), read hit percent(14) write hits(11805678) write hit percent(3) dirty write hits(4984319) dirty write hit percent(1) replacement(144261), write replacement(111410) write invalidates(2928039), read invalidates(8099007) pending enqueues(2688311), pending inval(1374832) metadata dirties(11227058), metadata cleans(11238715) metadata batch(3317915) metadata ssd writes(19147858) cleanings(11238715) fallow cleanings(6258765) no room(27) front merge(1919923) back merge(1058070) disk reads(72786438), disk writes(374046436) ssd reads(23938518) ssd writes(42752696) uncached reads(65392976), uncached writes(362807723), uncached IO requeue(13388) uncached sequential reads(0), uncached sequential writes(0) pid_adds(0), pid_dels(0), pid_drops(0) pid_expiry(0)
読み取りヒット率:13、書き込みヒット率:3.大量の非キャッシュ読み取り/書き込み。 flashcacheは機能しましたが、十分な強度ではありませんでした。 数十の仮想マシンがあり、仮想ディスクの総容量はテラバイトを超えず、ディスクアクティビティは少なかった。 つまり キャッシュヒットのこのような低い割合-近隣アクティビティのためではありません。
洞察力!
これを見て100回目:
root@storage:~# dmsetup table cachedev 0 2930294784 flashcache conf: ssd dev (/dev/sda), disk dev (/dev/md2) cache mode(WRITE_BACK) capacity(57018M), associativity(512), data block size(4K) metadata block size(4096b) skip sequential thresh(0K) total blocks(14596608), cached blocks(3642185), cache percent(24) dirty blocks(36601), dirty percent(0) nr_queued(0) Size Hist: 512:117531108 1024:61124866 1536:83563623 2048:89738119 2560:43968876 3072:51713913 3584:83726471 4096:41667452
私のお気に入りの

この図は、最後の行であるブロックサイズごとの要求の分布のヒストグラムに基づいています。
みんな知っている
ハードドライブは通常512バイトブロックで動作します。 AoEとまったく同じです。 Linuxカーネル-各4096バイト。 flascacheのデータブロックサイズも4096です。
ブロックサイズが4096と異なるリクエストの数を合計すると、結果の数がフラッシュキャッシュ統計からのキャッシュされていない読み取り+キャッシュされていない書き込みの数と疑わしく一致することが明らかです。 4Kブロックのみがキャッシュされます! 最初にMTUが4200だったことを覚えていますか? これからAoEパケットヘッダーのサイズを引くと、3584でデータブロックのサイズが得られます。したがって、ディスクサブシステムへの要求は、少なくとも2つのAoEパケット(3584バイトと512バイト)に分割されます。 これは、私が見た元の図にはっきりと表示されていました。 この記事の図でも、512バイトのパケットの優位性が顕著です。 また、9Kのすべてのコーナーで推奨されるMTUにも同様の問題があります:データブロックのサイズは8704バイトであり、2 4Kブロックと512バイトごとに1つです(これはまさに記事の図で見られます)。 間抜け! その解決策は誰にとっても明らかだと思います。
MTU 8700
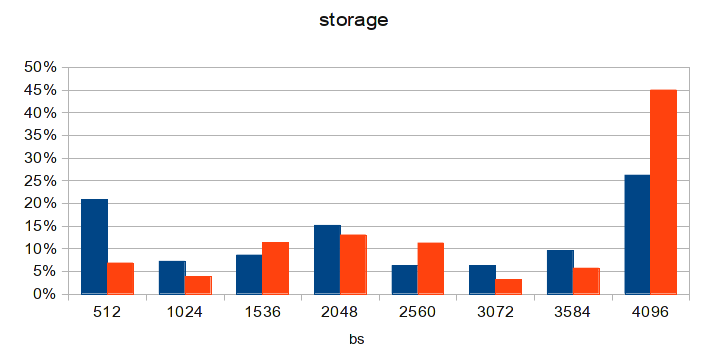
この図は、ディスクレスノードの1つで構成を更新した数日後に作成されます。 他のMTUを更新すると、状況はさらに良くなります。 また、MySQLを使用した仮想サーバーでのloadavgは3に低下しました。
おわりに
20年の経験を持つシステム管理者ではなく、適切な時期にコミュニティに知られている「標準」で最も一般的なアプローチを使用して問題を解決しました。 しかし、現実の世界では、常に不完全さ、松葉杖、仮定の余地があります。 実際、私たちはそれに遭遇しました。
ここにそのような物語があります。