この記事では、テキストマイニングの分野での私の研究活動の小さな結果についてお話したいと思います。 これらの「結果」は小さなフレームワークであり、これまでのところあまり良くありませんが、成長しています=)。 このプロジェクトは、私が開発した理論的規定のいくつかを実際に実装したものです。 この結果として、すべてのアイデアの実装の最後に彼が潜在的に持つ可能性のある機会を提示します。 この作成は「テキストマイニングフレームワーク」(TextMF)と呼ばれます。 TextMFが最初の最終バージョンで許可する内容と、現在機能している機能を簡単に確認します。
最終バージョンにする必要があります :
- 統計テキスト分析;
- テキスト内のすべての単語および各単語の単語形式を検索します。
- テキスト内の重みによる単語のランク付け。
- 問題のテキストの主題を検索します。
- テキスト内の主題間のリンク(直接リンクと非直接リンク)。
- テキストの抽象化。
- テキストの主題の定義。
- 語学研修;
- コミュニケーション(チャット)によるユーザーとの対話の編成。
すでに実装されています(一部利用可能またはテスト中) :
- テキストの統計分析(これまでのところ、非常に部分的に実装されています)。
- テキスト内のすべての単語と単語形式を検索します。
- 特定のテキスト内の重みで単語を並べ替えます。
- テキスト内の人を検索します。
- テキストのトピックの定義(式のテストと整列)。
別のテキスト処理ライブラリを使用する理由
実際、このプロジェクトの目標は、あらゆる種類のテキスト処理アルゴリズム( Python NLTKなど)を実装できるツールを作成することではなく、既成のアルゴリズムを使用できるようにすることです。 同時に、実際に独自のアルゴリズムをテストします。 つまり これは、別の統計アナライザーでも、テキストデータを操作するために最適化された一連のコンテナーでもありません。 いや! これは、追加の知識を必要とせずにそのまま使用できる一連のヒューリスティックです。
TextMFはどの入力データと連携しますか:これまではテキストファイルのみです。 言うまでもなく、はるかに大きな入力形式のさらなるサポートが計画されています。 また、Webページと穏やかに分析できるように、Webとの統合を行うことも計画されています。
外観とパスワード
プロジェクトは、 BitBucketリポジトリを介して配布されます。
自分自身に曲げてプロジェクトに接続します=)すべてが非常に簡単です。 すぐに、プラグインjar形式のアセンブリが利用可能になります。
使用例
テキスト処理は、多くの場合、特に本全体を開こうとすると、非常に時間がかかります! そのため、試してみるために、サイトのいくつかのページテキストに限定することを強くお勧めします。 ただし、非常に小さなテキストでも、情報が不十分なため、あまり良い結果が得られない場合があります。
前述のように、主なアイデアは、最大限の使いやすさと、ヒューリスティックとアルゴリズムの非表示です。 だから、すべてが些細です:
// , TEXT_FILE_NAME Text text = new Text(TEXT_FILE_NAME); // List<Word> words = text.getWords(); // List<Word> theme = text.getThem(); // Word word = words.get(0); // List<String> wordForms =word.getWordForms(); // long count = word.getCount(); // , List<Word> objects = text.getObjects(); // double weight = text.getWordWeight(word);
繰り返しますが、トピックの取得はかなり長い手順なので、このメソッドを呼び出すときは注意してください;)トピックを取得する非同期メソッドは、それ自体で実装されますが、後で実装されます。 提出されたテキストのサイズに応じて、メソッドの作業の質が向上することに注意することも非常に重要です。 原則として、情報が多いほど、言語を学ぶ機会が増えます。 ただし、コンテンツのサイズが大きくなると、ファイルを開く時間は大幅に長くなります。
小さなUIプログラム
プログラムの機能の一部を説明するために、Andreiという同僚が小さなUIクライアントを作成しました。 現在の段階では、使用する方が便利な場合があるため、あくまでもガイダンス用です。 Java FXで記述されており、個別のjarファイルとしてまだ配布されていません。 それを「感じる」ためには、それを収集する必要があります=(。
プログラムのメインウィンドウ:
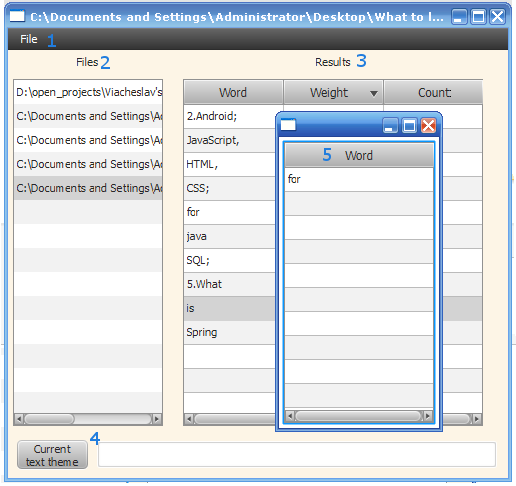
1)処理するテキストを選択するメニュー。
2)選択したファイルのリスト。
3)仕事の結果:
a)テキストで見つかった単語。
b)テキスト内の単語の重み。
c)テキストの繰り返し回数
4)テキストトピックを表示するフィールド。
5)単語形式のリスト。
このテキストのプログラムを使用して何を見つけることができるか見てみましょう: VolgaとMuscovitesの所有者には、もう1年が与えられます :
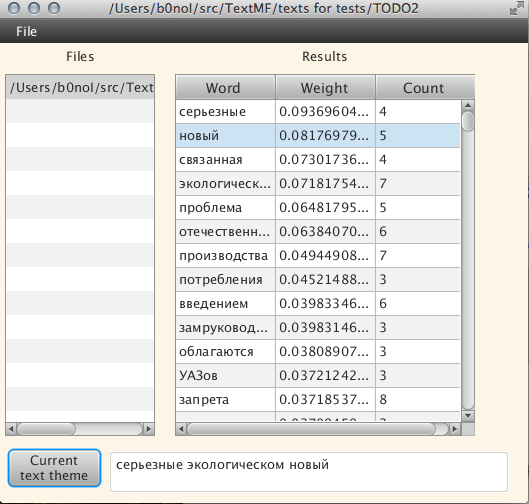
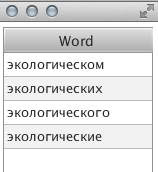
トピックは約1分間検索されました(長く同意します)。 単一の単語を選択すると、その単語形式が表示されます。

またはここ:
そして、別のテキストを試してみましょう。「 エイリアンはウクライナ人の家族を誘aし、地球人の未来について話しました! 「、おそらく最も「黄色い」テキストの1つ=):
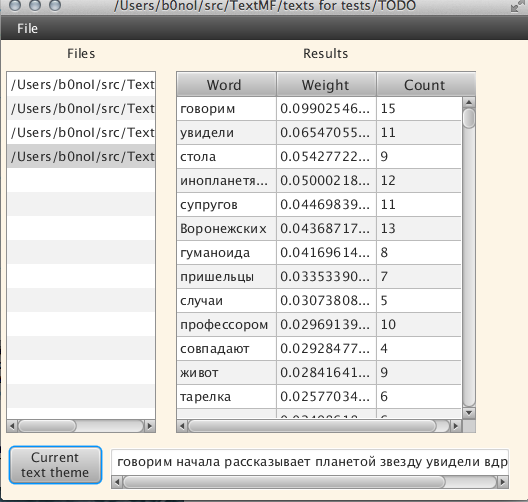
テキストは長い間、おそらく1分間開いたので、同じようにどこかでトピックを検索しました。 もちろん、テキストテーマは、アルゴリズムがテキストトピックと見なす一連の単語として理解される必要があります。 将来的には、アルゴリズムは読み取り可能な形式で出力を生成できるようになりますが、これは未来であり、現在は
あなたの助けが必要です
もちろん、本当に、本当にあなたの助けが必要です! 多くのタスクがありますが、プロジェクトは無料です。 タスクは最も単純なものから始まります:サイトに従事し、サンプルを記述し、ドキュメントコードを、最もハードコアに:マットの最適化を支援します。 装置とそれを精製します。 さて、たとえば、入力形式を拡張する問題に取り掛かり、単なるテキストファイル以上のことをする人がいると便利です。 テストの支援も非常に重要です。 プロジェクトにはドメインがあります: www.textmf.com 、しかしそこは空です、そして誰かがこれを修正するのを手伝ってくれたらとても幸せです=)
協力の申し出については、こちらまでご連絡ください: Viacheslav@b0noI.com
即時計画
プロジェクトで近い将来(1〜2か月以内に)起こることから:
- jarファイルアセンブリを追加します。
- プロジェクトはコアとUIに分割されます。 リポジトリがもう1つ追加されます。
- 長期記憶の実装が開始されます。
- 人と人との関係の分析;
- テキストを要約することが可能になります。
- UIを備えた自己完結型jarを作成します。
遠い計画
TextMFはwww.ukrinnovation.comプロジェクトの準決勝進出者になりました。 したがって、小規模ではありますが、それでも開発投資を得るチャンスがあります。
私はこれまでこれが夢であることを知っていましたが、最後にどの機能を見るか尋ねられたら、チューリングテストに合格するチャットボットを作成できるライブラリを答えます。 もっとリアルに話せば、インターネット上の情報を動的に追跡するための最も可能性の高いエンジンです。 リンクを追跡し、その変更を監視します。 もちろん、ローカル検索エンジンを作成するものです。
アイデア自体には大きな可能性があります。スパムフィルター、検索エンジン、自動参照システムなど、このようなフレームワークに基づいて構築できるその他の多くのものがあります。
TextMF作成者:
あなたの謙虚な使用人ヴャチェスラフVコバレフスキーと
UI開発者Andrey Prischepa(vinglfm@gmail.com)