2002年にYandexが画像の検索を開始したとき、コンピューターが画像内のオブジェクトを直接「見る」ことを可能にする技術はありませんでした。 彼らは現在登場していますが、これまでのところ、コンピューターが顔のマリリンモンローを認識したり、写真で森を認識したり、要求に応じてすぐに表示したりするには、開発の程度が十分ではありません。 したがって、最初の段階で発明されたこれらの方法を改善するタスクは引き続き重要です。
そのため、コンピューターは、写真に示されている内容を理解する必要があります。 彼は「見る」方法を知りませんが、同時にテキスト文書をよく探している技術があります。 そして、私たちを助けるのは彼らです。インターネット上の画像には、ほとんどの場合、何らかのテキストが付随しています。 彼は必ずしも写真に示されているものを直接説明するわけではありませんが、ほとんどの場合、意味と内容でそれに関連付けられています。 つまり、アインシュタインの写真の隣に彼の姓が記載されている可能性が高いと仮定します。 このようなテキストを地図作成と呼びます。
このデータに基づいて、コンピューターは要求に応じてユーザーに表示するドキュメントを理解します[ Marilyn Monroe ]。 その結果、検索結果では、関連する画像のサムネイルが表示されるか、サムネイルとも呼ばれます。 同じ画像のコピーでも同じです。 ここから私たちの名前が現れました-タンブラーの複製。 本質的に同一の写真は、サイズや圧縮の程度が異なる場合がありますが、これにより画像の内容は変わりません。 また、写真に変更を加えることもできます。 たとえば、透かしやロゴの追加、色の変更、切り抜きなどです。 しかし、これはこのイメージを新しいと考えるには十分ではありません。 私たちのタスクは、写真の検索結果を含むページ上に重複するサムネイルが存在しないことを確認し、コピーの各グループについて、それらすべてを組み合わせて表示することです。
写真のテキストのデータから、写真でマリリン・モンローが見つかったことが明らかになりました。 しかし、どれが重複しているかを判断するためのいくつかはありません。 そしてこの段階では、既存のコンピュータービジョンテクノロジーが役立ちます。
子供が両親のようだと言うとき、それはしばしば「父の鼻」または「母の目」のように聞こえます。 つまり、私たちは子供の中で保たれている両親のいくつかの顔の特徴に注意します。
しかし、同様の原則を使用するようにコンピューターに教えようとするとどうなりますか? この場合、最初の段階で、彼は絵のどの点を見るべきかを理解しなければなりません。 これを行うには、輪郭を強調するのに役立つ特別なフィルターを使用して画像を処理します。 それらを使用して、コンピューターは画像自体の変更で変化しないキーポイントを見つけ、それらの周囲にあるものを調べます。 コンピュータがこれらのフラグメントを「考慮する」ためには、それらをデジタル形式に変換する必要があります。 そのため、画像が引き伸ばされたり、回転されたり、他の何らかの変換が行われたりしても、説明はそのままです。 実際、ある程度、コンピューターをトレーニングして、人が見ているように画像を見るようにします。
その結果、各写真はその重要なポイントにあるものの説明のセットを受け取ります。 そして、ある画像のこれらの領域の多くが別の画像の多くの領域に類似している場合、一般的な類似度について結論を出すことができます。
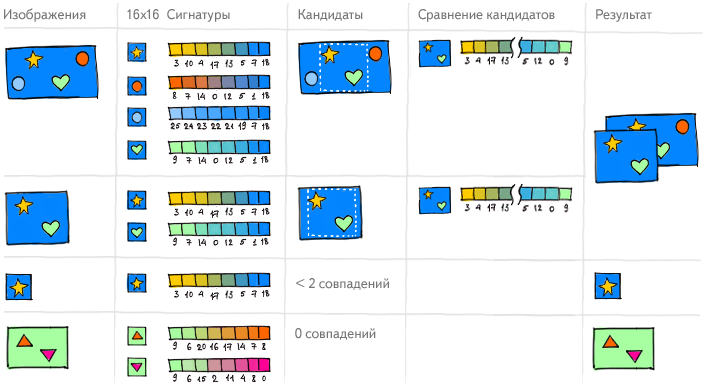
しかし、問題があります。 画像が何であるかを知らずに画像が重複していると判断することは不可能です。 面積の5%だけを変更することでそれらを考慮できると判断することができますが、ゲームの開始前と1つか2つの動きの後のチェス盤の写真を想像してください。 これらは異なる写真ですが、正式に変更されたのは5%以下です。 また、たとえば、同じ位置のチェスボード画像の1つにロゴが追加された場合、それらも5%異なりますが、同時に重複したままになります。 はい、ある程度コンピューターに写真を見るように教えましたが、これまでのところ、画像の対象領域の完全な理解には至っておらず、この問題の解決に取り組んでいます。
上記のすべての操作は、各画像にインデックスを付けて実行する必要があり、インデックスにはすべて100億の画像があります。 そして、これは最終的な数字ではありません。 古いアルゴリズムを使用してインターネット上のコンテンツの成長率を一致させるには、信じられないほど迅速にリソースを増やす必要があります。 当然、このインフラストラクチャの問題に対するより合理的なソリューションを見つける必要がありました。 そして、私たちはそれを行うことができました。
現在、たとえば、毎日Yandex.Picturesを通過する1,000万の新しいイメージを追加して処理するために、データベースに既に存在する数十億のプロセスを再起動する必要はありません。
さらに、インターネット上の一部の画像が相互のコピーであるという情報は、大きな検索結果でWebドキュメントをランク付けするのに役立ちます。 リンクのような同一の画像は、ドキュメントをリンクします。 これにより、このページまたはそのページが検索クエリに応答することの価値を考慮することができます。 したがって、上記の技術はYandex.Picturesだけでなく、原則として検索にも重要です。
そして、写真の検索に直接戻ると、それはもう1つの偶発的なタスクです。これは重複を接着することで解決します-画像テキストを伴わない場合でも同様の画像を見つけることができます。 これは、この形式で写真が人に必要な品質に対応している場合に役立ちます。