問題の声明
2次元熱方程式は次の方程式で与えられます。
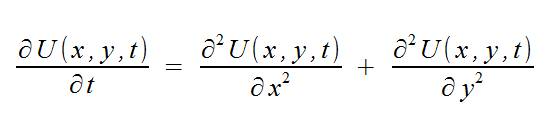
初期条件と同様に:
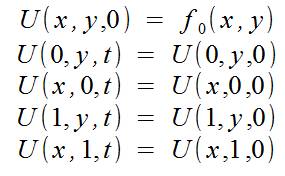
また、スペースの限られた領域を計算することも考慮します。

計算の結果は、特定の時間のノードでの関数Uの値を含む2次元配列になります。 方程式を解析的に解くことは可能ですが、これは選択肢ではないため、この問題を数値的に解きます。 数値解法では、時間で離散化を行い、空間で座標グリッドを取得し、時間で「レイヤー」のセットを取得します。 計算には、「クロス」スキームを使用します。
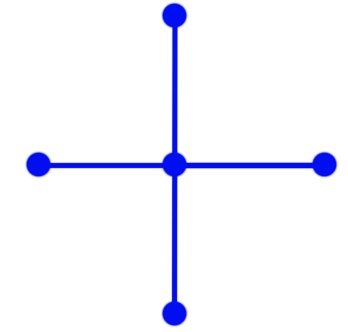
このスキームの詳細に立ち入らない場合、ある「タイムレイヤー」の「クロス」のすべてのポイントの値によって、「次のタイムレイヤー」の中心点の値を取得します。 さらに、時間と座標のステップは一貫している必要があります。
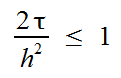
(以降、グリッドは固定され、空間座標に沿ったステップはhに等しくなります)
メモリを節約するために、現在のタイムレイヤー用と次のタイムレイヤー用の2つのグリッドのみをXとYに保存できます。 この場合、次のタイムレイヤーを計算した後、このレイヤーが現在のレイヤーになり、次のタイムレイヤーの値が最後のレイヤーの配列に書き込まれます。
幾何学的平行度法
幾何学的並列性の方法は、幾何学的な規則性を強調し、それを使用してプロセッサー間で作業を分割できる問題に使用されます。 この問題では、限られたスペースのグリッドは次のように表すことができます。

この場合、並列性は非常によくトレースでき、配列を複数に分割し、計算用の新しい配列をそれぞれエグゼキューターに渡すことができます。
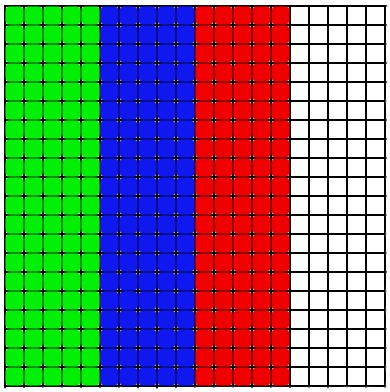
実際、配列を水平ストライプに分割することは可能です。メソッドの基本的な違いはありませんが、実装の違いについては後で説明します。 したがって、各請負業者は、配列の独自のセクションのみを考慮します。
落とし穴
計算を実行する差分スキームに戻ると、これが最後ではないことが明らかになります。 図からわかるように、メッシュ要素を計算するには、前のレイヤーでその側の要素を知る必要があります。 これは、空間グリッドの極値レイヤーを計算できないことを意味します(十分なデータがないため)が、境界条件を見ると、条件から極値要素がわかっていることがわかります。 しかし、出演者の領域の境界上の要素を計算する問題があります。 このプロセスでは、近隣のアーティスト間でデータを送信する必要があることは明らかです。 これは、要素を渡すループの形式で実行できます。
for (int i = 0; i < N; i ++) { MPI_Send(*buf, 1, MPI_DOUBLE, toRank, MESSAGE_ID, MPI_COMM_WORLD); }
(要素による送信の詳細については、冒頭に記載した記事をご覧ください)
多くの接続を確立する必要があるため、この方法は効果的ではありません(これには多くの時間がかかります)。 カスタムデータ型を作成すると、ニーズを満たすことができます。 カスタム構造の作成に加えて、MPIはデータのいくつかのタイプの「マスク」を提供できます:MPI_Type_contiguousおよびMPI_Type_vector。 最初のものは、メモリ内にある行のいくつかの要素を記述するタイプを作成し、2番目のものは、「必要な」要素をメモリ内に連続して配置された要素から選択し、「不要な」要素をスキップして必要な要素を繰り返す「テンプレート」を作成できます それらの数は固定されています。
// - , // - "" // - , MPI_Datatype USER_Vector; MPI_Type_vector(N, 1, N, MPI_DOUBLE, &USER_Vector); // "" MPI_Type_commit(&USER_Vector);
このタイプを送信し、* bufが配列の始まりを示す場合、以下を取得します。
+ 0 0
+ 0 0
+ 0 0
配列の2番目の要素として* bufを指定すると、次のようになります。
0 + 0
0 + 0
0 + 0
したがって、配列の1列のみを送信(および受信)し、1回の呼び出しでMPI_SENDを実行できます。
MPI_Send(*buf, 1, USER_Vector, (rank + 1), MESSAGE_ID, MPI_COMM_WORLD);
アーティストゾーンを水平方向に配置する場合、MPI_Type_contiguousを使用するか、MPI_Sendで必要な要素数を指定できますが、これは私の意見ではより美しいです。
次に、これらの列を転送する順序を理解する必要があります。 最も明白なのは、パフォーマーが目的の列を順番に正しい受信者に渡すようにすることです。 次に、次の図を取得します。
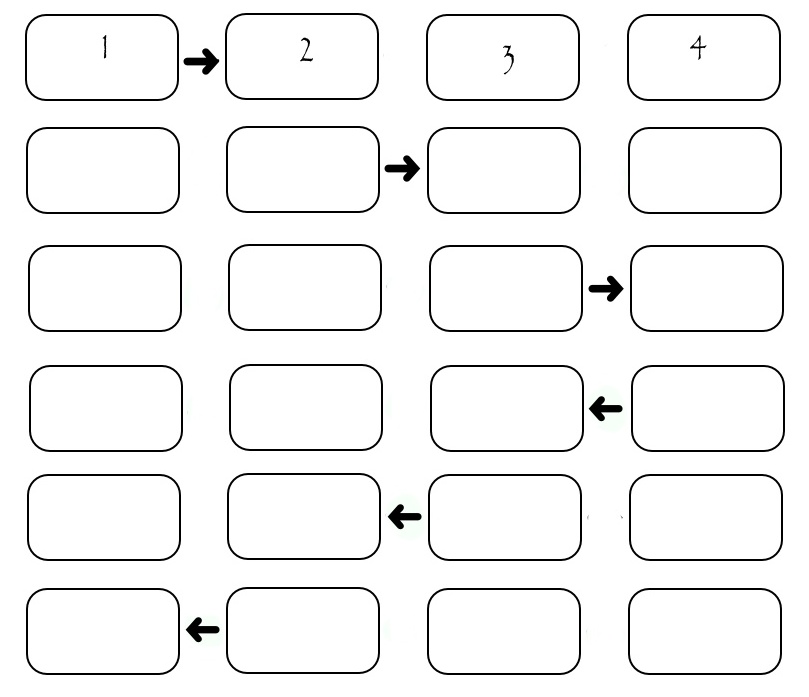
この図は4人のパフォーマー間の交換を示していますが、特定のSEND_TIMEが1回の送信に費やされる場合、すべての列を転送するには(2 * N-2)* SEND_TIMEが必要であると計算できます。 各列の送信中、2人のパフォーマーのみが「動作」し、残りはアイドル状態にあることがわかります。 これは良くありません。 少し変更されたスキームを考えてみましょう。その中で、パフォーマーは「パリティ」番号で分割されます。 最初に、すべての偶数が大きい番号のパフォーマーに列を渡し、次にすべての偶数が低い番号のパフォーマーに列を渡し、次に奇数のパフォーマーが同じことを行います。 もちろん、すべての転送は、転送先が存在する場合にのみ発生します。
// EVEN_RIGHT, ODD_RIGHT, ODD_LEFT, EVEN_LEFT - // ( , ) const int ROOT = 0; if ((rank % 2) == 0) { if (rank != (size - 1)) MPI_Send(*buf, 1, USER_Vector, (rank + 1), EVEN_RIGHT, MPI_COMM_WORLD); if (rank != ROOT) MPI_Recv(*buf, 1, USER_Vector, (rank - 1), ODD_RIGHT, MPI_COMM_WORLD, &status); if (rank != (size - 1)) MPI_Recv(*buf, 1, USER_Vector, (rank + 1), ODD_LEFT, MPI_COMM_WORLD, &status); if (rank != ROOT) MPI_Send(*buf, 1, USER_Vector, (rank - 1), EVEN_LEFT, MPI_COMM_WORLD); } if ((rank % 2) == 1) { MPI_Recv(*buf, 1, USER_Vector, (rank - 1), EVEN_RIGHT, MPI_COMM_WORLD, &status); if (rank != (size - 1)) MPI_Send(*buf, 1, USER_Vector, (rank + 1), ODD_RIGHT, MPI_COMM_WORLD); MPI_Send(*buf, 1, USER_Vector, (rank - 1), ODD_LEFT, MPI_COMM_WORLD); if (rank != (size - 1)) MPI_Recv(*buf, 1, USER_Vector, (rank + 1), EVEN_LEFT, MPI_COMM_WORLD, &status); }
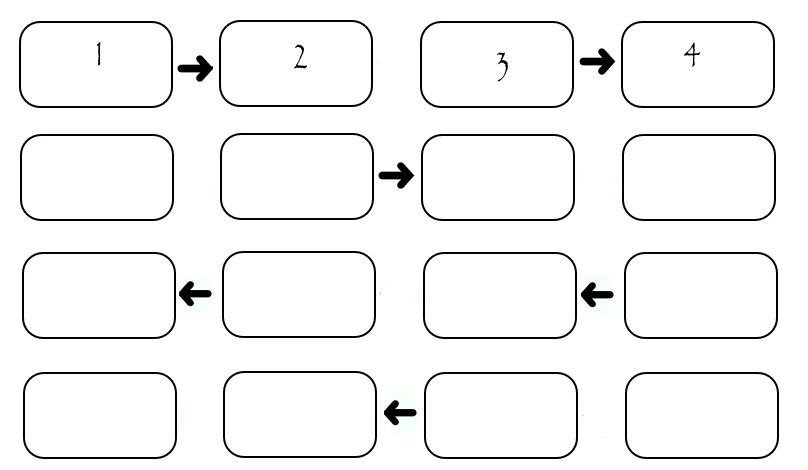
この場合、実行者の数に関係なく、転送には正確に4 * SEND_TIMEかかります。 多くのパフォーマーがいるシステムでは、これは非常に優れています。
(転送に関する数字には、嘘のようなものがあります。演奏者の数は配列のようにゼロから始まり、数字では「通常の」順序で番号が付けられます。最初から数えます。