基本の研究に関する最初のレッスンに続いて、RabbitMQは公式サイトから2番目のレッスンの翻訳を公開します 。 前述のように、すべての例はpythonで記述されていますが、ほとんどの一般的な言語で実装できます 。
タスクキュー
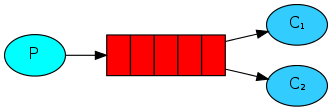
最初のレッスンでは、2つのプログラムを作成しました。1つはメッセージを送信し、2つ目はメッセージを受信しました。 このレッスンでは、リソースを集中的に使用するタスクを複数のサブスクライバーに分散するために使用されるキューを作成します。
このようなキューの主な目的は、タスクをすぐに開始せず、完了するまで待たないことです。 代わりに、タスクが遅延します。 各メッセージは1つのタスクに対応しています。 バックグラウンドで実行されているハンドラープログラムは、処理のためにタスクを受け入れ、しばらくすると完了します。 複数のハンドラーを実行すると、タスクはそれらの間で分割されます。
この動作原理は、HTTP要求時にリソースを大量に消費するタスクを処理できないWebアプリケーションで使用する場合に特に役立ちます。
準備する
前のレッスンでは、「Hello World!」というテキストを含むメッセージを送信しました。 そして、リソースを集中的に使用するタスクに対応するメッセージを送信します。 画像のサイズ変更やPDFファイルのレンダリングなどの実際のタスクは実行しません。time.sleep()関数を使用してスタブを作成しましょう。 タスクの複雑さは、メッセージ行のポイントの数によって決まります。 各ポイントは1秒間「実行」されます。 たとえば、メッセージ「Hello ...」を含むタスクは3秒間実行されます。
コマンドラインから任意のメッセージを送信できるように、 前の例 のsend.pyプログラムコードをわずかに変更します。 このプログラムは、新しいタスクを計画して、順番にメッセージを送信します。 new_task.pyと呼びます:
import sys message = ' '.join(sys.argv[1:]) or "Hello World!" channel.basic_publish(exchange='', routing_key='hello', body=message) print " [x] Sent %r" % (message,)
前の例のreceive.pyプログラムも変更する必要があります。メッセージテキストの各ポイントに1秒間、有用な作業の実装をシミュレートする必要があります。 プログラムはキューからメッセージを受信し、タスクを完了します。 worker.pyと呼びます:
import time def callback(ch, method, properties, body): print " [x] Received %r" % (body,) time.sleep( body.count('.') ) print " [x] Done"
周期的分布
タスクキューを使用する利点の1つは、複数のプログラムと並行して作業できることです。 すべての着信タスクを完了する時間がない場合は、単純にハンドラーの数を追加できます。
まず、2つのworker.pyプログラムを一度に実行しましょう。 どちらもキューからメッセージを受信しますが、どのくらい正確ですか? 今から見ます。
3つのターミナルウィンドウを開く必要があります。 そのうち2 つでは 、 worker.pyプログラムが起動します。 これらは、C1とC2の2つのサブスクライバーになります。
shell1$ python worker.py [*] Waiting for messages. To exit press CTRL+C
shell2$ python worker.py [*] Waiting for messages. To exit press CTRL+C
3番目のウィンドウで、新しいタスクを公開します。 サブスクライバーが開始された後、任意の数のメッセージを送信できます。
shell3$ python new_task.py First message. shell3$ python new_task.py Second message.. shell3$ python new_task.py Third message... shell3$ python new_task.py Fourth message.... shell3$ python new_task.py Fifth message.....
サブスクライバーに配信されたものを見てみましょう。
shell1$ python worker.py [*] Waiting for messages. To exit press CTRL+C [x] Received 'First message.' [x] Received 'Third message...' [x] Received 'Fifth message.....'
shell2$ python worker.py [*] Waiting for messages. To exit press CTRL+C [x] Received 'Second message..' [x] Received 'Fourth message....'
デフォルトでは、RabbitMQは新しい各メッセージを次のサブスクライバーに転送します。 したがって、すべてのサブスクライバーは同じ数のメッセージを受け取ります。 このメッセージ配信方法は、サイクリック[ ラウンドロビンアルゴリズム]と呼ばれます。 3人以上のサブスクライバーで同じことを試してください。
メッセージ確認
これらのタスクには数秒かかります。 おそらく、ハンドラーがタスクを開始したが、予期せず動作を停止し、部分的にしか完了しなかった場合にどうなるかを既に疑問に思っているかもしれません。 プログラムの現在の実装では、メッセージはRabbitMQがサブスクライバーに配信するとすぐに削除されます。 したがって、操作中にハンドラーを停止すると、タスクは完了せず、メッセージは失われます。 まだ処理されていない配信メッセージも失われます。
しかし、タスクを失いたくありません。 あるハンドラーの緊急出口が発生した場合、メッセージは別のハンドラーに送信される必要があります。
失われたメッセージがないことを確認できるように、RabbitMQはメッセージ確認をサポートしています。 確認( ack )は、受信したメッセージが処理され、RabbitMQがそれを削除できることをRabbitMQに通知するために、サブスクライバーによって送信されます。
サブスクライバーが動作を停止し、確認を送信しなかった場合、RabbitMQはメッセージが処理されていないことを理解し、別のサブスクライバーに転送します。 そのため、ハンドラープログラムの実行が予期せず停止した場合でも、1つのメッセージが失われないことを確認できます。
メッセージを処理するためのタイムアウトはありません。 RabbitMQは、最初のサブスクライバーへの接続が閉じられている場合にのみ、それらを別のサブスクライバーに転送するため、メッセージの処理時間に制限はありません。
デフォルトでは、メッセージの手動確認が使用されます。 前の例では、 no_ack = Trueを指定してメッセージの自動確認を強制しました。 ここで、このフラグを削除し、タスクが完了した直後にハンドラーから確認を送信します。
def callback(ch, method, properties, body): print " [x] Received %r" % (body,) time.sleep( body.count('.') ) print " [x] Done" ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue='hello')
これで、メッセージの処理中にCtrl + Cを押してハンドラーを停止しても、何も失われません。 ハンドラーが停止した後、RabbitMQは未確認のメッセージを再送信します。
メッセージを確認することを忘れないでください
開発者は、コードにbasic_ackを追加するのを忘れることがあります。 この小さなエラーの結果は重大な場合があります。 メッセージはハンドラープログラムが停止したときにのみ再送信されますが、RabbitMQはより多くのメモリを消費します。 未確認のメッセージは削除されません。
これらの種類のエラーをデバッグするには、 rabbitmqctlを使用して、 messages_unacknowledgedフィールド(未確認メッセージ)を表示できます。
$ sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged Listing queues ... hello 0 0 ...done.
[または、 最初の部分で引用したより便利な監視スクリプトを使用する]
メッセージの安定性
サブスクライバーが予期せず動作を停止した場合に、タスクを失わない方法を見つけました。 ただし、RabbitMQサーバーが動作を停止すると、タスクは失われます。
デフォルトでは、RabbitMQサーバーが停止またはクラッシュすると、すべてのキューとメッセージが失われますが、この動作は変更できます。 サーバーの再起動後にメッセージがキューに残るためには、キューとメッセージの両方を安定させる必要があります。
まず、キューが失われないことを確認します。 これを行うには、それを持続可能( 永続的 )として宣言する必要があります。
channel.queue_declare(queue='hello', durable=True)
このコマンド自体は正しいですが、 helloキューがすでに不安定であると宣言されているため、現在は機能しません。 RabbitMQでは、既存のキューのパラメーターをオーバーライドすることはできません。これを行うと、エラーが返されます。 しかし、簡単な回避策があります-別の名前、たとえばtask_queueでキューを宣言しましょう:
channel.queue_declare(queue='task_queue', durable=True)
このコードは、プロバイダープログラムとサブスクライバープログラムの両方で修正する必要があります。
したがって、RabbitMQサーバーの再起動時にtask_queueキューが失われないことを確認できます。 次に、メッセージを回復力があるものとしてマークする必要があります。 これを行うには、 delivery_modeプロパティに値2を 渡します。
channel.basic_publish(exchange='', routing_key="task_queue", body=message, properties=pika.BasicProperties( delivery_mode = 2, # make message persistent ))
メッセージの安定性に関する注意
メッセージを持続可能としてマークしても、メッセージが失われないという保証はありません。 これにより、RabbitMQがメッセージをディスクに保存するように強制されるという事実にもかかわらず、RabbitMQがメッセージの受け入れを確認したがまだ記録していない短時間があります。 また、RabbitMQは各メッセージに対してfsync(2)を実行しないため、一部のメッセージはキャッシュできますが、まだディスクに書き込まれません。 メッセージの安定性の保証は完全ではありませんが、タスクキューには十分です。 より高い信頼性が必要な場合は、トランザクションをトランザクションにラップできます。
メッセージの均一な配布
必要に応じてメッセージ配信がまだ機能しないことに気づいたかもしれません。 たとえば、2人のサブスクライバーが働いているときに、すべての奇数のメッセージに複雑なタスクが含まれている場合( 完了までにかなりの時間が必要)、単純なメッセージにも単純なタスクが含まれている場合、最初のハンドラーは常にビジー状態になり、2番目のほとんどの時間は無料になります。 しかし、RabbitMQはそれについて何も知らず、引き続きサブスクライバーにメッセージを送信します。
これは、RabbitMQがキューに入った瞬間にメッセージを配信し、サブスクライバーからの未確認メッセージの数を考慮しないためです。 RabbitMQは、n番目のサブスクライバーにn番目ごとのメッセージを送信するだけです。
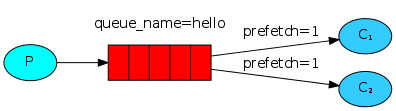
この動作を変更するには、 basic_qosメソッドとprefetch_count = 1オプションを使用します。 これにより、RabbitMQは一度に複数のメッセージをサブスクライバーに送信しなくなります。 つまり、サブスクライバーは、前のメッセージを処理して確認するまで新しいメッセージを受信しません。 RabbitMQは、最初の無料のサブスクライバーにメッセージを送信します。
channel.basic_qos(prefetch_count=1)
キューサイズに関する注意
すべてのサブスクライバがビジーの場合、キューサイズが増加する可能性があります。 これに注意を払い、おそらくサブスクライバの数を増やす必要があります。
さて、今ではすべて一緒に
new_task.pyの完全なコードは次のとおりです 。
#!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) message = ' '.join(sys.argv[1:]) or "Hello World!" channel.basic_publish(exchange='', routing_key='task_queue', body=message, properties=pika.BasicProperties( delivery_mode = 2, # make message persistent )) print " [x] Sent %r" % (message,) connection.close()
worker.pyの完全なコード:
#!/usr/bin/env python import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) print ' [*] Waiting for messages. To exit press CTRL+C' def callback(ch, method, properties, body): print " [x] Received %r" % (body,) time.sleep( body.count('.') ) print " [x] Done" ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(callback, queue='task_queue') channel.start_consuming()
メッセージ確認応答とprefetch_countを使用して、タスクキューを作成できます。 復元力を設定すると、RabbitMQサーバーを再起動した後でもタスクを持続させることができます。
3番目のレッスンでは、1つのメッセージを複数のサブスクライバーに送信する方法を見ていきます。