RabbitMQを使用すると、さまざまなプログラムがAMQPプロトコルを使用して通信できます。 RabbitMQは、SOA(サービス指向アーキテクチャ)を構築し、リソースを集中的に使用するタスクを分散するための優れたソリューションです。
カットの下で、公式サイトからの6つのレッスンの最初の翻訳。 例はpythonにありますが、それを知る必要はまったくありません。 同様のプログラムは、ほとんどすべての一般的なYPで再現できます。 [翻訳者のコメントは次のようになります。 私]
エントリー
RabbitMQはメッセージブローカーです。 その主な目的は、メッセージを受信および提供することです。 それは郵便局として想像することができます:あなたが箱に手紙を落とすとき、遅かれ早かれ郵便配達人が受取人にそれを配達することを確信することができます[明らかに、著者はロシアの郵便を扱ったことがない] 。 この類推では、RabbitMQはメールボックス、郵便局、郵便局の両方です。
RabbitMQと郵便局の最大の違いは、紙の封筒を処理しないことです-RabbitMQは、バイナリデータを受信、保存、および送信します-メッセージ。
RabbitMQでは、一般的なメッセージングと同様に、次の用語が使用されます。
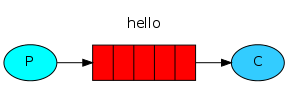
- プロデューサー (サプライヤー)-メッセージを送信するプログラム。 スキームでは、「P」の文字が付いた円で表されます。

- キュー -メールボックスの名前。 RabbitMQ内に存在します。 メッセージはRabbitMQおよびアプリケーションを通過しますが、キューにのみ保存されます。 キューはメッセージ数に制限がなく、任意の数のメッセージを受け入れることができます-無限バッファーと見なすことができます。 任意の数のサプライヤーが1つのキューでメッセージを送信でき、任意の数のサブスクライバーが1つのキューからメッセージを受信できます。 スキームでは、キューはスタックによって示され、名前で署名されます。

- コンシューマー (サブスクライバー)-メッセージを受け入れるプログラム。 通常、サブスクライバーはメッセージ待機状態です。 図では、「C」の文字が付いた円で表されます。

サプライヤ、サブスクライバ、ブローカは同じ物理マシン上にある必要はありません。通常は異なるマシン上にあります。
Hello World!
最初の例は特に難しくはありません。メッセージを送信し、受け入れて表示するだけです。 これを行うには、2つのプログラムが必要です。1つはメッセージを送信し、もう1つは受信して画面に表示します。
一般的なスキームは次のとおりです。
プロバイダーはhelloという名前でキューにメッセージを送信し、サブスクライバーはこのキューからメッセージを受信します。
RabbitMQライブラリ
RabbitMQはAMQPプロトコルを使用します。 RabbitMQを使用するには、このプロトコルをサポートするライブラリが必要です。 このようなライブラリは、ほぼすべてのプログラミング言語で使用できます。 Pythonも例外ではなく、Pythonにはいくつかのライブラリがあります。
例では、pikaライブラリが使用されます。 pipパッケージマネージャーを使用してインストールできます。
$ sudo pip install pika==0.9.5
pipまたはgit-coreが欠落している場合、最初にそれらをインストールする必要があります。
- Ubuntuの場合:
$ sudo apt-get install python-pip git-core
- Debianの場合:
$ sudo apt-get install python-setuptools git-core $ sudo easy_install pip
- Windowsの場合(easy_installをインストールするには、setuptools用のMS Windowsインストーラーを実行する必要があります):
> easy_install pip > pip install pika==0.9.5
メッセージを送信する
最初のsend.pyプログラムは、1つのメッセージをキューに送信するだけです。
#!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost')) channel = connection.channel()
ローカルホストにあるメッセージブローカーに接続しています。 別のマシンにあるブローカーに接続するには、「localhost」をこのマシンのIPアドレスに置き換えるだけで十分です。
メッセージを送信する前に、メッセージを受信するキューが存在することを確認する必要があります。 存在しないキューにメッセージを送信すると、RabbitMQはそれを無視します。 メッセージの送信先となるキューを作成して、「hello」と呼びます。
channel.queue_declare(queue='hello')
これで、メッセージを送信する準備ができました。 最初のメッセージには文字列
一般に、RabbitMQメッセージではキューに直接送信されず、 交換 ( 交換ポイント)を経由する必要があります。 しかし、今はこの交換のポイントに焦点を当てず、3番目のレッスンで説明します。 これで、空の文字列を指定することでデフォルトの交換ポイントを決定できることを知るだけで十分です。 これは特別な交換ポイントです。これにより、メッセージの送信先キューを決定できます。 routing_keyパラメーターでキュー名を指定する必要があります。
channel.basic_publish(exchange='', routing_key='hello', body='Hello World!') print " [x] Sent 'Hello World!'"
プログラムを終了する前に、バッファがクリアされ、メッセージがRabbitMQに到達したことを確認してください。 ブローカーとの接続を安全に閉じて使用する場合、これを確認できます。
connection.close()
メッセージを受信する
2番目のreceive.pyプログラムは、キューからメッセージを受信し、画面に表示します。
最初のプログラムと同様に、最初にRabbitMQに接続する必要があります。 これを行うには、以前と同じコードを使用します。 前と同様に、次のステップはキューが存在することを確認することです。 queue_declareコマンドは 、既に存在する場合、新しいキューを作成しません。したがって、このコマンドが何度呼び出されても、とにかく1つのキューのみが作成されます。
channel.queue_declare(queue='hello')
最初のプログラムですでに発表されているため、なぜ再びキューを発表するのか疑問に思うかもしれません。 これは、キューが存在することを確認するために必要であるため、 send.pyが最初に実行された場合になります。 しかし、どのプログラムが以前に起動されるかはわかりません。 このような場合、両方のプログラムでキューに入れる方が適切です。
キュー監視
現時点でRabbitMQに存在するキューを確認する場合は、 rabbitmqctlコマンドでこれを実行できます(スーパーユーザー権限が必要です)。
$ sudo rabbitmqctl list_queues Listing queues ... hello 0 ...done.
(Windowsの場合-sudoなし)
[当社では、より便利な監視スクリプトを使用しています。]
watch 'sudo /usr/sbin/rabbitmqctl list_queues name messages_unacknowledged messages_ready messages durable auto_delete consumers | grep -v "\.\.\." | sort | column -t;'
[スクリプトは、キューのリストを含むテーブルを2秒ごとに表示および更新します。キューの名前。 処理中のメッセージの数。 処理可能なメッセージの数。 メッセージの総数。 サービスを再起動するキューの安定性。 一時的なキューかどうか。 加入者数]
キューからのメッセージの受信は、送信よりも複雑なプロセスです。 取得は、コールバック関数を使用してサブスクリプションを通じて行われます。 各メッセージを受信すると、Pikaライブラリはこのコールバック関数を呼び出します。 この例では、メッセージテキストが表示されます。
def callback(ch, method, properties, body): print " [x] Received %r" % (body,)
次に、コールバック関数が「hello」という名前のキューからメッセージを受信することを示す必要があります。
channel.basic_consume(callback, queue='hello', no_ack=True)
ここで、サブスクライブするキューがアナウンスされていることを確認する必要があります。 以前にqueue_declareコマンドでこれを行いました 。
no_ackパラメータについては、 [ 2番目のレッスンで ]後で説明します。
最後に、キューからのメッセージを待機し、必要に応じてコールバック関数を呼び出すエンドレスプロセスを開始します。
print ' [*] Waiting for messages. To exit press CTRL+C' channel.start_consuming()
さて、今ではすべて一緒に
完全なsend.pyコード:
#!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.queue_declare(queue='hello') channel.basic_publish(exchange='', routing_key='hello', body='Hello World!') print " [x] Sent 'Hello World!'" connection.close()
完全なreceive.pyコード:
#!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.queue_declare(queue='hello') print ' [*] Waiting for messages. To exit press CTRL+C' def callback(ch, method, properties, body): print " [x] Received %r" % (body,) channel.basic_consume(callback, queue='hello', no_ack=True) channel.start_consuming()
これで、ターミナルでプログラムを実行できます。 まず、 send.pyプログラムを使用してメッセージを送信します。
$ python send.py [x] Sent 'Hello World!'
このプログラムは、各メッセージを送信した後に終了します。 次に、メッセージを受信する必要があります。
$ python receive.py [*] Waiting for messages. To exit press CTRL+C [x] Received 'Hello World!'
いいね! 最初のメッセージをRabbitMQ経由で送信しました。 お気づきかもしれませんが、 receive.pyプログラムの実行は終了しませんでした。 彼女は次のメッセージを待ちますが、 Ctrl + Cを押すと彼女を停止できます。
新しいターミナルウィンドウでsend.pyを再度実行してください。
名前付きキューを介してメッセージを送受信する方法を学びました。 次のレッスンでは、単純な[リソース集中型]タスクキューを作成します。
UPD: RabbitMQで動作するライブラリ。お気に入りのPLについては、 こちらの公式Webサイトで見つけることができます。