機械学習の分類タスクは、形式化された機能に基づいて事前定義されたクラスの1つにオブジェクトを割り当てるタスクです。 この問題の各オブジェクトは、N次元空間のベクトルとして表されます。各次元は、オブジェクトの特徴の1つの説明です。 モニターを分類する必要があると仮定します:パラメーター空間の測定値は、インチ単位の対角、アスペクト比、最大解像度、HDMIインターフェイス、コストなどになります。テキスト分類の場合は、やや複雑で、通常は用語ドキュメントマトリックスを使用します( 機械学習の説明.ru )。
分類器をトレーニングするには、クラスが事前定義されているオブジェクトのセットが必要です。 このセットはトレーニングセットと呼ばれ、そのマーキングは調査対象地域の専門家が関与して手動で行われます。 たとえば、コメントの事前に組み立てられたテストのためのソーシャルコメンタリーでIn辱を検出するタスクでは、このコメントがディスカッションの参加者の1人に対するin辱であるかどうかについて意見を述べます。タスク自体はバイナリ分類の例です。 分類問題では、3つ以上のクラス(マルチクラス)が存在する可能性があり、各オブジェクトは複数のクラスに属する(交差する)ことがあります。
アルゴリズム
テストサンプルの各オブジェクトを分類するには、次の操作を順番に実行する必要があります。
- トレーニングセット内の各オブジェクトまでの距離を計算します
- 距離が最小になるトレーニングサンプルのk個のオブジェクトを選択します
- 分類されたオブジェクトのクラスは、k個の最近傍から最も頻繁に見つかるクラスです
以下の例はpythonで実装されています。 正しく実行するには、pythonに加えて、 numpy 、 pylab 、およびmatplotlibがインストールされている必要があります。 ライブラリ初期化コードは次のとおりです。
import random import math import pylab as pl import numpy as np from matplotlib.colors import ListedColormap
ソースデータ
例による分類器の動作を検討してください。 まず、実験を行うデータを生成する必要があります。
#Train data generator def generateData (numberOfClassEl, numberOfClasses): data = [] for classNum in range(numberOfClasses): #Choose random center of 2-dimensional gaussian centerX, centerY = random.random()*5.0, random.random()*5.0 #Choose numberOfClassEl random nodes with RMS=0.5 for rowNum in range(numberOfClassEl): data.append([ [random.gauss(centerX,0.5), random.gauss(centerY,0.5)], classNum]) return data
簡単にするために、標準偏差0.5の2次元ガウスの数学的期待値の位置が各軸に沿って0から5のプロットでランダムに選択される2次元空間を選択しました。 値が0.5に設定されているため、オブジェクトはかなり分離可能です( 3シグマの規則 )。
結果の選択を確認するには、次のコードを実行する必要があります。
def showData (nClasses, nItemsInClass): trainData = generateData (nItemsInClass, nClasses) classColormap = ListedColormap(['#FF0000', '#00FF00', '#FFFFFF']) pl.scatter([trainData[i][0][0] for i in range(len(trainData))], [trainData[i][0][1] for i in range(len(trainData))], c=[trainData[i][1] for i in range(len(trainData))], cmap=classColormap) pl.show() showData (3, 40)
以下は、このコードを実行した結果の画像の例です。
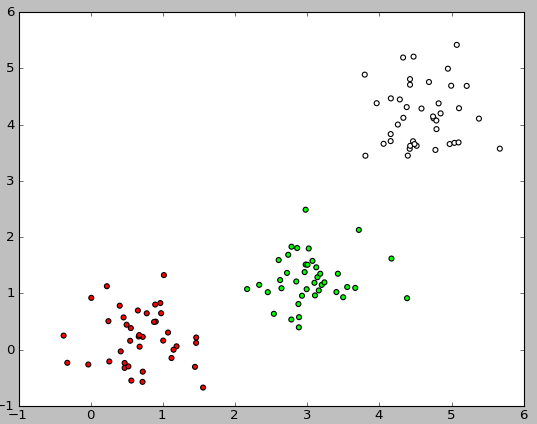
トレーニングおよびテストサンプルの取得
そのため、クラスが定義されているオブジェクトのセットがあります。 次に、このセットをトレーニング選択とテスト選択の2つの部分に分割する必要があります。 これを行うには、次のコードを使用します。
#Separate N data elements in two parts: # test data with N*testPercent elements # train_data with N*(1.0 - testPercent) elements def splitTrainTest (data, testPercent): trainData = [] testData = [] for row in data: if random.random() < testPercent: testData.append(row) else: trainData.append(row) return trainData, testData
分類子の実装
トレーニングサンプルができたら、分類アルゴリズム自体を実装できます。
#Main classification procedure def classifyKNN (trainData, testData, k, numberOfClasses): #Euclidean distance between 2-dimensional point def dist (a, b): return math.sqrt((a[0] - b[0])**2 + (a[1] - b[1])**2) testLabels = [] for testPoint in testData: #Claculate distances between test point and all of the train points testDist = [ [dist(testPoint, trainData[i][0]), trainData[i][1]] for i in range(len(trainData))] #How many points of each class among nearest K stat = [0 for i in range(numberOfClasses)] for d in sorted(testDist)[0:k]: stat[d[1]] += 1 #Assign a class with the most number of occurences among K nearest neighbours testLabels.append( sorted(zip(stat, range(numberOfClasses)), reverse=True)[0][1] ) return testLabels
オブジェクト間の距離を決定するには、ユークリッド距離だけでなく、マンハッタン距離、余弦測定、ピアソンの相関基準なども使用できます。
実行例
これで、分類器の動作を評価できます。 これを行うには、データを生成し、それをトレーニングサンプルとテストサンプルに分割し、テストサンプルのオブジェクトを分類し、クラスの実際の値を結果の分類と比較します。
#Calculate classification accuracy def calculateAccuracy (nClasses, nItemsInClass, k, testPercent): data = generateData (nItemsInClass, nClasses) trainData, testDataWithLabels = splitTrainTest (data, testPercent) testData = [testDataWithLabels[i][0] for i in range(len(testDataWithLabels))] testDataLabels = classifyKNN (trainData, testData, k, nClasses) print "Accuracy: ", sum([int(testDataLabels[i]==testDataWithLabels[i][1]) for i in range(len(testDataWithLabels))]) / float(len(testDataWithLabels))
分類器の品質を評価するために、さまざまなアルゴリズムとさまざまな尺度が使用されます。詳細はこちらをご覧ください: wiki
最も興味深いのは、分類器の操作をグラフィカルに表示することです。 以下の図では、それぞれ40個の要素を持つ3つのクラスを使用しました。アルゴリズムのkの値は3でした。
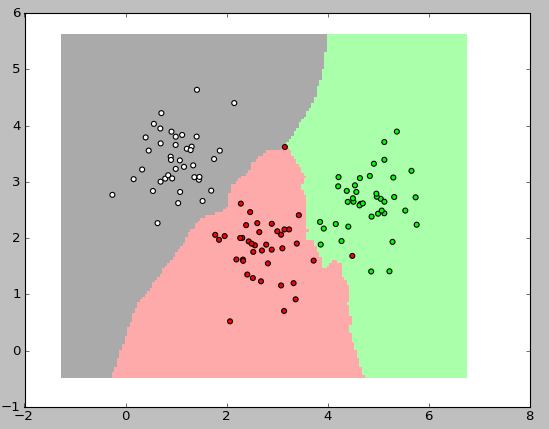
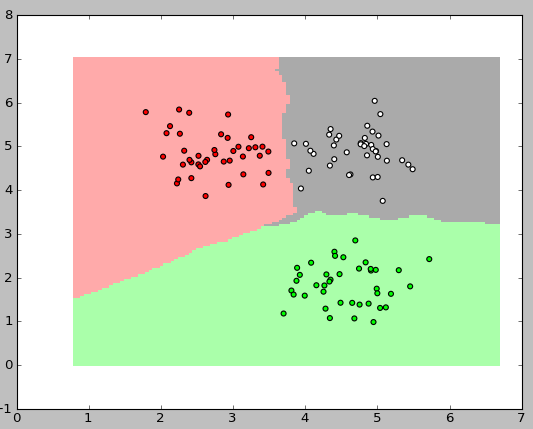
これらの画像を表示するには、次のコードを使用しました。
#Visualize classification regions def showDataOnMesh (nClasses, nItemsInClass, k): #Generate a mesh of nodes that covers all train cases def generateTestMesh (trainData): x_min = min( [trainData[i][0][0] for i in range(len(trainData))] ) - 1.0 x_max = max( [trainData[i][0][0] for i in range(len(trainData))] ) + 1.0 y_min = min( [trainData[i][0][1] for i in range(len(trainData))] ) - 1.0 y_max = max( [trainData[i][0][1] for i in range(len(trainData))] ) + 1.0 h = 0.05 testX, testY = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) return [testX, testY] trainData = generateData (nItemsInClass, nClasses) testMesh = generateTestMesh (trainData) testMeshLabels = classifyKNN (trainData, zip(testMesh[0].ravel(), testMesh[1].ravel()), k, nClasses) classColormap = ListedColormap(['#FF0000', '#00FF00', '#FFFFFF']) testColormap = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAAA']) pl.pcolormesh(testMesh[0], testMesh[1], np.asarray(testMeshLabels).reshape(testMesh[0].shape), cmap=testColormap) pl.scatter([trainData[i][0][0] for i in range(len(trainData))], [trainData[i][0][1] for i in range(len(trainData))], c=[trainData[i][1] for i in range(len(trainData))], cmap=classColormap) pl.show()
おわりに
kNNは最も単純な分類アルゴリズムの1つであるため、多くの場合、実際の問題では効果がありません。 分類の精度に加えて、この分類子の問題は分類の速度です:トレーニングセットにN個のオブジェクト、テストセットにM個のオブジェクト、および空間次元Kがある場合、テストサンプルを分類するための操作の数はO(K * M * N)と推定できます。 それでも、kNNアルゴリズムは機械学習を開始する良い例です。
参照資料
1. Machinelearning.ruの最近傍のメソッド
2. Machinelearning.ruのベクトルモデル
3. 情報検索に関する本
4. scikit-learnのフレームワークにおける最近傍の方法の説明
5. 「集合的な心のプログラミング」という本