
ソリューションの説明方法の選択
EvoJで問題を解決する従来の方法に従って、まず、問題の解決策をどのように記述するかを選択します。 簡単な解決策は、近似をポリゴンの単純なリストとして記述することです。
public interface PolyImage { List<Polygon> getCells(); }
このアプローチには生命権があり、遅かれ早かれ満足のいく写真を選択することができます。 このアプローチは、適切な意思決定を横断する効率を低下させるため、おそらく遅れるでしょう。 そして、ここに理由があります。
簡単にするために、次の図を想像してください。

遺伝子プールに2つの優れたソリューションがあり、それぞれが理想的なテストサイトごとに異なると仮定します。

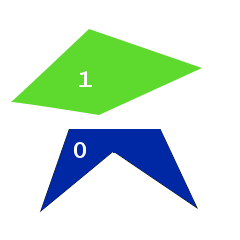
1つの機能に注意してください。どちらの場合も、ポリゴン番号0は理想的にはイメージポリゴンの1つと一致し、もう1つは側面のどこかにあります。 両方のソリューションの最初の2つのポリゴンが一緒に表示されるようにこれらの2つのソリューションを交差させることは素晴らしいことですが、これは不可能です-EvoJはすべての変数をバイト配列にマッピングし、交差するときにバイトの順序を変更せずに動作します。

クロスオーバープロセスを次の図で説明します。

したがって、同じインデックスを持つ2つの要素は結果のソリューションに表示されません。
交差の結果は次のようになります。

これは交配の効率に大きく影響し、進化を著しく遅くします。
元の母集団を「正しく」播種することで問題を回避できます-画像領域全体に多角形を均等に分散し、リスト内の多角形の位置が図の幾何学的位置と一致するようにします。 この場合、ポリゴンが過度に「クリープ」できないように、ミューテーションを制限する必要があります。
より高度なアプローチは、最初に画像をセルに分割し、各セルに独自のポリゴンリストを持たせることです。 Javaインターフェイスの形式では、これは次のように説明されます。
public interface PolyImage { Colour getBkColor(); List<List<List<Polygon>>> getCells(); }
外部リストはセルの行を定義し、次にネストするのは列です。最後に、内部リストには対応するセルにあるポリゴンが含まれます。 このようなアプローチは、バイト配列内のポリゴンの位置と、図内のその幾何学的位置のおよその対応を自動的に提供します。
各ポリゴンを次のように説明します。
public interface Polygon { List<Point> getPoints(); Colour getColor(); int getOrder(); }
ここで、orderプロパティは、グローバルポリゴンレンダリングの順序を決定します。 ポリゴンの色は次のように説明されます。
public interface Colour { @MutationRange("0.2") @Range(min = "0", max = "1", strict = "true") float getRed(); @MutationRange("0.2") @Range(min = "0", max = "1", strict = "true") float getGreen(); @MutationRange("0.2") @Range(min = "0", max = "1", strict = "true") float getBlue(); void setRed(float red); void setGreen(float green); void setBlue(float blue); }
つまり、3つのカラーコンポーネントと同様に、アルファチャネルを追加できますが、すべてのポリゴンを50%の透明度で描画します。これにより、無関心な突然変異の数が減ります。 ここでの注釈の目的は明らかです。 そうでない場合は、以前の記事をご覧ください。この問題は対処されています。
ポリゴンポイントは次のように説明されます。
public interface Point { int getX(); int getY(); }
この場合、XとYの座標は、ポリゴンが属するセルの中心を基準として考慮されます。 変数の許容値を規制する注釈は、色の説明にのみ存在することに注意してください。 これは、許容座標値が画像サイズとセルの構成に依存し、色成分の許容値があらかじめ決められているという事実によるものです。 さらに、
PolyImage
インターフェースの2つの内部リストの注釈は、
PolyImage
できません。
必要なすべてのパラメーターを設定するには、Detached Annotationsというメカニズムを使用します。
それでは、プログラミングに移りましょう。 この例で使用されているソースは、 ここにあります 。 上記のコードの多くは、以前の記事で書かれたものを繰り返しますが、多くは遺伝的アルゴリズムとは関係ありません。 したがって、重要な点に焦点を当て、残りの部分はコード内でコメントされています。
分離アノテーションを使用したEvoJの構成
final HashMap<String, String> context = new HashMap<String, String>(); context.put("cells@Length", ROWS.toString()); context.put("cells.item@Length", COLUMNS.toString()); context.put("cells.item.item@Length", POLYGONS_PER_CELL.toString()); context.put("cells.item.item.item.points@Length", "6"); context.put("cells.item.item.item.points.item.x@StrictRange", "true"); context.put("cells.item.item.item.points.item.x@Min", String.valueOf(-widthRadius)); context.put("cells.item.item.item.points.item.x@Max", String.valueOf(widthRadius)); context.put("cells.item.item.item.points.item.x@MutationRange", "20"); context.put("cells.item.item.item.points.item.y@StrictRange", "true"); context.put("cells.item.item.item.points.item.y@Min", String.valueOf(-heightRadius)); context.put("cells.item.item.item.points.item.y@Max", String.valueOf(heightRadius)); context.put("cells.item.item.item.points.item.y@MutationRange", "20"); context.put("cells.item.item.item.order@Min", "0"); context.put("cells.item.item.item.order@Max", "1000");
ここでは、
properties
ファイルと同様のコンテキスト
Map
を作成します。
properties
の名前は、
BeanUtils
で受け入れられる表記と同様の表記法でオブジェクトのプロパティへのパスに対応しますが、リスト項目はキーワード
item
示され
item
。
したがって、
cells
という名前は、ルート
PolyImage
インターフェイスの
cells
プロパティを
PolyImage
ます。 そして、行の
cells.item
はこのリストの要素であり、このリストは、行の
cells.item.item
などによって記述されるリストです。
プロパティの名前と
@
記号の後に、分離注釈の名前が続きます。これは、通常の注釈の名前に似ています。 リストの長さを指定して、EvoJがバイト配列で予約するスペースの量を知ることが必須です。
注釈
cells.item.item.item.points@Length
は、ポリゴン内のポイントの数を設定します(パスをトレースします
cells.item.item.item.points@Length
プロパティ、3つのネストされたリスト、ネストされたリスト自体の要素の
points
プロパティ。
点の座標の値の境界、それらの突然変異の半径、および順序プロパティの値の制限は、同様の方法で設定されます。
次に、遺伝子プールを作成するときに、塗りつぶされたコンテキストを使用します。
フィットネス機能の作成
適応度関数として、選択した画像の元の画像からの偏差の二乗和をマイナス記号で選択します-最小の量は最良の解に対応するためです。 フィットネス関数は
ImageRating
クラスに実装されています。キーポイントについて説明します。
前の記事の例のように、クラスは
AbstractSimpleRating
ヘルパークラスを継承します。
public class ImageRating extends AbstractSimpleRating<PolyImage>
次のように抽象doCalcRatingメソッドを実装します。
@Override protected Comparable doCalcRating(PolyImage solution) { BufferedImage tmp = drawImage(solution); return compareImages(originalImage, tmp); }
ここで、
drawImage
関数は、セル、順序、色などに従ってすべてのポリゴンを簡単に
drawImage
ます。 これについては詳しく説明しません-遺伝的アルゴリズムに関連するものは何も含まれていません。
compareImages
関数は、ピクセルごとの画像比較を実行します。 よく見てみましょう
private Comparable compareImages(BufferedImage originalImage, BufferedImage tmp) { long result = 0; int[] originalPixels = originalImage.getRaster().getPixels(0, 0, originalImage.getWidth(), originalImage.getHeight(), (int[]) null); int[] tmpPixels = tmp.getRaster().getPixels(0, 0, tmp.getWidth(), tmp.getHeight(), (int[]) null); for (int i = 0; i < originalPixels.length; i++) { long d = originalPixels[i] - tmpPixels[i]; result -= d * d; } return result; }
ご覧のとおり、この関数は非常に簡単です。元の画像と新たに描画された画像のラスターを取得し、要素ごとに比較し、同時に差の平方を(マイナス記号を付けて)加算します。
反復
結果をより速く達成するために、最適な変異パラメータを選択する必要があります。
- 決定が突然変異を受ける可能性
- 解内の各変数の突然変異の確率
- 変化の半径-突然変異中にポイントが移動できる最大距離
- ソリューションの寿命(完全に突然変異に関連するわけではありませんが、収束率にも影響します)
戦略の選択は簡単ではありません。 一方で、強力な突然変異により、ソリューションのスペースをすばやく受け入れてグローバルな極値を「模索」することができますが、一方で、それがスライドすることはできません-ソリューションは常にそれをすり抜けます。 ソリューションの長寿命は、フィットネス関数の価値の低下を防ぎますが、全体的な進行を遅くし、グローバルなものではなくローカルな極端な状態に陥りやすくします。 また、より高い確率で何を変更する必要があるかを決定する必要があります-ポリゴンまたはそれらの色のポイント。
さらに、しばらくすると、選択した戦略が使い果たされます。見つかった解は、見つかった極値に滑り込むのではなく、極値の周りで変動し始めます。 この問題に対処するには、戦略を変更する必要があります。 この場合の一般的な考え方は、突然変異のレベルが時間とともに低下し、成功した決定の寿命が長くなるということです。 この例で使用されている突然変異戦略は経験的に選択されています。
上記のすべてを考慮すると、メインプログラムループは次のように編成されます。
- 遺伝的アルゴリズムを10回繰り返します
- 最適なソリューションからフィットネス関数値を取得します
- 戦略を変更する時かどうかを判断する
- 必要に応じて戦略を変更する
- 画像を一時ファイルに保存する
- UIを更新
プログラムを起動すると、約15分で(マシンのパワーに応じて)選択したイメージがすでに元のイメージとあいまいに似ていることがわかります。1、2時間後には、記事の冒頭に示した内容に近い結果が得られます。
アルゴリズムのさらなる改善
次の最適化を適用することにより、進行を大幅に加速できます。
- 近似は、RGBではなくLab空間で実行されます;色空間内のポイント間のデカルト距離は、目で認識される差とほぼ一致するという事実によって特徴付けられます。 1秒あたりの反復回数は加算されませんが、進化は正しい方向に向けられます。
- 画像領域の重要性のマスクを作成します-注目領域を強調表示した白黒画像は、フィットネス関数の計算に使用されます。これにより、進化は本当に関心のあるものに焦点を当てることができます。
- 画像にはVolatileImageを使用します。 私のマシンでは、VolatileImageでの描画はBufferedImageでの描画より10倍高速です。 確かに、ピクセルの色を取得するには結果をBufferedImageに変換する必要があり、これによりパフォーマンスが大幅に低下しますが、最終結果はBufferedImageにポリゴンを描画するよりも3倍優れています。
- さまざまな段階で最適な突然変異パラメーターを選択します。 これは簡単な作業ではありませんが、ここでも遺伝的アルゴリズムが役立ちます。 突然変異パラメーターが変数であり、適合度関数が100回の反復あたりのエラー削減の平均率である実験を行いました。 結果は有望ですが、この問題を解決するにはかなりの計算能力が必要です。 おそらく次の記事のいずれかで、この問題を詳しく分析します。
- いくつかの独立した遺伝子プールを開始し、特定の間隔で、異なる遺伝子プールからの交配個体に独立して進化させます。 このアプローチは、GAアイランドモデルと呼ばれます。つまり、進化は互いに分離された島で行われたため、異なる島の個体間の交配は非常にまれです。
- 画像を徐々にポリゴンでまきます:最初に各セルに1-2個のポリゴンを配置し、「クリープ」させます。次に、画像が元のポリゴンから最も逸脱し、新しく追加されたポリゴンのみが進化する場所にさらに1-2個のポリゴンを追加します。セル内のポリゴン数の制限に達するまで、上記の記事で説明したように、画像全体の進化を開始します。 このアプローチにより、最も正確な近似が得られます。
あとがき
そこで、EvoJを使用して画像近似問題を解決する方法の例を見てみました。 他の特別にシャープ化された画像ベクトル化アルゴリズムでも同様の結果が得られるため、遺伝的アルゴリズムによる画像の近似は実用的なものよりも学術的または審美的な関心が高いことに注意してください。
次回は、遺伝的アルゴリズムを使用して設計アイデアを生成することについてお話します。
UPD1:記事の本文に記載されているソースへのリンクは目立たないため、ここで複製しますhttp://evoj.sourceforge.net/static/demos/img-demo.rar
UPD2:労働者の要求に応じて、最初の記事のスライドを引用します
| ソース画像 | 一致した画像 |
|---|---|
 |  |
 |  |