 P6000 EVAストレージシステムは、仮想化環境およびデータベースアプリケーションで動作するように設計および最適化されています。 HP EVAディスクアレイの技術的および運用上の利点は、3つの仮想化スキームのいずれか(ストレージシステムレベルでの仮想化)を実装するという事実によって主に保証されます。 サーバーレベルとネットワークレベルの2つの他のスキームと共に、論理的および物理的なストレージリソースの抽象化を提供します。 ストレージレベルの仮想化は、サーバーに依存しないディスクアレイコントローラーを使用して実装されます。 このタイプの仮想化により、ドライブを構成するすべての物理ディスクを、接続されているすべてのサーバーで使用可能なストレージリソースの単一プールとして考えることができます。 仮想化は、ストレージスペースの効率的な使用を提供し、管理プロセスを簡素化し、その結果、データストレージコストを削減します。
P6000 EVAストレージシステムは、仮想化環境およびデータベースアプリケーションで動作するように設計および最適化されています。 HP EVAディスクアレイの技術的および運用上の利点は、3つの仮想化スキームのいずれか(ストレージシステムレベルでの仮想化)を実装するという事実によって主に保証されます。 サーバーレベルとネットワークレベルの2つの他のスキームと共に、論理的および物理的なストレージリソースの抽象化を提供します。 ストレージレベルの仮想化は、サーバーに依存しないディスクアレイコントローラーを使用して実装されます。 このタイプの仮想化により、ドライブを構成するすべての物理ディスクを、接続されているすべてのサーバーで使用可能なストレージリソースの単一プールとして考えることができます。 仮想化は、ストレージスペースの効率的な使用を提供し、管理プロセスを簡素化し、その結果、データストレージコストを削減します。
この記事で説明するいくつかの簡単なヒントを使用すると、ストレージシステムの動作を正しく最適化でき、将来のビジネスの変化に迅速に適応できるようになります。
HP EVAアレイは、中小企業および企業クライアント向けに設計された低コストのディスクアレイにこれらの品質を実装する方法の例です。 HP EVAファミリーのドライブに実装されている仮想化の主な利点の1つは、その高いパフォーマンスと負荷分散です。これにより、物理ディスクへのアクセスを均等に分散できます。
図からわかるように、従来のRAIDの使用では、対応するRAIDアレイに含まれる物理ディスクに負荷全体が集中します。 この状況では、負荷はアプリケーションの動作モードに応じて多少なりますが、仮想化サポートではすべてのドライブが均等に負荷をかけるため、全体的なパフォーマンスが高くなります。

EVAシステムの内部構造の説明から始めましょう。 この説明は、EVAのすべての世代に実質的に変更されていない形式で適用されます。
以前の記事では、ディスクグループ、仮想ディスク(LUN)などのEVAストレージシステムの基本概念について書かれていました。
各ディスクグループは、冗長ストレージセット(RSS)上の仮想コントローラーソフトウェア(VCS / XCS)管理ソフトウェアによって共有され、このディスクグループの復元力を向上させます。 これは、1つの大きな共有ディスクグループを形成する多数のmini-RAIDグループと見なすことができます。
このディスクグループに情報を書き込む必要がある場合、各RSSに同じ量が書き込まれます(たとえば、3 RSSの30MBの情報がRSSの10MBに書き込まれます)。
分離プロセスの発生方法を明確に検討してください。
従来のストレージアレイの特徴は、特定のディスクを使用して同じRAIDレベルのデータを保存することです。

仮想化EVAシステムの場合、すべてのドライブを使用して、異なるRAIDレベルでデータを保存できます。
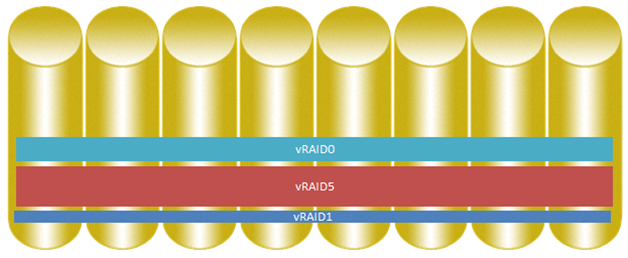
したがって、EVAの各ボリュームは、仮想ディスクを構成するすべてのディスクからIOPSを受け取り、パフォーマンスが向上します。
1. XCS管理ソフトウェアは、各ディスクを同じサイズのブロックに分割します。 ブロックサイズは、アレイのバージョン、制御ソフトウェアのバージョンに依存し、セグメントのサイズは2/8 MB異なります。
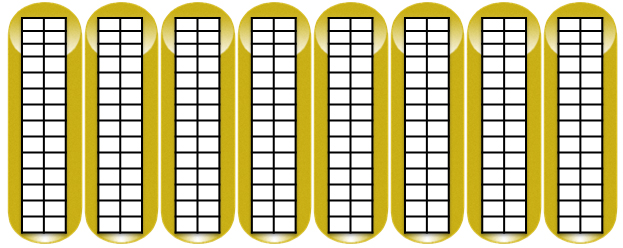
2.次に、8つのディスク(RSS)のグループに形成されます。各RSSは、優先RAIDレベルに応じて、ディスク障害からデータを保護するために必要な量を予約します。
3. EVAは、RSS参加者を選択するための特定のアルゴリズムに従って、最大限の可用性とより良いディスクスペース使用率を確保します。
-RSSメンバーは、異なるディスクシェルフ間で垂直に選択されます
-異なるディスクシェルフ間でRAIDペアが選択されている
明確にするために、異なる棚からのディスクは一列に配置されます。 EVA 4400を例として使用して、RAID5に2つの8 MBデータブロック(4データブロックと1パリティブロック)を書き込む例を模式的に示します。
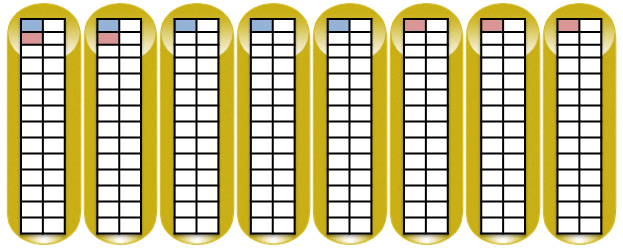
ディスクの追加時またはディスクの障害の場合、トリガーの移動とRSSの再構築のプロセスは、発生した変更により情報が失われる可能性がある場合にのみ開始されます(vRAID1ペアの参加者を含むディスクの障害の場合、再構築のプロセスは、 vRAID5参加者の場合、調整の優先度は低くなります)。 RSS再構築プロセスの優先度は、アレイ内の残りのプロセスの優先度の評価に基づいて選択されます。 このプロセスはバックグラウンドで実行され、パフォーマンスには影響しません。
ストレージシステムの運用中、サービスを中断することなく追加のディスクをインストールする必要がある場合があります。仮想化では、これは非常に簡単です。
仮想化によってサポートされる分散バックアップにより、物理ディスクの1つに障害が発生した後のデータ復旧は、ホットバックアップモードで一定数の自立ディスクを保持する必要がある従来のスキームよりもはるかに高速です。 加速は、バックアップディスクが共通のプールに均等に含まれているという事実により実現されます。 実際のところ、特別なバックアップディスクはありませんが、一定の容量が確保されています。 1つのドライブに障害が発生した場合、通常の管理ツールはドライブ間のバランスを変更し、VRaid構造を復元します。 これは非常に迅速な手順であり、その結果は予備の減少のみであり、サービスを中断することなく復元できます。
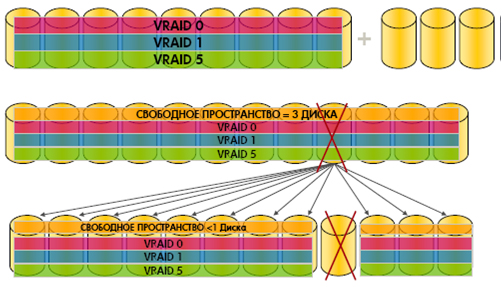
ディスクとコントローラーの負荷を最適化するアレイには、均一に分散するプロセスがあります。
1.ディスクグループでRSSを均一に配布するプロセス
2.各RSS内でデータを均等に配布するプロセス。
ディスク再構築プロセスは、均一分散プロセスよりも高い優先度を持っています。 データのフォールトトレランスが保持されます。
ドライブに障害が発生した場合の最良の推奨事項は次のとおりです。
1.ディスクグループ構成を変更する前に、故障したディスクを交換します
2.故障したディスクを、ボリュームと速度が似たものと交換します。
3.新しいディスクは、故障したディスクと同じ場所に配置する必要があります。
たとえば、アレイごとに50台のディスクがある構成では、最大6台のディスクが同時に故障する可能性があるため、VRAID5のデータはアクセス可能なまま、または25台のディスクがVRAID1で同時に故障する可能性があります。
各LUNのデータは異なるRSSで配布されているため、異なるRSSは異なるディスクシェルフのディスクで構成されているため、アレイ全体の高いパフォーマンスが保証されます。 各ドライブはIOPSを追加します。これは、ホストアプリケーションのLUNによって発行できます。
ベストプラクティスドキュメントに基づいて、ディスクアレイのパフォーマンスを向上させるいくつかの重要な推奨事項があります。
1.アレイが接続されているコントローラー、ディスク、デバイスの最新のファームウェアバージョンを使用します。
2.棚の数を8の倍数で使用します-これにより、RSS内のディスクの分散が最適化されます。
3. 8の倍数でディスクグループにディスクを追加します。
4.ディスクグループで同じボリュームと速度のディスクを使用します。 さまざまなサイズと速度のディスクを使用すると、アレイをサポートするコストが増加します。 たとえば、小さなディスクで構成されるディスクグループに大きなディスクを配置すると、このディスクの使用可能なボリュームは、グループ内の最小のディスクのサイズと等しくなります。
5.できるだけ少ないディスクグループを作成します-これにより、データが最大数のディスクを使用できるようになり、その結果、最高のパフォーマンスパラメーターが発行されます。
6.アレイができるだけ多くのドライブにデータを分散すると、パフォーマンスが最大化されます。
7.ほとんどのインストールでは、1つの保護レベルで十分なデータ可用性が提供されます。
8.データベースログを使用してデータを他のデータから分離します。
9.最大パフォーマンスのパラメーターには、ソリッドステートドライブを使用します。
10. EVAコントローラーが負荷を分散できるようにします。
11.データセンターのすべてのベストプラクティスは、外部バックアップデバイスまたは大容量MDL SASディスク上の個別のディスクグループへのデータの定期的なコピーに基づいています。
12. Inside Remote Supportを使用して、アレイの問題をHPサポートセンターに自動的に報告します。
別の項目は、LUNを移動し、仮想ディスクのvRAIDレベルを変更するプロセスを説明できます。 これらの操作では、ミラー化されたコピーを使用して、新しいパラメーターでグループにデータをコピーします。 ミラーコピーが同期されるとすぐに、コピーとメインボリュームの役割が変更されます。 ホストデータは自動的に新しいボリュームにアクセスします。 この機能は、HP Business Copyライセンスを購入すると利用可能になります。 コピー後、両方のボリュームが残り、古いパラメーターを持つボリュームがコピーになります。自由に削除できます。
材料:
1. HP P6000ベストプラクティス
2. VMware with HPのベストプラクティス
3. HP P6000 QuickSpecs
PSこのトピックでは、P6000アレイの配置に関する一部の資料のみが公開されています。