はじめに
オブジェクトを管理するデータ構造があり、それと2つ以上のスレッドのオブジェクトを操作したいとします。 最大のパフォーマンスを実現するには、データ構造自体を保護するために使用されるメカニズムと、現在のオブジェクトを保護するために使用されるメカニズムを区別する必要があります。
なぜ参照カウントが必要なのですか?
これら2つのメカニズムが最高のパフォーマンスを提供する理由と、アトミック変数の有用性を説明するには、次の状況を考慮してください。
最初のスレッド(マニピュレーター)は、データ構造内で特定のオブジェクトを見つけて変更する必要があります。 2番目のスレッド(消しゴム)は、廃止されたオブジェクトを削除します。 時々、最初のスレッドは、2番目のスレッドが削除しようとしているオブジェクトを操作しようとします。 これは、ほとんどすべてのマルチスレッドプログラムで見られる古典的なシナリオです。
明らかに、2つのスレッドは、ある種の相互排他メカニズム(相互排他-約Per。)で動作する必要があります。 単一のミューテックスでデータ構造全体を保護するとします。 この場合、マニピュレータスレッドは、オブジェクトを見つけて処理するまで、ミューテックスをブロックし続ける必要があります。 これは、マニピュレータストリームが作業を完了するまで、消しゴムストリームがデータ構造にアクセスできないことを意味します。 マニピュレータストリームが行うことは、レコードの検索と処理だけである場合、消しゴムストリームはデータ構造にアクセスできません。
状況によっては、これはシステムの目に見えない破壊になる可能性があります。 そしてすでに述べたように、この問題を解決する唯一の方法は、データ構造を保護するメカニズムと実際のオブジェクトを保護するメカニズムを分離することです。
これを行うと、マニピュレータスレッドはオブジェクトを検索するときにのみミューテックスをブロックします。 オブジェクトを受け取ると、mutexを解放できるようになります。これにより、データ構造が保護され、消しゴムストリームがそのジョブを実行できるようになります。
しかし、今、消しゴムスレッドが最初のスレッドが変更しているのと同じオブジェクトを削除しないことをどのようにして確認できますか?
実際のオブジェクトの内容を保護する別のミューテックスを使用できます。 しかし、これは重要な疑問を提起します。 オブジェクトの内容を保護するために必要なミューテックスの数は?
すべてのオブジェクトに1つのミューテックスを使用すると、回避したのと同じ輻輳に直面します。 一方、各オブジェクトにミューテックスを使用すると、わずかに異なる問題に直面します。
各オブジェクトにミューテックスを作成するとします。 オブジェクトのミューテックスをどのように管理する必要がありますか? オブジェクト自体にミューテックスを配置できますが、これにより次の追加の問題が発生します。 消しゴムストリームがオブジェクトを削除することを決定したが、少し前に、マニピュレータストリームがオブジェクトをチェックすることを決定し、そのミューテックスをブロックしようとします。 ミューテックスはすでに消しゴムのストリームを取得しているため、マニピュレータは休止状態になります。 しかし、この出発直後に、消しゴムはオブジェクトとそのミューテックスを削除し、マニピュレーターを存在しないオブジェクトでスリープさせます。 痛い。
実際、できることはいくつかあります。 それらの1つは、オブジェクトへの参照のカウントの使用です。 ただし、リンクカウント自体を保護する必要があります 。 幸いなことに、アトミック変数のおかげで、ミューテックスを使用してカウンターを保護する必要はありません。
アトミック変数を使用してオブジェクトへの参照をカウントする方法について
最初に、オブジェクト参照カウントを1に初期化します。 マニピュレータスレッドが使用を開始すると、参照カウンタを1つ増やす必要があります。 オブジェクトの操作が終了すると、参照カウントが減ります。 つまり、マニピュレータがオブジェクトを使用している限り、参照カウントをインクリメントし続ける必要があります。
消しゴムストリームがオブジェクトの削除を決定するとすぐに、まずオブジェクトをデータ構造から削除する必要があります。 これを行うには、データ構造を保護するミューテックスを保持する必要があります。 その後、オブジェクトの参照カウンターを1つ減らす必要があります。
ここで、参照カウントを1に初期化したことを思い出してください。 したがって、オブジェクトが使用されない場合、その参照カウントはゼロになります。 nullの場合、オブジェクトを安全に削除できます。 これは、オブジェクトがデータ構造内にないため、最初のスレッドがそれを使用しないことを確認できるためです。
そして、彼のリンク数が複数の場合はどうなりますか? この場合、スレッド参照カウントがゼロになるまで待つ必要があります。 しかし、それを行う方法は?
この質問に答えることは非常に困難です。 通常、2つのアプローチのいずれかを検討します。 単純なアプローチまたはRCUアプローチと呼ばれるアプローチ(読み取りコピーの更新-約Per。)。
素朴なアプローチ
素朴なアプローチは次のとおりです。 削除するオブジェクトのリストを作成します。 消しゴムストリームがアクティブになるたびに、リストを調べて、参照カウントがゼロのすべてのオブジェクトを削除します。
状況によっては、このソリューションに問題がある場合があります。 削除されたオブジェクトのリストは大きくなる可能性があり、その中を完全に通過するとプロセッサが過負荷になる可能性があります。 オブジェクトを削除する頻度によっては、これで十分な解決策になる場合がありますが、そうでない場合は、RCUアプローチを検討する必要があります。
RCUアプローチ
RCUは別のタイミングメカニズムです。 主にLinuxカーネルで使用されます。 あなたはここでそれについて読むことができます 。 これをRCUアプローチと呼びます。これは、RCU同期メカニズムの動作といくつかの類似点があるためです。
このアイデアは、マニピュレータスレッドがオブジェクトを操作するのに時間がかかるという前提に基づいています。 つまり、基本的に、マニピュレーターは一定時間オブジェクトを使用し続けます。 この期間が経過すると、オブジェクトは使用されなくなり、消しゴムストリームで削除できるようになります。
マニピュレータスレッドがその操作を完了するのに基本的に1分かかると仮定します。 ここで特に誇張します。 消しゴムストリームがオブジェクトを削除しようとするとき、オブジェクトを含むデータ構造を保護するミューテックスまたはスピンロックを取得し、このデータ構造からオブジェクトを削除するだけです。
次に、現在の時刻を取得してオブジェクトに保存する必要があります。 オブジェクトには、自身が削除された時間を思い出せるメソッドが必要です。 その後、消しゴムストリームは、削除されたオブジェクトのリストの最後に追加します。 これは、削除したいすべてのオブジェクトを含む特別なリストです-素朴なアプローチのように。
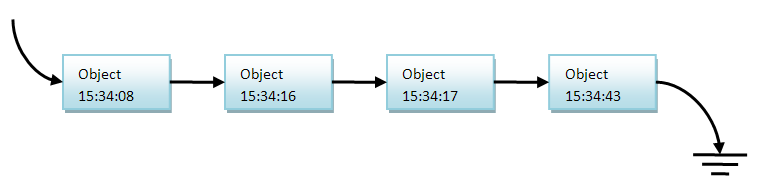
リストの最後にオブジェクトを追加すると、オブジェクトが削除された時間順にソートされることに注意してください。 削除された時刻が早いリスト内の以前のオブジェクト。
次に、消しゴムストリームはリストの先頭に戻り、オブジェクトをキャプチャして、データ構造から削除されてから1分が経過したことを確認する必要があります。 その場合、参照カウントをチェックし、それが本当にゼロであることを確認する必要があります。 そうでない場合は、削除時間を現在の時間に更新し、リストの最後に追加する必要があります。 通常これは起こらないことに注意してください。 消しゴムストリームの参照カウンタがゼロの場合、リストからオブジェクトを削除して削除する必要があります。
これがどのように機能するかを示すには、上の図を見てください。 今15:35:12としましょう。 これは、最初のオブジェクトを削除してから1分以上かかります。 したがって、消しゴムがアクティブになり、リストを確認するとすぐに、リストの最初のオブジェクトが1分以上前に削除されたことがすぐにわかります。 リストからオブジェクトを削除し、次のオブジェクトを確認します。
彼は次のオブジェクトをチェックし、1分以内にリストにあることを確認して、リストに残します。 今-このアプローチの興味深い機能。 消しゴムストリームは、リストの残りをチェックしないでください。 常にオブジェクトをリストの最後に追加するため、リストはソートされ、消しゴムストリームは他のオブジェクトも削除されないことを確認できます。
したがって、単純なアプローチで行ったようにリスト全体を調べる代わりに、タイムスタンプ(タイムスタンプ-約Per。)を使用して、オブジェクトのソートされたリストを作成し、リストの先頭にある少数のオブジェクトのみをチェックできます。 状況によっては、これにより時間を大幅に節約できます。
アトミック変数はいつ現れましたか?
バージョン4.1.2以降、gccにはアトミック変数のサポートが組み込まれています。 ほとんどのアーキテクチャで動作しますが、使用する前に、アーキテクチャがそれらをサポートしていることを確認してください。
アトミック変数で動作する一連の関数があります。
type __sync_fetch_and_add (type *ptr, type value); type __sync_fetch_and_sub (type *ptr, type value); type __sync_fetch_and_or (type *ptr, type value); type __sync_fetch_and_and (type *ptr, type value); type __sync_fetch_and_xor (type *ptr, type value); type __sync_fetch_and_nand (type *ptr, type value);
type __sync_add_and_fetch (type *ptr, type value); type __sync_sub_and_fetch (type *ptr, type value); type __sync_or_and_fetch (type *ptr, type value); type __sync_and_and_fetch (type *ptr, type value); type __sync_xor_and_fetch (type *ptr, type value); type __sync_nand_and_fetch (type *ptr, type value);
これらの関数を使用するためにヘッダーファイルを含める必要はありません。 アーキテクチャがそれらをサポートしていない場合、リンカは存在しない関数の呼び出しが発生したかのようにエラーをスローします。
これらの各機能は、特定のタイプの変数で動作します。 タイプは、 char 、 short 、 int 、 long 、 long long 、またはそれらに相当する符号なしのいずれかです。
これらの機能を、実装の詳細を隠すものでラップすることをお勧めします。 アトミック変数または抽象データ型を表すクラスにすることができます。
最後に、この記事でのアトミック変数の使用に関する簡単な例があります。これは、 単純なマルチスレッドタイプのデータアクセスとアトミック変数です 。
おわりに
この記事が興味深いものになることを願っています。 追加の質問については、電子メールに書いてください(元の-およその割合で示されます)。
翻訳者のメモ
著者のこの記事およびその他の記事は、トピックに関する資料を網羅しているとは主張していませんが、入門的なプレゼンテーションスタイルが優れています。
現時点ではアトミック変数に注意してください:
- 標準C11(p。7.17)およびC ++ 11(p。29 )で説明されています-ほとんどの場合、それらの実装は利用可能です(ただし、C11にはまだ問題があります)。
- Boost.AtomicとしてBoostに対して記述および実装されています (ただし、この実装はboost 1.50に含まれていませんでした)。
- Intel Threading Building Blocksに実装されています。
RCUのドキュメントへの著者のリンクに加えて、ユーザースペース用のRCUを実装するユーザースペースRCUプロジェクトに注目する価値があります。