参加する代わりに
怠azineは進歩のエンジンです。 自分で穀物を粉砕したくない-製粉所を作り、敵に自分で石を投げたくない-カタパルトを構築し、異端審問のき火で燃え尽き、封建領主の下で背中を曲げる-しかし、私は何を話しているのか。
オートメーション、紳士。 人が参加し、人を複雑なメカニズムに置き換え、利益を得るという有益なプロセスを取ります。 比較的最近、人をコードに置き換えることも流行になりました。 ああ、何人の高貴な職業が情報化の猛攻撃に陥ることができるか。 特に、私たちの時代のコードの一部には、あらかじめ決められた動作だけでなく、ある種の動作を「学習」する能力があると考えている場合もあります。
少し要約する
一般的に、私たちのコードを表すアルゴリズムのこのような超大国は、単なる学習ではなく、機械学習と呼ばれています。 通常、我々は知性に恵まれたものだけが学ぶことができることを意味します。 そして、当然のことながら、機械学習の分野は、人工知能(AI)のはるかに一般的な分野の一部です。

図が示すように、多くのAIタスクは機械学習アルゴリズムに基づいています。 何か楽しいものを選択するだけで、決定するのはそれほど楽しいものではありません。
そして空想する
たとえば、%username%というユーザーが、 IMDb Webサイトを所有する会社の機械学習の専門家に雇われたとします。 そして、彼らは彼らが言う、私たちはロシアのイヴァネスに彼らのキノポイスク検索をして欲しいと言います、レビューが肯定的か否定的かに応じて緑か赤でマークされたユーザーレビュー。 そして、ここであなたはレビューでわいせつなサイズのデータベースを取得し、よく訓練し、そのセットのすべてを2つの互いに素なサブセット(クラス)に分割し、エラーの確率が最小になるようにアルゴリズムを発行する必要があることを理解しているようです。
人のように、私たちのアルゴリズムは、その間違い(教師なしで学習、教師なし学習)から、または他の例(教師で学習、教師あり学習)から学習できます。 しかし、この場合、彼自身はポジティブとネガティブを区別できません。 彼はパーティーに呼ばれることはなく、他の人とはほとんど接触しませんでした。 したがって、既成の例(前例)のトレーニングを実行するには、クラス(トレーニングセット)で既にマークされているレビューのサンプルを取得する必要があります。
全体として、自然言語処理のタスクに関連する感情分析の問題を、新しいレビューごとに肯定的か否定的かを示す特定の分類子をトレーニングすることで解決したいと考えています。 次に、分類子を選択し、すべてをコーディングする必要があります。
神様、素朴な
一般的に、野生では膨大な数の異なる分類子があります。 ここで思いつく最も簡単なことは、すべての記事を、たとえば肯定的な記事に帰することです。 結果:学習する必要はありません。分類子の精度は50%、関心は0%です。
しかし、あなたがそれについて考えたら...別のオブジェクトを割り当てるクラスをどのように選択しますか? このクラスに属するオブジェクトの確率が最大(キャプテン!)になるように選択します。

、ここでCはある種のクラスであり、dはオブジェクトです。この場合はレビューです。 したがって、レビューがポジティブまたはネガティブクラスに属する事後尤度を最大化しようとしています。
条件付き確率を見ると、すぐにベイズの定理を適用するように頼みますが、まだ最大値を探しているので、不必要な分母を捨てて結果を得るように頼みます:

これはすべてクールです、とあなたは言いますが、実際の生活の中でこれらの奇跡的な確率をどこで得るのでしょうか? さて、Pではすべてが簡単です。クラスの分布を適切に表示するトレーニングサンプルがある場合は、以下を評価できます。

ここで、nはクラスCに属するオブジェクトの数、Nはサンプルのサイズです。
P(d | C)を使用すると、すべてが少し複雑になります。 ここでは、ドキュメント内の個々の単語が互いに独立しているという「単純な」仮定を作成する必要があります。

また、n個の1次元密度の復元は、1つのn次元よりもはるかに簡単なタスクであることを理解してください。
この場合、トレーニングサンプルに従って、以下を評価できます。

ここで、mはクラスCの単語wの数、MはクラスCの単語(またはトークン)の数です。したがって、次のようになります。

しかし、このような分類器は単純ベイズ分類器と呼ばれます。
独立の素朴な仮定の妥当性についてのいくつかの言葉。 このような仮定はめったに真実ではありません。この場合、たとえば、明らかに間違っています。 しかし、実践が示すように、単純ベイズ分類器は、厳密に言えば独立性の仮定が満たされない問題を含む多くの問題で驚くほど良い結果を示します。
単純ベイズ分類器の利点は、トレーニングサンプルのサイズに対する非感度、高い学習速度、およびいわゆる再トレーニングへの抵抗です(オーバーフィッティングは、アルゴリズムがトレーニングサンプルで非常にうまく機能し、テストサンプルでは不十分である現象です)。 したがって、それらは、初期データが非常に小さい場合、またはそのようなデータが大量にあり、学習の速度が最初に来る場合に使用されます。 欠点:独立性の仮定に違反する場合は特に、最高の精度ではありません。
開発者、開発者、開発者
そして今、すでにコードを見て必死です 。 トレーニングサンプルは、コーネル大学が準備したIMDbレビューのコレクションでした(スタッフ自身がこのデータを使用して楽しい研究を実施しました)。
最も興味深いadd_exampleおよびclassifyメソッド。 最初は、それぞれトレーニングに従事し、必要な確率密度を復元し、2番目は結果のモデルを適用します。
def add_example(self, klass, words): """ * Builds a model on an example document with label klass ('pos' or 'neg') and * words, a list of words in document. """ self.docs_counter_for_klass[klass] += 1 for word in words: self.token_counter_for_klass[klass] += 1 self.word_in_klass_counter_for[klass][word] += 1
トレーニングは非常に簡単です-レビューとそのタグ付きクラスから単語を取得します。 クラスnのドキュメント数、クラスMの単語数、クラス-mの単語数wを考慮します。 すべてさらに分類。
def classify(self, words): """ 'words' is a list of words to classify. Return 'pos' or 'neg' classification. """ score_for_klass = collections.defaultdict(lambda: 0) num_of_docs = sum(self.docs_counter_for_klass.values()) for klass in self.klasses: klass_prior = float(self.docs_counter_for_klass[klass]) / num_of_docs score_for_klass[klass] += math.log(klass_prior) klass_vocabulary_size = len(self.word_in_klass_counter_for[klass].keys()) for word in words: score_for_klass[klass] += math.log(self.word_in_klass_counter_for[klass][word] + 1) score_for_klass[klass] -= math.log(self.token_counter_for_klass[klass] + klass_vocabulary_size) sentiment = max(self.klasses, key=lambda klass: score_for_klass[klass]) return sentiment
なぜなら 確率は非常に小さい場合がありますが、私たちはまだ最大化に取り組んでいるので、良心のtwinなしにプロローグリズムを行うことができます。
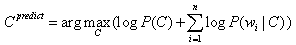
-これは何が起こっているのかを説明しています。 クラスの結果は、それぞれ最大スコアを獲得したものになります。
def cross_validation_splits(self, train_dir): """Returns a lsit of TrainSplits corresponding to the cross validation splits.""" print '[INFO]\tPerforming %d-fold cross-validation on data set:\t%s' % (self.num_folds, train_dir) splits = [] for fold in range(0, self.num_folds): split = TrainSplit() for klass in self.klasses: train_file_names = os.listdir('%s/%s/' % (train_dir, klass)) for file_name in train_file_names: example = Example() example.words = self.read_file('%s/%s/%s' % (train_dir, klass, file_name)) example.klass = klass if file_name[2] == str(fold): split.test.append(example) else: split.train.append(example) splits.append(split) return splits
利用可能なデータを完全に利用するために、k-fold cross-validationが適用されました:利用可能なデータはk個の部分に分割され、モデルはデータのk-1個の部分でトレーニングされ、残りのデータはテストに使用されます。 手順はk回繰り返され、最終的に、k個のデータのそれぞれがテストに使用されます。 結果の分類効率は、単に平均として計算されます。
まあ、完全に禅を達成するために、私は教師と一緒に学習プロセスを描いた写真を添付しています(一般的な場合):

このすべての原因は何ですか?
$ python NaiveBayes.py ../data/imdb1
[情報]データセットで10倍の交差検証を実行:../data/imdb1
[情報]フォールド0精度:0.765000
[情報]フォールド1精度:0.825000
[情報]フォールド2精度:0.810000
[情報]フォールド3精度:0.800000
[情報]フォールド4精度:0.815000
[情報] 5つ折りの精度:0.810000
[情報]フォールド6精度:0.825000
[情報]フォールド7精度:0.825000
[情報]フォールド8精度:0.765000
[情報]フォールド9精度:0.820000
[情報]精度:0.806000
フィルタリングの停止:
$ python NaiveBayes.py -f ../data/imdb1
[情報]データセットで10倍の交差検証を実行:../data/imdb1
[情報]フォールド0精度:0.770000
[情報]フォールド1精度:0.815000
[情報]フォールド2精度:0.810000
[情報]フォールド3精度:0.825000
[情報]フォールド4精度:0.810000
[情報] 5つ折りの精度:0.800000
[情報]フォールド6精度:0.815000
[情報]フォールド7精度:0.830000
[情報]フォールド8精度:0.760000
[情報]フォールド9精度:0.815000
[情報]精度:0.805000
ストップワードのフィルタリングが結果にそれほど影響を与えた理由(つまり、ほとんど影響を与えなかった理由)については、読者に熟考してもらいます。
例
希少な数から離れると、実際に何が得られましたか?
シードの場合:
"Yes, it IS awful! The books are good, but this movie is a travesty of epic proportions! 4 people in front of me stood up and walked out of the movie. It was that bad. Yes, 50 minutes of wedding...very schlocky accompanied by sappy music. I actually timed the movie with a stop watch I was so bored. There is about 20 minutes of action and the rest is Bella pregnant and dying. The end. No, seriously. One of the worst movies I have ever see"
このようなレビューは明らかに否定的なものとして認識されており、驚くことではありません。 エラーを見るともっと面白いです。
" `Strange Days' chronicles the last two days of 1999 in los angeles. as the locals gear up for the new millenium, lenny nero (ralph fiennes) goes about his business of peddling erotic memory clips. He pines for his ex-girlfriend, faith (juliette lewis ), not noticing that another friend, mace (angela bassett) really cares for him. This film features good performances, impressive film-making technique and breath-taking crowd scenes. Director kathryn bigelow knows her stuff and does not hesitate to use it. But as a whole, this is an unsatisfying movie. The problem is that the writers, james cameron and jay cocks ,were too ambitious, aiming for a film with social relevance, thrills, and drama. Not that ambitious film-making should be discouraged; just that when it fails to achieve its goals, it fails badly and obviously. The film just ends up preachy, unexciting and uninvolving."
このレビューには肯定的なラベルが付けられていますが、否定的なものとして識別されています。 私の意見でさえ、このレビューがポジティブであるかネガティブであるかを判断することは難しいため、最初のマーキングの正確さについて質問することができます。 少なくとも、分類器がそれをネガティブとして分類した理由は驚くべきことではありません。不満、失敗、ひどく、興奮せず、関与しないことは、残りを上回る非常に強いネガティブな指標です。
そして、もちろん、分類器は皮肉を理解せず、この場合、否定を肯定として容易に受け入れます。
"This is what you call a GREAT movie? AWESOME acting you say?Oh yeah! Robert is just so great actor that my eyes bleeding when I'm see him. And the script is so good that my head is exploding. And the ending..ohhh, you gonna love it! Everything is so perfect and nice - I dont got words to describe it!"
おわりに
単純なベイジアンを含む分類子は、意見の分析に加えて、スパムフィルタリング、音声認識、クレジットスコアリング、生体認証など、多くの分野で使用されます。
単純ベイズに加えて、パーセプトロン、決定木、サポートベクトル法(SVM)に基づく分類器、核分類器(カーネル分類器)など、他の多くの分類器があります。 しかし、教師と一緒に教えることとは別に、教師なしのトレーニング、強化を伴うトレーニング(強化学習)、ランク付けの学習(ランク付けの学習)などもありますが、これはまったく別の話です
この記事は、Technopark @ Mail.Ruプロジェクトの学生を対象としたコンテストのフレームワークで書かれました。