ハフマンコーディングの考え方は、文字列内の文字の使用頻度を使用することに基づいています。 最も頻繁に出会う文字には、可能な限り短いコード値を与え、最も頻繁に出会わない文字はできるだけ長く与える必要があります。 アーカイブ中に最も頻繁に発生する文字は以前よりも少ないスペースを使用する必要があり、最も頻繁に使用されない文字はより多くのスペースを使用できるという事実により、文字数が少ないため、これは結果に大きな影響を与えません。
この例では、文字を8ビットにすることにしました。 タイプchar。 同じ成功により、16、10、または20ビットの長さを選択することができました。 予想される入力データに応じて、シンボルの長さを選択する必要があります。 たとえば、ビデオファイルをエンコードするには、ピクセルと同じサイズの文字を選択します。 文字の長さを増減すると、各文字のコード長に影響することに注意してください-結局、長さが長いほど、この長さの文字がより多く存在する可能性があります:8ビットで1と0を書く方法は16よりもはるかに少ないです。 したがって、シンボルの長さはタスクに応じて調整する必要があります。
ハフマンアルゴリズムは、優先度の高い バイナリツリーとキューを積極的に使用するため、それらに精通していない場合は、最初に知識のギャップを埋める必要があります。
「beep boop beer!」という行があるとします。これは、メモリ内で15 * 8 = 120ビットかかります。 ハフマン符号化の後、このサイズは40ビットに削減できます。 詳細に誤りがある場合、画面にchar型(0と1)の40個の要素で構成される文字列を表示します。メモリ内で正確に40ビットを占有するには、この文字列をバイナリ算術演算を使用してビットに変換する必要があります。詳細に検討してください。
したがって、「ビープブープビール!」という行を検討してください。 頻度に応じてすべての要素のコード値を構築するには、各シートに特定の文字列の文字が含まれるバイナリツリーを構築する必要があります。 葉から根までツリーを構築し、低頻度の要素が根からより遠く、より頻繁な要素が根に近づくようにします。 すぐに理由がわかります。
このようなツリーを構築するには、優先度キューを使用しますが、わずかに変更します-優先度を逆にして、最も優先度の低い要素が最も重要になるようにします。 キューは最初に最低頻度の要素を返すことがわかります。 この変更は、葉から始まるツリーの構築に役立ちます。
まず、各キャラクターの頻度を計算しましょう:
| 記号 | 頻度 |
|---|---|
| 「b」 | 3 |
| 「e」 | 4 |
| 「p」 | 2 |
| '' | 2 |
| 「o」 | 2 |
| 「r」 | 1 |
| 「!」 | 1 |
その後、各シンボルのバイナリツリー要素を作成し、それらを優先度キューとして表します。そのために頻度を使用します。
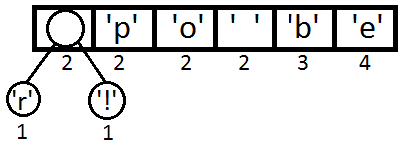
次に、キューから最初の2つの要素を取得し、それらの親となる3番目の要素を作成します。 この新しい要素を、2つの子孫の優先度の合計に等しい優先度でキューに入れます。 言い換えれば、それらの周波数の合計に等しい。
次に、前の手順と同様の手順を繰り返します。
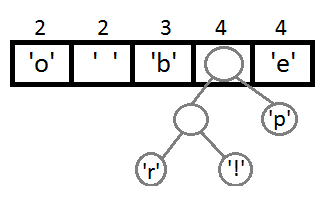
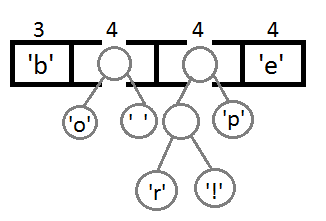
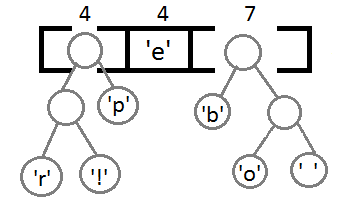
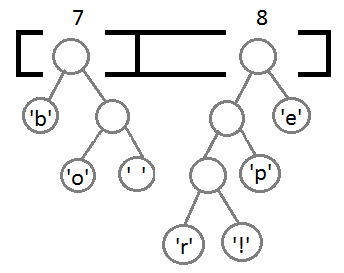
次に、新しい親を使用して最後の2つの要素を結合した後、結果のバイナリツリーを取得します。
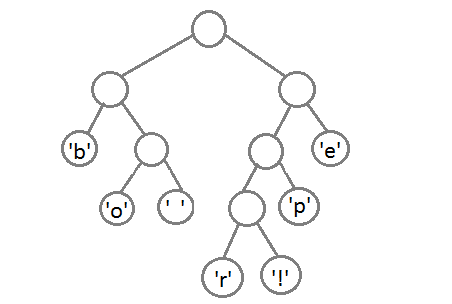
各文字にコードを割り当てることは残っています。 これを行うために、深さのウォークを開始し、毎回、右のサブツリーを考慮して、コード1で記述し、左のサブツリー-0を考慮します。
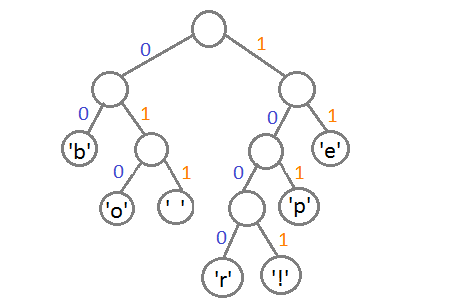
その結果、文字とコード値の対応は次のようになります。
| シボル | コード値 |
|---|---|
| 「b」 | 00 |
| 「e」 | 11 |
| 「p」 | 101 |
| '' | 011 |
| 「o」 | 010 |
| 「r」 | 1000 |
| 「!」 | 1001 |
ビットシーケンスのデコードは非常に簡単です。ツリーをトラバースする必要があります。見つかった場合は左のサブツリーを、0であれば右のサブツリーを破棄します。葉に出会うまでトラバースを続ける必要があります。 エンコードされた文字の目的の値。 たとえば、エンコードされた行「101 11 101 11」およびデコードツリーは、行「pepe」に対応します。
ここで重要なのは、コード値が他のコード値のプレフィックスではないことです。 この例では、00は文字コード「b」です。 これは、000が他の文字のコードになり得ないことを意味します。 そうしないと、デコードで競合が発生します。 結局、00を通過した後、シート "b"に到達した場合、コード値000で他の文字は検出されなくなります。
実際には、ハフマンツリーを生成した後、ハフマンテーブルも作成する必要があります。 テーブル(リンクリストまたは配列の形式)を使用すると、ツリー内の文字を検索し、同時にコードを記述するのに不合理に時間がかかるため、エンコード手順がより効率的になります。 このシンボルがどこにあるのかわからないので、最悪の場合、検索でツリー全体をソートする必要があります。 通常、エンコードにはハフマンテーブルが使用され、デコードにはハフマンツリーが使用されます。
入力行:ビープブープビール!
バイナリ入力文字列:0110 0010 0110 0101 0110 0101 0111 0000 0010 0000 0110 0010 0110 1111 0110 1111 0111 0000 0010 0000 0110 0010 0110 0101 0110 0101 0111 0010 0010 0001
コード化された文字列:0011 1110 1011 0001 0010 1010 1100 1111 1000 1001
文字列のASCIIエンコードと、ハフマンコードでの外観の大きな違いに気付くのは簡単です。
この記事ではアルゴリズムの原理のみを説明していることに注意してください。 実際に使用するには、エンコードされたシーケンスの最初または最後にハフマンツリーを追加する必要があります。 メッセージの受信者は、コンテンツからツリーを分離する方法と、テキストビューからツリーを復元する方法を知っている必要があります。 これを行うための良い方法は、事前に選択された順序でツリーを走査し、シートではない各合致アイテムに対して0、各シートに対して1を書き留めることです。 ユニットに続いて、元の文字を書き込むことができます(この例では、char、ASCIIエンコードの8ビットを入力します)。 この形式で記述されたツリーは、エンコードされたシーケンスの先頭に配置できます。解析の最初にツリーを構築した受信者は、以下に記録されたメッセージをデコードして元のメッセージを取得する方法を既に知っています。
アルゴリズムのより高度なバージョンについては、記事「 Adaptive Huffman coding 」をご覧ください。
PS (翻訳者から)
彼のリンクブログの 元の記事にリンクしてくれたbobukに感謝します。