4〜30個のパラメーターを持つ1100万個のプロファイルのデータベースでの平均検索には、それぞれ平均3.5ミリ秒かかります。 同時に、検索に加えて、Mambaデーモンサーチャーは、非常に伝統的なタスクを含め、以下を実行します。
- 特定の質問ごとに、検索の場所を示します(各ユーザーが自分のプロファイルを入力すると、「検索でN番目の場所にいます」というメッセージが表示されます)
- 主キーごとにリストから特定のプロファイルを提供します
- 指定されたパラメーターに従ってプロファイルを直接検索します
当初から検索が独自に開発されたという事実にもかかわらず、時には既知の慣らし効果が保証されたものを使用する考えがありました。 検索について考えると、Sphinxが最初に思い浮かびます。 ある時点で、それが私たちに深刻な利点を与えることができるかどうかをチェックすることにし、結果にいくらか驚きました。 200万のアンケートのテストベースでは、Sphinxはリクエストに応じて100〜120ミリ秒の平均結果を示しましたが、(これはテストであるため)インデックスのフィールドの一部のみを含めました。 同じベースおよび同じ機器での検索では、リクエストごとに0.2〜1.1ミリ秒かかります。
Sphinx: source - mysql, int sql_attr_uint. .
さらなる実践が示しているように、検索の成功の半分は正しいインデックスの作成にあります。 私たちの理解では、正しいインデックスは検索タスクと最も完全に一貫しており、最高の処理速度を提供します。 データベースの一般的な分析の後、インデックスをいくつかのコンポーネントに分割することが決定されました。
- モスクワおよび写真がある地域にあるプロファイル(これは最も頻繁に要求されるタイプのプロファイルです)
- VIPユーザーインデックス(VIPユーザーには検索結果などの特定の利点があるため、個別に処理されます)
- 各プロファイルのすべてのフィールドのすべてのタイプのプロファイルの完全なインデックス
ただし、主なトリックは一般的なインデックスの各部分の構造に隠されており、次のように構成されています。
- プロファイルはブロックごとに256プロファイルのブロックに分割されます
- 各ブロックはインデックスに配置されます:最初に、各アンケートの最初のフィールドの最初のビット、次に各アンケートの2番目のビットなど。したがって、すべてのプロファイルのフィールドからの1ビットのデータは連続します
これは検索にとって何を意味しますか? たとえば、フィールド「性別」と「年齢」にインデックスがあり、性別は値「M」と「F」を取り、年齢は18から21になります。ユーザーが20歳の女の子を見つけたいと考えます(つまり、 。条件は、各フィールドの1つの値のみを満たします)。
このようなプロファイルがあるとします(最小年齢が18であるため1ブロックが表示され、18歳は0000、19は0010、20は0100などとしてエンコードされます)
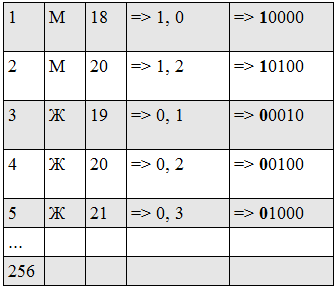
処理後、次の形式のインデックスが取得されます(最初と最後のビットは太字で表示されます)。
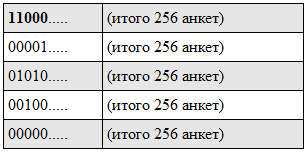
一部のフィールドでは、値は非コンパクトに保存されます。 たとえば、実年齢フィールドは64個の値を取ります。 可能な値ごとに1ビットを保存できます。つまり、フィールドは64ビットを使用しますが、検索には1つの操作しか必要なく、範囲検索には2つの操作が必要です。 より伝統的なオプションは、数値として保存することで、log2(64)= 6ビットがかかりますが、特定の年齢を検索するには6回の操作が必要で、12を超える範囲で検索します(正確な値はDNFとして記録された比較条件の長さに依存します)。
検索プロセス自体は次のとおりです。
- デーモンはリクエストを受け入れて解析します
- メモリは結果に割り当てられます(インデックス内の各プロファイルのビットごと)
- コンパイルされた要求にメモリセグメントが割り当てられ、実行フラグが設定されます
- このセグメントには次のように書かれています。
- 初期化コード、ループヘッダー
- 結果をフィルタリングする各フィールドに対して、このフィールドの値をチェックするコードが記述されます
- サイクルの終わり、境界の確認、見つかった数のカウント
- このセグメントは、通常のロングジャンプで起動されます
最も興味深いのは、フィールド検証コードです。 結果セグメントでは、各アンケートは1ビットに対応します。これは、アンケートがリクエストに適しているかどうかを示します。
要求は次のように処理されます。
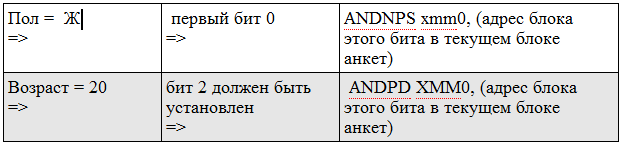
その後、結果のビットマップを調べて、どのプロファイルに1があるかを確認するだけです。
この例では、結果は00010になります。つまり、プロファイル番号4のみが要求を満たします。
「Mamba」検索デーモンは、サイト上のすべてのページのかなりの部分から呼び出されます。 他のいくつかの「メイン」デーモンとともに、JSON-RPCプロトコルを使用し、通常「単一の悪魔空間」を作成することは注目に値すると思います。
実際の検索統計は次のとおりです。
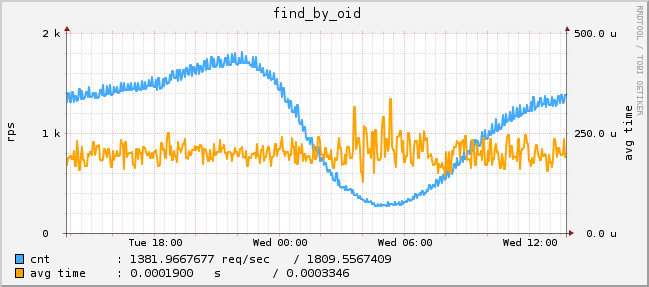
図 1 IDプロファイルによる検索要求(1つのサーバーからのグラフ)

図 2パラメーターによる検索のリクエスト(1つのサーバーからのグラフ)
合計で、検索は2台のマシンで実行され、1台のピークパフォーマンスは、1秒あたりに検出されるプロファイルの数を完全に計算したパラメーターによる2万件のアンケート検索操作です(これが最も長い操作で、残りははるかに高速です)。 ワークロード-約800 rpsの検索+場所を取得するための1000 rps +個人データを受信するための1500 rps。

図 3アンケートの場所を検索結果に表示する(1つのサーバーからのグラフ)
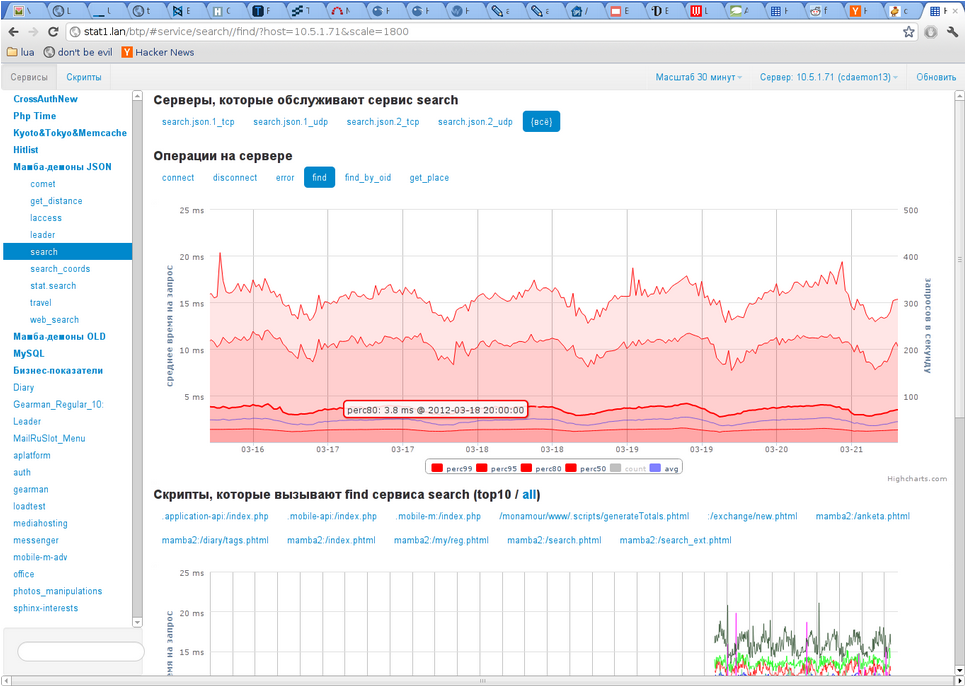
すべての(2つの)検索エンジンからの合計応答時間の分布(つまり、ネットワークインタラクションを考慮)。 平均は2.5ミリ秒、中央値は1.5ミリ秒、リクエストの5%は10ミリ秒以上、リクエストの1%は15ミリ秒以上かかります。