1.目的
この記事では、Erlangを使用してソフトウェアを開発する際に考慮すべきいくつかの側面をリストします。
2.アーランの構造と用語
すべてのErlangサブシステムはモジュールに分割されています。 モジュールは、関数と属性で構成されます。
関数は、内部モジュールまたはエクスポートして、サードパーティモジュールで使用できます。
属性は「-」で始まり、モジュールの先頭に配置されます。
Erlangアーキテクチャでのすべての作業はスレッドによって行われます。 スレッドは、さまざまなモジュールの関数呼び出しを使用できる一連の命令です。 ストリームは、メッセージを送信することで互いに対話できます。 また、受信時に、最初に処理する必要があるメッセージを判別できます。 残りのメッセージは、次の状態になるまでキューに残ります
必要はありません。
ストリームは、リンク( linkコマンド)を通じて互いの作業を監視できます。 スレッドの実行が終了またはドロップすると、関連するすべてのスレッドに信号が自動的に送信されます。
スレッドのこのシグナルに対するデフォルトの応答は、操作をすぐに終了することです。
ただし、この動作はtrap_exitフラグを設定することで変更できます。このフラグでは、シグナルがメッセージに変換され、プログラムで処理できます。
純粋な関数は、値が入力データのみに依存し、呼び出しのコンテキストに依存しない関数です。 この動作により、それらは通常の数学的動作に似ています。 純粋でない人は、副作用のある機能と言われています。
関数が次の場合、通常、副作用が発生します。
- メッセージを送信します
- メッセージを受け入れます
- exitを呼び出します
- ストリームの環境を変更するBIFを呼び出します( get / 1 、 put / 2 、 erase / 1 、 process_flag / 2など )
3設計原則
3.1モジュールから可能な限り少ない関数をエクスポートする
モジュールは、Erlangの基本的な構造単位です。 膨大な数の機能が含まれている場合がありますが、エクスポートリストに含まれている機能のみがサードパーティモジュールで利用可能になります。
モジュールの複雑さは、エクスポートされる関数の数に依存します。 同意します。数十個をエクスポートするモジュールよりも、いくつかの関数をエクスポートするモジュールを扱う方が簡単です。
結局、ユーザーはエクスポートされたもののみを理解する必要があります。
さらに、モジュールにアクセスするためのインターフェイスは変更されないため、モジュールコードに同伴する人は内部機能の変更を安全に恐れることができます。
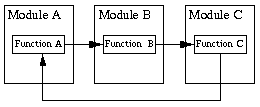
3.2モジュール間の依存関係を減らしてみてください
非常に多くの他のモジュールに対処するモジュールは、変更する場合、メンテナンスがはるかに困難です。
インターフェイスを使用する場合、このモジュールを使用した場所でコードを変更する必要があります。
理想的には、モジュール呼び出しはループを使用したグラフではなくツリーにする必要があることに注意してください。 (私から。このため、 Wranglerリファクタリングツールには、関数呼び出しのグラフを描画できるGraphVizベースの便利なメカニズムがあります)
その結果、コールコードは次のように表示されます。

ではなく:
3.3一般的に使用されるコードのみをライブラリに入れます。
ライブラリ(モジュール)では、関連する関数のみのセットにする必要があります。
開発者のタスクは、同じタイプの関数を含むライブラリを作成することです。
したがって、たとえば、 リストを操作するためのコードを含むリストライブラリは優れたアーキテクチャの例であり、リストを操作するためのコードと数学的アルゴリズムの両方を含むlists_and_methodは悪い例です。
とりわけ、ライブラリ内のすべての関数に副作用が含まれていない場合。 その後、簡単に再利用できます。
3.4「ハッキング」と「ダーティコード」を別々のモジュールに分離する
多くの場合、問題を解決するには、「クリーン」コードと「ダーティ」コードを使用する必要があります。
そのようなセクションを異なるモジュールに分けます。
たとえば、「ダーティコード」:
- プロセス辞書を使用
- erlang:process_info / 1を使用して、適切な目的ではありません:)
- 当初は期待していなかったことを行いますが、
できるだけきれいなコードを作成し、「ダーティ」なコードを作成し、最初はできるだけ使用しないでください。次に、考えられるすべての副作用と使用上の問題を文書化します。
3.5呼び出し元の関数が結果をどのように使用するかについて考えないでください
呼び出し元の関数があなたの結果をどのように使用するかについて考えないでください。
たとえば、 ルート関数を呼び出して、正しくない可能性のある引数を渡したとします。 route関数の作成者は、引数が正しくない場合に何をするかを考えるべきではありません。
同様のコードを書く必要はありません:
do_something(Args) -> case check_args(Args) of ok -> {ok, do_it(Args)}; {error, What} -> String = format_the_error(What), io:format("* error:~s\n", [String]), %% Don't do this error end.
これを行う方が良いです:
do_something(Args) -> case check_args(Args) of ok -> {ok, do_it(Args)}; {error, What} -> {error, What} end. error_report({error, What}) -> format_the_error(What).
前者の場合、エラーは常にコンソールに表示され、後者の場合、エラーの説明が単に返されます。 アプリケーション開発者は、それをどう処理するかを自分で決めることができます。それを無視するか、 error_report / 1で印刷させます 。 いずれにせよ、彼はエラーが発生した場合の対処方法を選択する権利を保持します。
3.6コードロジックから一般的なパターンと動作を抽出する
コード内で何らかの動作が繰り返される場合は、別の関数またはモジュールに分離するようにしてください。 したがって、プログラム全体に散らばる複数のコピーよりも保守がはるかに簡単になります。
「コピー&ペースト」を使用せず、機能を使用してください!
3.7トップダウン設計
プログラムを上から下に設計します。 これにより、プリミティブ関数に到達するまでコードを徐々に改良できます。 この方法で記述されたコードは、データの表示に依存しません。これは、より高いレベルで開発しているときには表示がまだわからないためです。
3.8コードを最適化する必要はありません
開発の初期段階でコードを最適化しないでください。 まず、正常に機能するようにし、必要な場合にのみ最適化を行います。
3.9予測可能なコードを書く
関数の結果は、ユーザーを驚かせるべきではありません。 同様のアクションを実行する関数は、同じように見えるか、少なくとも類似している必要があります。 ユーザーは、関数が返すものを予測できる必要があります。 実行結果が期待どおりでない場合、関数名が目的に一致しないか、関数コード自体が正しく機能しません。
3.10副作用を回避しよう
Erlangには、副作用のあるプリミティブがいくつかあります。 それらを使用する関数は、環境に依存しており、プログラマは呼び出す前にストリームの状態を制御する必要があるため、再利用するのはそれほど簡単ではありません。
副作用なしで可能な限り多くのコードを記述します。
非純粋関数を使用する場合に起こりうるすべての問題を明確に文書化します。 これにより、テストとサポートの記述が大幅に容易になります。
3.11内部データがモジュールから出ることを許可しない
例で説明するのが最も簡単です。 キュー管理機能があるとします:
-module(queue). -export([add/2, fetch/1]). add(Item, Q) -> lists:append(Q, [Item]). fetch([H|T]) -> {ok, H, T}; fetch([]) -> empty.
彼女はキューをリストとして説明します。 そして、このようなものを使用しました:
NewQ = [], % Queue1 = queue:add(joe, NewQ), Queue2 = queue:add(mike, Queue1), ....
これからいくつかの問題が発生します。
- キューがリストであることを知る必要があります
- 将来、ビューを別のビューに変更することはできません(たとえば、最適化が必要な場合)
このように書く方がはるかに良いです:
-module(queue). -export([new/0, add/2, fetch/1]). new() -> []. add(Item, Q) -> lists:append(Q, [Item]). fetch([H|T]) -> {ok, H, T}; fetch([]) -> empty.
これで使用方法は次のようになります。
NewQ = queue:new(), Queue1 = queue:add(joe, NewQ), Queue2 = queue:add(mike, Queue1), …
このコードには、上記の欠点がありません。
ここで、キューの長さを知る必要があるとします。 ユーザーがキューがリストであることを知っている場合、次のように記述します。
Len = length(Queue) %
繰り返しますが、問題は、ユーザーが実装をビューに厳密に関連付けているため、このようなコードは維持および読み取りが困難です。 この場合、別の関数を提供してモジュールに追加することをお勧めします。
-module(queue). -export([new/0, add/2, fetch/1, len/1]). new() -> []. add(Item, Q) -> lists:append(Q, [Item]). fetch([H|T]) -> {ok, H, T}; fetch([]) -> empty. len(Q) -> length(Q).
これで、ユーザーは自分のコードの代わりにqueue:len(Queue)を呼び出すことができます。
このコードでは、データ型キューの実装の詳細から「抽象化」しました。 つまり つまり、キューは「抽象データ型」になりました。
なんでこんな面倒なの? 実際には、内部表現を置き換えるための簡単なメカニズムであることが判明し、ユーザーコードとの後方互換性を損なうことを恐れることなく、モジュールの実装を変更できるようになりました。 たとえば、実装を改善するために、コードは次のように書き直されます。
-module(queue). -export([new/0, add/2, fetch/1, len/1]). new() -> {[],[]}. add(Item, {X,Y}) -> % {[Item|X], Y}. fetch({X, [H|T]}) -> {ok, H, {X,T}}; fetch({[], []) -> empty; fetch({X, []) -> % fetch({[],lists:reverse(X)}). len({X,Y}) -> length(X) + length(Y).
3.12コードをできるだけ決定的にする
確定的プログラムは、実行された回数に関係なく常に同じように動作します。 非決定的なものは、開始ごとに異なる動作をする可能性があります。 最初のオプションはデバッグがはるかに簡単であり、多くのエラーを追跡して回避できるため、それに固執するようにしてください。
たとえば、プログラムは5つの異なるスレッドを開始し、それらが開始したことを確認する必要があります。開始の順序は重要ではありません。
5つすべてを一度に開始してからチェックすることもできますが、スレッドが開始されたかどうかを確認するたびに、次のスレッドを開始するように順番に開始することをお勧めします。
3.13入力データの正確性を常に確認する必要はありません
多くの場合、プログラマは、開発中のシステムの一部に対する入力を信頼しません。 ほとんどのコードは、送信されるデータの正確さを気にする必要はありません。 検証は、データが外部に送信される場合にのみ発生する必要があります。
例:
%% Args: Option is all|normal get_server_usage_info(Option, AsciiPid) -> Pid = list_to_pid(AsciiPid), case Option of all -> get_all_info(Pid); normal -> get_normal_info(Pid) end.
Optionがnormallまたはallでない場合、関数は失敗します 。 そうでしょう! この関数を呼び出す人は、渡されるものを制御する必要があります。
3.14ハードウェアロジックをドライバーに分離する
ドライバを使用して、機器をシステムから隔離する必要があります。 ドライバーのタスクは、システム内のハードウェアを単なるErlangストリームであるかのように提示することです。これは、単純なストリームのように、メッセージを送受信し、エラーに応答します。
3.15同じ機能で元に戻すアクション
ファイルを開き、それを使って何かを実行してから閉じるコードがあるとします。
do_something_with(File) -> case file:open(File, read) of, {ok, Stream} -> doit(Stream), file:close(Stream) % Error -> Error end.
ファイルのオープンとクローズは同じ機能で発生することに注意してください。 コードは読みやすく、理解しやすいです。 しかし、たとえば、そのようなコードは理解するのが難しく、ファイルが閉じられたときにすぐには明確ではありません。
do_something_with(File) -> case file:open(File, read) of, {ok, Stream} -> doit(Stream) Error -> Error end. doit(Stream) -> ...., func234(...,Stream,...). ... func234(..., Stream, ...) -> ..., file:close(Stream) %%
4エラー処理
4.1通常のコードから処理を分離する
通常のコードとエラー処理コードを混在させないでください。 通常の動作をプログラムする必要があります。 問題が発生した場合、プロセスはすぐにエラーで終了します。 エラーを修正して続行しようとしないでください。 エラー処理には別のプロセスが必要です。
4.2「コアエラー」を強調表示する
開発の段階の1つは、システムのどの部分が常にエラーなしで機能し、どのエラーが許容されるかを決定することです。
たとえば、オペレーティングシステムでは、カーネルはエラーなしで機能する必要がありますが、通常のアプリケーションはエラーでクラッシュする可能性がありますが、これはシステム全体の機能には影響しません。
常に正しく動作するはずの部分を「エラーのカーネル」と呼びます。 この部分は、原則として、データベースまたはディスクに中間状態を継続的に保存します。
5ストリーム、サーバー、メッセージ
5.1 1つのモジュールにすべてのストリームコードを実装する
もちろん、スレッドは他のモジュールから関数を呼び出すことを理解する必要がありますが、ここでは、スレッドのメインループが複数のモジュールに分割されてはならず、1つのモジュール内にあるべきであるという事実について話します。 そうしないと、進行を制御するのが難しくなります。 これは、 汎用ライブラリを使用しないことを意味するものでもありません。 これらは、フローの整理に役立つように設計されています。
また、いくつかのスレッドに共通のコードは、完全に独立したモジュールに実装する必要があることを忘れないでください。
5.2スレッドを使用してシステムを構築する
ストリームは、システムの基本的な構造要素です。 ただし、単に関数を呼び出すことが可能な場合は、それらを使用してメッセージを送信しないでください。
5.3登録済みストリーム
ストリームは、コードを含むモジュールの名前と同じ名前で登録する必要があります。 これにより、サポートが大幅に促進されます。 長期間使用する予定のストリームのみを登録します。
5.4物理的に並列なアクションごとにシステムにスレッドを1つだけ作成します
スレッドを使用するか、問題を順番に解決するかは、解決しようとしている問題に直接依存します。 ただし、1つの主なルールに沿ってガイドすることをお勧めします。
「実世界の並列プロセスごとに1つのスレッドを使用します。」
この規則に従えば、プログラムロジックは理解しやすくなります。
5.5各スレッドには1つの「ロール」のみが必要です
ストリームはシステム内でさまざまな役割を果たすことができます。 たとえば、クライアント/サーバーアーキテクチャでは、スレッドはクライアントとサーバーの両方になることができますが、2つの役割を2つのスレッドに分けることをお勧めします。
その他の役割:
- スーパーバイザー( Supervisor ) -フローを監視し、落下後にフローを再起動します。
- worker( worker ) -エラーが発生する可能性のある通常の実行ストリーム。
- 信頼できるスレッド(またはシステム、 信頼できるワーカー ) -エラーが発生してはならないスレッド。
5.6 汎用機能を使用してサーバーを作成し、可能な限りプロトコルを操作する
ほとんどの場合、 gen_serverを使用してサーバーを作成するのが最良のソリューションです。システムの構造を大幅に促進するためです。 これは、データ転送プロトコルの処理にも当てはまります。
5.7メッセージへのタグの追加
すべてのメッセージにはタグが必要です。 タグ付きメッセージは、 受信ブロックでの順序は重要ではなく、新しいメッセージのサポートを追加する方が簡単であるため、管理が簡単です。
そのようなコードを書くべきではありません:
loop(State) -> receive ... {Mod, Funcs, Args} -> % apply(Mod, Funcs, Args}, loop(State); ... end.
メッセージ処理{get_status_info、From、Option}を追加し、その処理を最初のブロックの下に配置する必要が生じた場合、競合が発生し、新しいコードは実行されません。
メッセージが同期の場合、結果にもタグを付ける必要がありますが、リクエストとは異なります。 例:タグget_status_infoでリクエストする場合、応答status_infoが来るはずです。 このルールに準拠すると、デバッグが非常に容易になります。
正しいコードの例を次に示します。
loop(State) -> receive ... {execute, Mod, Funcs, Args} -> % apply(Mod, Funcs, Args}, loop(State); {get_status_info, From, Option} -> From ! {status_info, get_status_info(Option, State)}, % loop(State); ... end.
5.8コードに不明なメッセージのキューをクリアする
キューオーバーフローを回避するために、各サーバーは、たとえば次のように、着信するすべてのメッセージを処理する必要があります。
main_loop() -> receive {msg1, Msg1} -> ..., main_loop(); {msg2, Msg2} -> ..., main_loop(); Other -> % error_logger:error_msg( "Error: Process ~w got unknown msg ~w~n.",[self(), Other]), main_loop() end.
5.9サーバーの作成時に末尾再帰を使用する
メモリオーバーフローを回避するには、すべてのサーバーを末尾再帰を使用して実装する必要があります。
次のように書くべきではありません:
loop() -> receive {msg1, Msg1} -> ..., loop(); stop -> true; Other -> error_logger:log({error, {process_got_other, self(), Other}}), loop() end, io:format("Server going down"). % % !
このように良い:
loop() -> receive {msg1, Msg1} -> ..., loop(); stop -> io:format("Server going down"); Other -> error_logger:log({error, {process_got_other, self(), Other}}), loop() end. %
5.10サーバーへのアクセスインターフェイスを作成する
可能な限りメッセージを直接送信するのではなく、関数を使用してサーバーにアクセスします。
メッセージングプロトコルは内部情報であり、他のモジュールでは使用できません。
例:
-module(fileserver). -export([start/0, stop/0, open_file/1, ...]). open_file(FileName) -> fileserver ! {open_file_request, FileName}, receive {open_file_response, Result} -> Result end. ...<code>...
5.11タイムアウト
メッセージを受信するときにafterを使用する場合は、細心の注意を払ってください。 タイムアウト後にメッセージが到着する状況になっていることを確認してください。 (5.8節を参照)。
5.12出力信号の傍受
できるだけ少ないスレッドでtrap_exitフラグを設定する必要があります。 しかし、それを使用するかどうかは、モジュールの目的に依存します。
6アーランコードの推奨事項
6.1 レコードを使用して構造を保存する
レコードデータ型は、内部Erlangビューのタグ付きタプルです。 彼はErlang 4.3で初めて登場しました。 レコードは、Cの構造体またはPascalのレコードに非常に似ています。
レコードが複数のモジュールで使用される予定の場合、その定義はヘッダーファイルに配置する必要があります。
レコードは 、モジュール間でデータを転送するときにモジュール間の互換性を確保するために最適に使用されます。
6.2セレクターとコンストラクターを使用する
セレクターとコンストラクターを使用して、 レコードを制御します。 レコードを隠蔽として使用しないでください。
例:
demo() -> P = #person{name = "Joe", age = 29}, #person{name = Name1} = P,% matching ... Name2 = P#person.name. %
次のようなレコードを使用しないでください。
demo() -> P = #person{name = "Joe", age = 29}, {person, Name, _Age, _Phone, _Misc} = P. %
6.3タグ付き関数の結果を返す
このように書かないでください:
keysearch(Key, [{Key, Value}|_Tail]) -> Value; %% ! keysearch(Key, [{_WrongKey, _WrongValue} | Tail]) -> keysearch(Key, Tail); keysearch(Key, []) -> false.
このソリューションでは、 {Key、Value}に値としてfalseを含めることはできません。 正しいコードは次のとおりです。
keysearch(Key, [{Key, Value}|_Tail]) -> {value, Value}; %% . keysearch(Key, [{_WrongKey, _WrongValue} | Tail]) -> keysearch(Key, Tail); keysearch(Key, []) -> false.
6.4キャッチとスローに注意して使用する
何をしているのかわからない場合は、 catchとthrowを使用しないでください。
キャッチアンドスローは、外部入力データ、または複雑な処理(たとえば、コンパイラーによるテキスト処理)が必要なデータを処理するときに役立ちます。
6.5プロセス辞書の使用には細心の注意を払ってください
何をしているのかわからない場合は、 getおよびputを使用しないでください。
putとgetを使用する関数は、別の引数を追加することで簡単に書き換えることができます。
次のように書かないでください。
tokenize([H|T]) -> ...; tokenize([]) -> case get_characters_from_device(get(device)) of % get/1! eof -> []; {value, Chars} -> tokenize(Chars) end.
より良い書き換え:
tokenize(_Device, [H|T]) -> ...; tokenize(Device, []) -> case get_characters_from_device(Device) of % eof -> []; {value, Chars} -> tokenize(Device, Chars) end.
putおよびgetを使用すると、関数が非決定的になります。 この場合、デバッグははるかに複雑です。 関数の実行結果は、入力データだけでなく、プロセスディクショナリにも依存します。 さらに、エラー時のErlang(たとえば、 bad_match )は、その時点でのストリームディクショナリの状態ではなく、関数呼び出しの引数のみを説明に表示します。
6.6 インポートを使用しない
インポートコードは読みにくいです。 モジュール関数のすべての定義が1つのファイルにある方が良いです。
6.7関数のエクスポート
関数がエクスポートされる理由を区別する必要があります。
- それらへの外部アクセスを有効にするには
- ユーザーにインターフェースを提供するには
- モジュール自体からのspawnまたはapplyを介した呼び出しの場合。
グループ-exportおよびエクスポートの理由についてコメントします。
%% -export([help/0, start/0, stop/0, info/1]). %% -export([make_pid/1, make_pid/3]). -export([process_abbrevs/0, print_info/5]). %% -export([init/1, info_log_impl/1]).
7.コードの文体および字句設計に関する推奨事項
7.1深くネストされたコードを書かない
強くネストされているとは、多くのcase / if / receiveブロックが他のケース / if / receiveブロックにネストされているコードを指します。 ネストのレベルが2つ以上あるのは悪い形式と見なされます。 このようなコードは読みにくいです。 そのようなコードを小さな関数に分割することをお勧めします。
7.2大きすぎるモジュールを書かないでください
モジュールには、400行を超えるコードを含めないでください。 そのようなモジュールをいくつかの小さなモジュールに分割することをお勧めします。
7.3長すぎる関数を書かない
関数は15〜20行より長くしないでください。 1行だけを書いて問題を解決しようとしないでください。
7.4 1行に多くの文字を書き込まない
1行の文字数は80を超えてはなりません(A4に収まるように)。
Erlangでは、ラッピング後に宣言された行は自動的に一緒に接着されます。
例:
io:format("Name: ~s, Age: ~w, Phone: ~w ~n" "Dictionary: ~w.~n", [Name, Age, Phone, Dict])
7.5変数の命名
変数の正しい(意味のある)名前を選択するのは非常に難しい作業です。
変数名が複数の単語で構成されている場合は、 「_」で区切るか、 CamelCaseを使用することをお勧めします
関数内の変数を無視するために'_'を使用しないでください; '_'で始まる変数の名前、たとえば_Nameをより適切に記述してください 。
7.6関数の命名
関数の名前は、その目的を明確に反映する必要があります。 結果は、名前に基づいて予測可能でなければなりません。 標準関数の標準名( start 、 stop 、 init 、 main_loop ...など)を使用します。
異なるモジュールの関数ですが、同じ目的で、同じように呼び出す必要があります(たとえば、 Module:module_info() )。
間違った関数名の選択は、最も一般的な間違いです。
関数名のいくつかの規則により、この選択がはるかに簡単になります。 たとえば、接頭辞「is_」は、実行結果がtrueまたはfalseになることを意味し ます 。
is_...() -> true | false check_...() -> {ok, ...} | {error, ...}
7.7モジュールの命名
Erlangにはフラットモジュールの命名モデルがあります。 たとえば、Javaのようなパッケージはありません(正確には、実際にはありますが、実際のアプリケーションは、メリットよりも多くの問題をもたらします)。
通常、モジュールが何らかの方法で接続されていることを示すために、同じプレフィックスが使用されます。 たとえば、ISDNは次のように実装されます。
isdn_init
isdn_partb
isdn_ ...
7.8コードの一貫性を保つ
統一されたスタイルにより、開発者は互いのコードを理解しやすくなります。
すべての人々は、さまざまな方法でコードを書くことに慣れています。
たとえば、誰かがスペースでタプル要素を定義します
{12, 23, 45}
なしの誰か
{12,23,45}
統一されたスタイルを自分で開発したら、すぐにそれを守ってください。
8コードのドキュメント
8.1コード属性
ヘッダーのモジュール属性を常に正しく設定する必要があります。 このモジュールのアイデアがどこから来たのかを説明し、コードが別のモジュールでの作業の結果として登場した場合は、それを説明してください。
コードを盗むことはありません。 盗難は、ソースを指定せずにコードをコピーしています。
属性の例:
-revision( 'Revision:1.14')。
-created( 'Date:1995/01/01 11:21:11')。
-created_by( 'eklas @ erlang')。
-modified( 'Date:1995/01/05 13:04:07')。
-modified_by( 'mbj @ erlang')。
8.2仕様へのリンクを残す
コードに何らかの標準が実装されている場合は、ドキュメントへのリンク(RFCなど)を残してください。
8.3すべてのエラーを文書化する
すべてのエラーは、別個の文書に明確に説明する必要があります。
論理的なものが可能な場所のコードで、 error_loggerを呼び出します 。
error_logger :error_msg( Format 、{ Descriptor 、 Arg1 、 Arg2 、....})
また、{Descriptor、Arg1、Arg2、....}がエラーの説明ドキュメントに記載されていることを確認してください。
8.4メッセージで送信されるすべてのタイプのデータを文書化する
タグ付きタプルをストリームによって転送されるメッセージとして使用します。
使用してレコードをメッセージには、異なるモジュール間の互換性を保証します。
これらのすべてのデータ型をメッセージ記述文書に文書化します。
8.5コメントコード
コメントは冗長であってはなりませんが、コードを理解するには十分でなければなりません。常に最新の状態に保ちます。
モジュールに関するコメントはインデントされ、%%%で始まる必要があります。
関数に関するコメントはインデントされ、%%で始まる必要があります。
コードに対するコメントは、そのように整列し、%で始まる必要があります。このようなコメントは、コードの上またはコードと同じ行に配置する必要があります。同じ行に配置するのがより好ましいです。
%%関数
some_useful_functions( UsefulArgugument) ->
another_functions( UsefulArgugument)についてのコメント
、%行末のコメント%同じインデントレベル
complex_stmntでのcomplex_stmnt についてのコメント、
...
8.6各機能に関するコメント
以下を文書化することが重要です。
- この機能の目的
- 有効な入力エリア
- 出力エリア
- 関数が何らかのアルゴリズムを実装している場合、それを記述してください
- この関数のクラッシュの可能性、呼び出しの存在exit / 1およびthrow / 1、エラーの可能性。
- 副作用
例:
%% ------------------------------------------------ ----------------------
%%機能:get_server_statistics / 2
%%目的:プロセスからさまざまな情報を取得します。
%% Args:オプションは通常です| all。
%%戻り値:{Key、Value}
%%または{error、Reason} のリスト(プロセスが
停止している場合)%% --------------------- -------------------------------------------------
get_server_statistics( Option、 Pid) when pid( Pid) ->
...
8.7データ構造
レコードは説明とともに定義する必要があります。例:
%%ファイル:my_data_structures.h
%% ----------------------------------------- ----------------------------
%%データ型:person
%%ここで:
%% name:文字列(デフォルトは未定義)。
%% age:整数(デフォルトは未定義)。
%% phone:整数のリスト(デフォルトは[])。
%% dict:個人に関するさまざまな情報を含む辞書。
%% {Key、Value}リスト(デフォルトは空のリストです)。
%% ------------------------------------------------ ----------------------
-レコード(人、{名前、年齢、電話 = []、辞書 = []})。
8.8ファイルヘッダー、著作権
各ファイルは著作権情報で始まる必要があります。 例:
%%% ----------------------------------------------- ----------------------
%%% Copyright Ericsson Telecom AB 1996
%%% %%%著作
権所有。このコンピュータープログラムのいかなる部分も、
使用、複製、検索システムへの保存、送信、
形式、手段を問わず、電子的、機械的、コピー、
記録、%%%、それ以外の場合、
%%% Ericsson Telecom ABの事前の書面による許可なし。
%%% ----------------------------------------------- ----------------------
8.9ファイルヘッダー、バージョン履歴
各ファイルには、誰がどのような変更を何の目的で行ったかを示すバージョン履歴が必要です。
%%%---------------------------------------------------------------------
%%% Revision History
%%%---------------------------------------------------------------------
%%% Rev PA1 Date 960230 Author Fred Bloggs (ETXXXXX)
%%% Intitial pre release. Functions for adding and deleting foobars
%%% are incomplete
%%%---------------------------------------------------------------------
%%% Rev A Date 960230 Author Johanna Johansson (ETXYYY)
%%% Added functions for adding and deleting foobars and changed
%%% data structures of foobars to allow for the needs of the Baz
%%% signalling system
%%%---------------------------------------------------------------------
8.10 ,
各ファイルは、モジュールの目的の簡単な説明とエクスポートされた関数のリストで始まる必要があります。
%%%---------------------------------------------------------------------
%%% Description module foobar_data_manipulation
%%%---------------------------------------------------------------------
%%% Foobars are the basic elements in the Baz signalling system. The
%%% functions below are for manipulating that data of foobars and for
%%% etc etc etc
%%%---------------------------------------------------------------------
%%% Exports
%%%---------------------------------------------------------------------
%%% create_foobar(Parent, Type)
%%% returns a new foobar object
%%% etc etc etc
%%%---------------------------------------------------------------------
コードの使用に関する問題を認識している場合、または何かが不完全な場合は、ここで説明してください。これは、コードをさらにサポートするのに役立ちます。
8.11古いコードにはコメントしないでください-削除してください
古いコードを削除し、バージョン管理システムに説明を残します。CSVが役立ちます。
8.12バージョン管理システムの使用
多かれ少なかれ複雑なプロジェクトはバージョン管理を使用する必要があります(Git、SVNなど)
9よくある間違い
複数のページに
関数を書く入れ子になったケースが多い関数を書く/ if / receive
タグなしの関数を書く関数
名が機能の目的に対応しない
変数の悪い名前
フローが必要でない場合の使用
データ構造の間違った選択(表示の
不備)コメントの不足またはコメントの欠如
コードインデントはせずに
使用プット / 取得
悪い制御メッセージキューを
10ドキュメント
このブロックでは、サポートと管理のためにプロジェクトに必要なドキュメントについて説明します。
10.1モジュールの説明
モジュールごとに1つの章。各モジュールの説明と、エクスポートするすべての機能の説明が含まれている必要があります。
- 約束
- 入力説明
- 出力の説明
- 考えられる使用上の問題とexit / 1呼び出し。
10.2メッセージの説明
モジュール内でのみ使用されるメッセージを除く、システムで使用されるメッセージの説明
10.3スレッドの説明
すべての登録済みストリームとそれらへのインターフェースの説明。
動的に作成されたすべてのストリームとそれらへのインターフェイスの説明。
10.4エラーの説明
考えられるすべてのシステムエラーの説明。