そしてすぐに、必要なデータを2つまたは3つ見つけるためにシャベルで削る必要があるデータがどれだけ少なくなるかが明らかになります。 独創的。 シンプル。 なるほど。
そして個人的には、このスキームを改善する場所はどこにもないように常に思えました...クラスタインデックスに精通するまで。 「通常の」インデックスでは、すべてがそれほどバラ色ではないことが判明しました。
したがって、クラスタ化インデックスとは、非クラスタ化インデックスよりも優れているもの、およびMySQLがそれをどのように使用しているかです。
非クラスター化インデックス
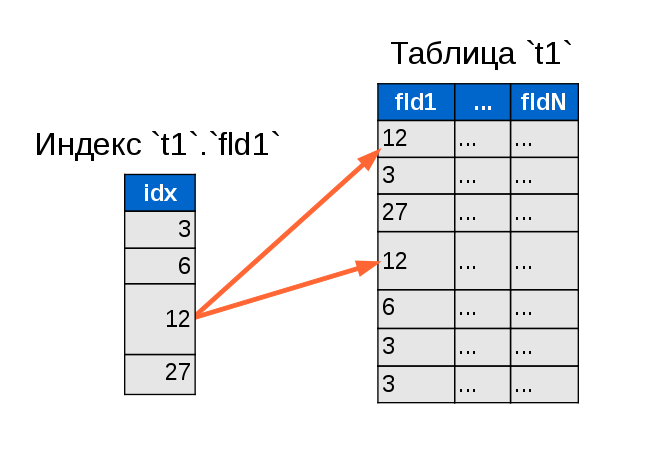
混乱しないように、当面は1つのフィールドの単純なインデックスを検討します。 単純化された非クラスター化インデックスは、データテーブル内の1つ以上の行を参照する各行の個別のテーブルとして表すことができます。 インデックステーブルの行は、キーフィールド値によって順序付けられ、グループ化されます。 基本クエリを想像してください:
SELECT * FROM `t1` WHERE `fld1` = 12;
インデックスを作成しない場合、各行が読み取られてチェックされ、条件を満たさない行は結果に含まれません。 しかし、それらは読まれます。
「通常の」非クラスター化インデックスを使用すると、検索タスクが大幅に高速化されます。 まず 、インデックステーブルの重量はデータテーブルよりもはるかに少ないため、簡単に高速に読み取れます。 第二に 、DBMSはほとんどの場合、インデックスをRAMにキャッシュしようとしますが、RAM自体はハードディスクよりもはるかに高速です*。 第三に、インデックスに重複する行はありません。 これは、最初の値が見つかったらすぐに検索を停止できることを意味します。これも最後の値です。 4番目に、インデックス内のデータがソートされます。 そして3番目と4番目に、それらは一緒にバイナリ検索アルゴリズム(別名半分に分割する方法)の使用を可能にし、その有効性は単純な網羅的検索よりも何倍も大きいです。
*リソースが許可する場合、データテーブルをRAMにキャッシュすることもできます(キャッシュする必要があります)。 ただし、明らかな理由から、インデックスとRAM内のインデックスの場所にもっと注意を払うのが習慣です。
インデックス作成は大きな力です。 しかし、すべてのインデックステーブルポインターをデータテーブルの行に同時に送信すると、かなり複雑な「Web」が得られます。

そして、多数の交差する矢印があるこのウェブは、非クラスターインデックスが作成する問題(それを明確に示しているだけです)をもたらします。
フラグメンテーション
MySQLオプティマイザーは、小さなテーブルを検索するためにインデックスを使用しないことを決定する場合があります(最大数十のレコード-特定のデータ構造とインデックスに依存します)。 なんで? 検索は単にデータを順番にブルートするだけだからです。 また、インデックスポインターは、異種のデータを指します。 また、インデックスからリンクにジャンプすると、最終的には完全な検索よりも費用がかかります。
それで、インデックス作成の進化のこの段階では何がありますか。 大きなインデックス付きの断片化されたテーブルを想像してください。 データが混oticとして整理されていないため、データは保存されました。 ここで、インデックステーブルを想像してください。 そして私たちの古き良きリクエスト:
SELECT * FROM `t1` WHERE `fld1` = 12;
何が起こっているの? インデックス内の値が見つかりました-すばやく簡単です-このインデックスが参照する行はデータテーブルから読み取られます。 当然、テーブルの大きな断片化により、テーブルのさまざまな部分から読み取るオーバーヘッドが顕著になります。
そして、ここでは私たちにとって便利です...
クラスターインデックス
ブックの目次がアルファベット順のインデックスと異なるのと同じように、クラスタインデックスは非クラスタ化インデックスと異なります。 正確な単語(値)のアルファベット順インデックス(非クラスター化インデックス)は、正確なページ番号(データベース内の行)を提供します。 目次は、特定の章に対応するページの範囲を示しており、検索ワードはすでに検索されています。 さらに、各章が十分に大きい場合は、独自の目次を含めることができます。
クラスタ化インデックスは、インデックス値がそれに対応するデータとともに格納されるツリー状のデータ構造です。 このような組織では、インデックスとデータの両方が整理されます。 テーブルに新しい行を追加する場合、ファイル*の最後ではなく、フラットリストの最後ではなく、ソートによってそれに対応するツリー構造の目的のブランチに追加されます。
*異なるエンジンおよび異なる設定では、これはまったく終わりではなく、ファイルでもありません。 ここでいうファイルとは、「1つのテーブルに対応するデータの特定の単位」を意味し、「ファイルの終わり」は、シーケンシャルな線形レコードのシンボルとして使用されます。
MySQLの最も強力で生産的なエンジンの1つはInnoDBです。 これには多くの理由があり、その1つはクラスターインデックスです。 クラスター化インデックスがどのように配置されているかを理解する最も簡単な方法は、それらを動的に想像することです。データが追加されるにつれてどのように成長するか、テーブルがどのように分岐し始めるかです。
ステージ1:フラットリスト
InnoDBデータは16 Kbページに保存されます。 1ページのサイズは、分岐が開始するツリー構造のノードの最大サイズです。 テーブル全体が1ページに収まる場合、独立したインデックステーブルなしで、キーフィールドでソートされたフラットリストとして格納されます。
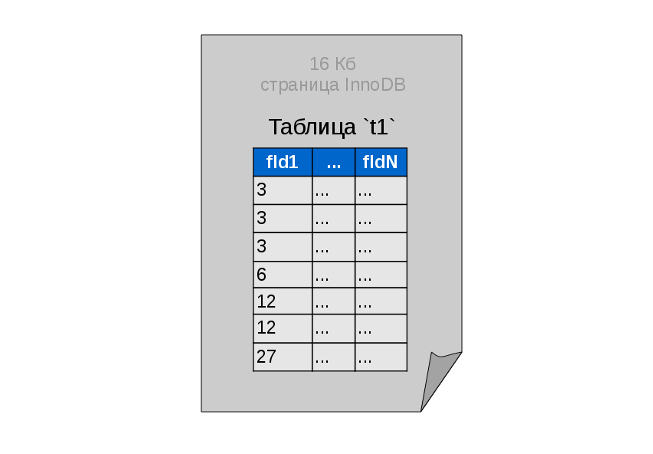
将来、すべてのデータはまったく同じ小さなプレートで表示され、インデックスページのチェーンはそれらをツリーに接続します。
第二段階:ツリー
データが1ページに収まらなくなると、リストはツリーに変わります。 データページは2つに分割され、データがあったノード(そのページ)には、両方の新しいページをカバーするインデックスがあります。 そのようなツリーの特定のノードには、ノードが最後の場合、すべての子ノードまたは最終データのインデックスを含める必要があります。 ノードは、親から子への一方向のみで相互に参照できます。
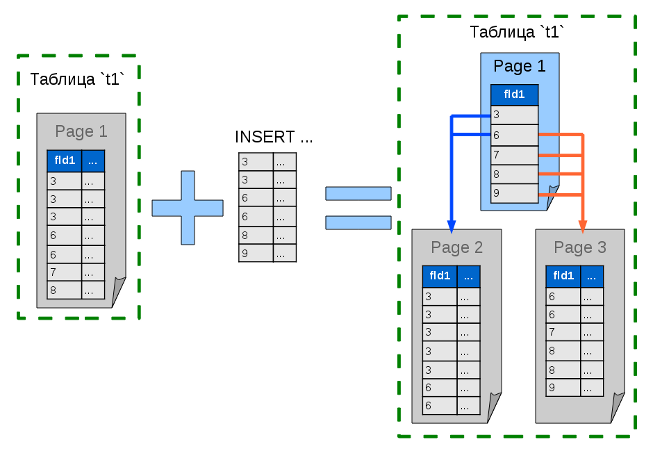
より多くのデータを追加すると、ツリーはより複雑で深くなります。 そして、分岐が多いほど、データを格納するためのこのようなスキームが大きくなります。
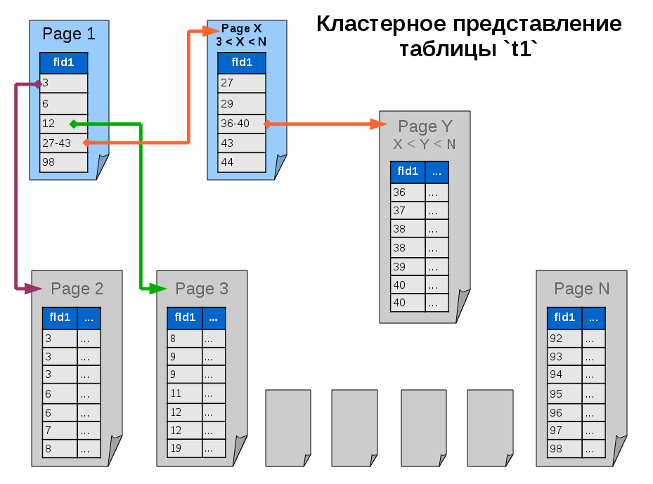
灰色のページは最初の段階のページと同じです-これらは単純にソートされたデータであり、ツリーのリーフ(リーフノード)です。 ブルーページは、インデックスのみを含み、データを含まないツリーの中間ノードです。 矢印は、特定のキー値の検索パスを示します。
クエリを思い出してください(緑色の矢印):
SELECT * FROM `t1` WHERE `fld1` = 12;
テーブルに戻ると、クエリは最初のページに移動し、インデックスを受信します。インデックスは、検索条件に一致する行があるデータを含む最終ページにすぐに送信します。 このページは検索段階ですでに読み取られており、すべてのデータが収集されており、データベースは応答を返すことができます。
ただし、別のページを指すインデックスが必ずしもデータページに直接つながるとは限りません。 インデックスは、中間インデックスを持つページを指す場合があります。 おそらく、テーブルのボリュームが大きい場合、データベースは検索の反復をより多く実行する必要がありますが、そのような各反復には最小限のデータが含まれるため、一般に、検索は高速になります。
ここでは、あらゆるタイプのインデックスに関連する単純なルールが適用されます。データが多様であるほど、インデックスを使用して特定の値を検索する方が効率的です。
データはインデックスの一部であり、ソートされ、意図的に断片化されているため、テーブルごとに使用できるクラスターキーは1つだけであることは明らかです。 インデックスとデータを格納するこのかなり複雑なロジックから、別の重要な結果があります。書き込み操作、特にキーフィールドの既存データの変更は、非常にリソースを消費するプロセスです。 クラスター化インデックスにはめったに変更されないフィールドを使用するようにしてください。
複雑な(複合)クラスターキーについては、まったく同じスキームが適用され、データのみが2つのフィールドでソートされます。 インデックス自体は、非クラスター複合キーとほとんど異なりません。
InnoDBのクラスターキー
ここではすべてが簡単です。 各InnoDBテーブルにはクラスターキーがあります。 それぞれ。 例外なし。
どのフィールドがこのために選択されるかは、はるかに興味深いです。
- PRIMARY KEYがテーブルで指定されている場合、これはそれです
- そうではなく、テーブルにUNIQUE(ユニーク)インデックスがある場合-これが最初です
- それ以外の場合、InnoDBは6バイトのサロゲートIDを持つ非表示フィールドを個別に作成します
苦労しているサーバーを3番目のポイントに移動せずに、IDを自分で追加する方が良いでしょう。
また、セカンダリキーのInnoDBがテーブルの終了行への参照としてクラスターキーフィールド値の完全なセットを格納することを忘れないでください。 プライマリキーが大きいほど、セカンダリキーも大きくなります。