この記事では、冗長データの作成に適した方法の使用に関する理論的な部分を分析します。 そして実用的な部分は、あなたが現時点で使用できるものです。 失望を避けるために、私が書いているのは比較的最近の科学的発展であるため、実際的な部分はかなり貧弱です。 しかし、私はそのようなタスクのためのプログラムを開発したい人々の注目を集めたいと思っています。
すぐに退却したいです。 記事では英語の用語消去コードを意図的に使用しています-ロシア語ではこの用語を見つけられませんでした。 これらはエラー修正コードではありません。 誰もが知っていて教えてくれたら、感謝します。
理論
コード
幸いなことに、データの可用性レベルを低下させることなく、占有ディスク容量とトラフィックの両方を節約できる別のアプローチがあります。 これらは消去コードです。
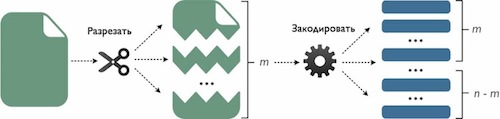
消去コードの本質は、特定のファイルをエンコードした後、n個のフラグメントが取得されることです(実際の実装では、これらもファイルです)。 これらのフラグメントのm個のサイズは、元のファイルと同じです。 さらに、 n> mです。 各フラグメントは、個別のクラウドストレージに保存されます。 元のファイルを復元するには、 m個のフラグメントを収集してデコードするだけです。 残りのnmフラグメントは、削除、破損、それらを含むクラウドストレージが利用できないなどの可能性があります。 したがって、消去コードを使用するシステムは、 n-mエラーの発生を処理できます。
さらに深く掘り下げたい人のために、MDS消去コードについて説明します。 他の種類のコードがあり、それらのプロパティはわずかに異なります。 興味があれば、すべての数学で詳細に説明できます。
なぜこのアプローチが優れているのか
冗長データサイズ
nとmの比率を選択できます。 たとえば、 n = 2 * mになるようにパラメーターを設定できます。この場合、エンコードされたデータのサイズは元のサイズのちょうど2倍になります。 たとえば、 m = 5、n = 10とします。 次に、コーディング後のフラグメントは10個になります。 1つのフラグメントのサイズは、ファイルサイズとmの比率に等しくなります。 これらのフラグメントのうち5つを収集して合計サイズを計算すると、元のファイルのサイズと等しくなります。 各フラグメントは、10個のクラウドストレージのいずれかに保存されます。 同時に、5つのストレージが一度に使用できなくなる場合がありますが、ユーザーデータの可用性には影響しません。ファイルを復元できます。
数学表記では、このように見えます。 ファイルサイズがLだとしましょう。 1つのフラグメントのサイズはp = L / mであり、冗長データの合計サイズは2 * Lです。 復元に必要なすべてのフラグメントのサイズはL = p * mです。
複製と比較してください。 5つのクラウドストレージに障害が発生する可能性のあるシステムを使用するには、6つのクラウドストレージが必要であり、各クラウドストレージにはファイルのコピーが保存されています。 この場合、システムに保存されるデータのサイズはファイルサイズの6倍になります。 消去コードを使用している間は、元のファイルの2倍のサイズの冗長データを保存する必要があります。
したがって、消去コードを使用するときに一定数のエラーが発生しても生き残ることができるシステムでは:
- 各サーバーで、より少ないデータを保存する必要があります
- 保存されるデータの合計サイズはかなり小さくなります
- 総クラウドストレージがさらに必要
最後の段落は、最初の2つのメリットを上回る場合もあれば、上回る場合もあります。 それはすべて特定の状況に依存します。 これについては、興味があればコメントで議論できます。
交通
これは明らかです。 保存する必要があるデータの量が少ない場合、保存に費やされるトラフィックの量は比例して少なくなります。 プラス消去コードに向かって。 いずれかのケースで復元する場合-複製または消去コードが使用されるかどうかにかかわらず、転送されるデータのサイズは元のファイルのサイズであるLと等しくなります。
コーディングに費やした時間
明らかに、レプリケーションコーディングは必要ありません。 コードの使用はどれくらい遅いですか? このようなテストは非常に多くあります。 512メガバイトのファイルをエンコードするのに、平均で4秒もかかりませんでした(テストを1000回繰り返しました)。 構成は次のとおりでした-3ギガバイトのRAM、3 GHz Intel Core 2 Duoプロセッサを搭載したコンピューター。 オペレーティングシステム-11.10 Ubuntu。 コーデックとして、有名なJerasureライブラリを使用しました。 現在のバージョンは githubにあります。
まとめ
消去コード:
- 冗長データが占有するディスク容量を、個別のサーバーとすべての組み合わせの両方で節約できます
- 同じ可用性レベルでは、レプリケーションを使用するよりも多くのサーバーが必要です。
- データがサーバーに保存されるときに発信トラフィックを節約できます(これはバックアップ中に最も頻繁に発生します)
- ユーザー時間のコーディングデータを使う
- それにもかかわらず、特にネットワーク上のデータ転送速度と比較して、コーディング速度は非常に高い
練習する
実際に、プロバイダーの声明だけでなくデータの安全性と可用性が保証されるようにデータを保存したいので、このトピックを掘り下げ始めました。 したがって、現在の状況を改善する最も簡単な方法は、クラウドストレージの1つに保存されたコピーに加えて、データの少なくとも1つ以上のコピーを保持することです。 または、ローカルコピーのほかにもう1つコピーします。
混乱したい場合。 このアプローチには、いくつかの若い実装があります。 遊ぶ以上に、私は2つの理由でそうしません。 まず、彼らは実際には非常に若く、私のデータは私にとって重要なものです。 2番目の正当な理由は、すべてのプロジェクトにおいて、機密性の観点からデータセキュリティの一部が不十分であるということです。 これについては第3部で書くと約束しました。
これまでのところ、私はあなたの注意おもちゃに提示します:
NCCloudは最新のコードを使用します-コードを再生成します。 これらのコードを使用する主な口実は、1つまたは複数のクラウドにエラーがあり、データにアクセスできず破損した場合のトラフィックを減らすことです。 同時に、そのようなコードからデータを回復する機能は低下します(この記事で説明したものと比較して、同じレベルのアクセシビリティがあります)。 私はこのアプローチに根本的に反対します。 その理由は簡単です。 ネットワークノードが表示されたり消えたりするp2pネットワークにデータが保存されている場合、このようなコードは重要な役割を果たします。 クラウドを使用する場合、各クラウドの可用性は非常に高く、エラーはほとんど発生しません。 したがって、データ回復プロセスはほとんど発生しません。 このプロセス中にトラフィックを節約することは、その有効性を悪化させますが、私には合理的ではないようです。
NubiSaveは、 Reed-Solomon Cauchyコードを使用して冗長データを作成します。 データのエンコードは段階的に行われます。つまり、1つのデータブロックがエンコードされた時点で、前のブロックは既にクラウドストレージにアップロードされています。 これにより、ユーザーの待ち時間が短縮されます。 アーキテクチャの利点は、データ処理を柔軟に構成できることです(暗号化するか圧縮するか)。 重大な欠点は、暗号化とプライバシーの実装全体がこれまで考えられていなかったことです(これについては、記事の別の部分で繰り返します)。
ところで、一部のクラウドプロバイダーは既に消去コードを使用しています。 たとえば、Wualaからの適切なソリューション 。