0.最初に単語があり、この単語がありました:「ドキュメント」
悲しいことに、ロシア語で良い記事と新鮮なドキュメントを検索した結果、 こことここにある有用な情報ソースが2つだけになりました 。 これらの記事は両方ともPDFの本質を一般的に理解するのに非常に役立ちましたが、私に設定されたタスクをまったく解決しませんでした。 そして彼は現場にやって来ました-ISO 3200-1。 756ページのこの巨人は、車と時間の小さなカートを引き換えに食べて、私を実際に救った。
それでも、PDFを使用するすべての人に、参考として次のことを強くお勧めします。
ここで国際標準ISOのWebサイトで購入する
ここからダウンロード
そして、 ここアドビのサイトから
1.言葉から行動へ。 注意! 挑戦する
最短時間でPHPでPribludaを作成する必要がありましたが、平均で6〜40 MBのPDFが期待されていたため、メモリを多少節約できました。 同時に、彼女はページのコンテンツを抽出し、テキストを論理ブロック(段落と見出し)に分割し、写真と目次を抽出する必要がありました。
2a。 ちょっとした理論。 オブジェクトのテーブルを受け取ります。
まず、少しの理論。 メモ帳で開いたPDFファイルの例を次に示します

ファイルには、奇妙なkrakozablikに加えて、意味のあるテキストもあり、これは喜ばせざるを得ないことを肉眼で見ることさえできます。 私たちがすべてを理解するのを助けるのは彼です。
判明したように(そしてここでISO 3200-1が役立った)、PDFの構造はおよそ次のとおりです。
最初の行はPDFバージョンを説明しています。 2つ目は、不必要だとは思わなかった不思議なラインです。 私はそれが私たちの宇宙の真の本質を隠していると認めていますが、一般に。 次はオブジェクトの説明です。
オブジェクトは、PDFに保存されているすべてのデータとその論理接続を記述する普遍的な構造です。 各オブジェクトは、「NM obj」(引用符なし)という形式の見出しで構成されます。Nはオブジェクトの番号、Mはそのバージョンです(名誉のために、M!= 0のオブジェクトに出会ったことがないことに注意してください)。 オブジェクトのタイトルの後に、プロパティが<< >>にあります。 最後に、オプションで、ストリームのペアであるendstreamに囲まれたデータストリームがあります。 オブジェクトのすべての部分は、改行で区切られています。 これらの要素については後で詳しく説明します。 それまでの間、オブジェクトからPDFドキュメントの最後の部分に移動しましょう
相互参照テーブル -ファイル内の各オブジェクトのアドレスを含む特定のテーブル。 このテーブルの構造は次のとおりです。

最初の行は、xrefキーワードです。 2番目は2つの数字で、どちらがオブジェクトを記述するかを示します。 その後、テーブル自体が来ます。 0000000032 65535 fの形式の各行は、対応する番号のオブジェクトを記述しています。 一部のテーブルでは、番号付けは最初のオブジェクトではなく、xrefキーワードの後の行で説明されているオブジェクトで始まることを忘れないでください。 最初の桁のグループ:10桁(値は左側の無意味なゼロで補完されます)は、オブジェクトの開始元のファイル内のアドレスを示します。
UPD:欠陥を指摘してくれてありがとう。 修正しました。
2番目のグループ:オブジェクトのリビジョン番号を示す65535(int)以下の5桁。 最後の文字は、n(使用済みオブジェクトの場合)またはf(空きオブジェクト(削除済み)の場合)です。 オブジェクトを削除すると、そのリビジョン番号(世代)が1増加し、(n / f)フラグがfに設定されます。 さらに、リビジョン番号を65535に設定できます。このようなオブジェクトは無料と見なされ、二度と使用されません。 PDFドキュメントの40ページで詳細を読む
テーブルの直後にキーワードトレーラーがあり、その後にテーブルのプロパティがあります。 1つだけ興味があります:/前321249。ここで、番号は、前のテーブルが始まるファイル内のアドレスを示します。 したがって、最初のテーブルにはこのようなプロパティはありません。
テーブルのプロパティの後に、別のキーワードstartxrefがあります。その後に、このテーブルの先頭のアドレスを示す番号があります。
この知識は、すべてのPDFオブジェクトのテーブルをアンロードするのに十分であるため、将来、PDF全体をメモリにロードする必要はありません。 さあ、ビールを飲んで練習しましょう。
2b。 実際の理論。 オブジェクトのテーブルを受け取ります。
ヌス。 採石場に行きましょう。 これが私のgovnokodの一部です。
private function get_ref_table(){ $currentString = ''; $matches=NULL; $tableLength = 0; $lastTable = false; /* 32 , , */ fseek($this->filePointer, -32, SEEK_END); $nextTableLink=''; /* -32 , startxref */ while(preg_match('/startxref/', $nextTableLink)!=1 && $nextTableLink!==false){ $nextTableLink = fgets($this->filePointer); } $nextTableLink = fgets($this->filePointer); while($lastTable!== true){ // fseek($this->filePointer, $nextTableLink, SEEK_SET); // fgets($this->filePointer); $currentString = fgets($this->filePointer); // preg_match('/(\d+)\x20(\d+)/', $currentString, $matches); $tableLength = $matches[2]; $startIndex = $matches[1]; // for($i=0; $i<$tableLength; $i++){ $currentString = fgets($this->filePointer); preg_match('/(\d+)\x20\d+\x20\x6E/', $currentString, $matches); if(isset($matches[1])) $this->RefTable[$startIndex+$i]=$matches[1]; } fgets($this->filePointer); $currentString = fgets($this->filePointer); // , // if(preg_match('/\x2FPrev\x20(\d+)/', $currentString, $matches)==1) $nextTableLink = $matches[1]+0; else $lastTable = true; } // asort($this->RefTable, SORT_NUMERIC); reset($this->RefTable); $pointerKey=NULL; // // , // . foreach($this->RefTable as $key => $value){ if($pointerKey!=NULL) $this->RefTableNext[$pointerKey]=&$this->RefTable[$key]; $pointerKey = $key; } if($pointerKey!=NULL) $this->RefTableNext[$pointerKey]= $nextTableLink; }
一般に、コードのすべてが明確になっていると思います。最後のテーブルのアドレスを見つけ、その値を配列に保存し、テーブルのトレースのアドレスを読み取ります。 最後のテーブルを作成するのは、PHPでは配列の次の要素を知ることが難しいためです。 私の場合、目的の要素を検索するたびに配列全体を実行するよりも、余分なテーブルを保存する方が簡単でした。
RefTable ['object number'] = 'Object address'という配列ができたので、単純な関数を使用してオブジェクトごとにファイルを読み取ることができます。 たとえば、次のように:
public function get_obj_by_key($key){ fseek($this->filePointer, $this->RefTable[$key]); return fread($this->filePointer, $this->RefTableNext[$key]-$this->RefTable[$key]); }
3a。 もう少し理論。 ページテーブルを取得します。
オブジェクトに戻り、より正確にはそれらのプロパティに戻りましょう。 PDFには9つの主要なデータタイプがあります。
ブール -True、False。
数値 -int(623、+ 17、-98)、実数(34.5、-3.62)
LiteralString-括弧内の文字セット(abcd)
16進文字列-<4E6F7620> 16進値の文字列。
名前 -/前の文字セットのスラッシュフィールド
配列 -[/ name 1 / name1 / name2]任意のタイプのオブジェクトの配列
ディクショナリ -キーと値のタイプのセット。キーは常にタイプName(/ Prev)のオブジェクトであり、値は他のディクショナリを含む任意のタイプのオブジェクトです。 辞書は常に<< >>で囲まれています
ストリーム -とにかくエンコードできるデータ。
NULL-それ自体を語る
詳細については、ドキュメントの14ページを参照してください。
そのため、オブジェクトのプロパティは辞書(辞書)に保存されます。 そしてまず、奇妙なことに、オブジェクトの型が配置されている/ Typeプロパティに興味があります。 最初に、2つのオブジェクトを見つけます:/タイプ/カタログおよび/タイプ/ページ、プロパティの形式で、サービス情報とデータ構造を持つオブジェクトへのリンクが保存されます。 ここでは、プロパティ/ページがタイプ/タイプ/ページのオブジェクト番号2 0 Rにマッピングされていることがわかります。
テーブルの番号2にあるオブジェクト/タイプ/ページは、プロパティに番号付きの配列/キッズ[3 0 R 29 0 R]を含むという点で重要です。 この配列にあるオブジェクトは、別のノード/タイプ/ページとそれらの/キッズ、またはオブジェクト/タイプ/ページ、つまりページです。
そして、冷たい暗闇のボトルが来ます。
3b。 コードに戻ります。 ページテーブルを取得します。
取得する関数は次のとおりです
private function get_page_table(){ $currentObj = ''; reset($this->RefTable); $key = key($this->RefTable); $matches = NULL; $nextPage = NULL; $pages = array(); // , /Type/Catalog while((preg_match('/\x2F\x54\x79\x70\x65\x2F\x43\x61\x74\x61\x6C\x6F\x67/',$currentObj) != 1) || ($currentObj === false) ){ $currentObj = $this->get_obj_by_key($key); next($this->RefTable); $key = key($this->RefTable); } // /Pages N 0 R preg_match('/\x2F\x50\x61\x67\x65\x73\x20(\d+)\x20\x30\x20\x52/', $currentObj, $matches); $currentObj = $this->get_obj_by_key($matches[1]); preg_match('/\x2FKids\[(.*)\]/',$currentObj, $kids); // preg_match_all('/\s?(\d+)\s\d+\sR/',$kids[1], $matches); foreach($matches[1] as $value){ $pages[] = $value; } foreach($pages as $key => $value){ if(isset($this->RefTable[$value])){ $page=$this->get_obj_by_key($value); // – , if(preg_match('/\/Type\/Page\W/',$page) == 1){ $this->pageTable[] = $value; } // $this->pageTable = array_merge($this->pageTable,$this->getChildren($value)); } } return true; }
次は、子供のページを見つけるのに再帰的に役立つヘルパー関数です。
private function getChildren($Obj){ $pages = array(); $pagesArr = array(); $currentObj = $this->get_obj_by_key($Obj); preg_match('/\x2FKids\[(.*)\]/',$currentObj, $kids); if(isset($kids[1])){ if(preg_match_all('/\s?(\d+)\s\d+\sR/',$kids[1], $matches) > 0){ foreach($matches[1] as $value){ $pages[] = $value; } foreach($pages as $key => $value){ if(isset($this->RefTable[$value])){ $page=$this->get_obj_by_key($value); if(preg_match('/\/Type\/Page\W/',$page) == 1){ $pagesArr[] = $value; } $pagesArr = array_merge($pagesArr,$this->getChildren($value)); } } return $pagesArr; } else return array(); } return array(); }
さて、奇跡が起こりました。オブジェクト番号->オブジェクトのアドレスのテーブルがあり、ページ番号->オブジェクト番号のテーブルがあります。 残っているのは小さいことだけです。ページのコンテンツを取得し、論理構造に分割します。
4a。 理論が帰ってきた。 ストリームからデータを取得します。
オブジェクトの後に奇妙な文字の束を見つけることができる場合もあれば、オブジェクトの/ Resourcesプロパティでリンクを見つけることができるオブジェクトにそれらが見つかることもあります。 これはエンコードされたデータです。 そのようなオブジェクトのディクショナリには、単一の値または配列のいずれかを割り当てることができる/ Filterプロパティがあります(重要!オブジェクトの後のデータは暗号化されないことがあります。この場合、/ Filterプロパティはありません。Zhoshkolnikでもストリームを読み取ることができます) 可能性のあるすべてのフィルターのリストは、22ページの資料にありますが、ここで詳しく説明します。 / Filter / FlateDecode-これは最も一般的なフィルターであり、99%のケースで十分です。 FlateDecodeは通常のgzipに過ぎず、必要なのはgzuncompress($ストリーム)だけです。 ひとつだけありますが。 FlateDecode規格によると、データの最初の4ビットはオーバーヘッド文字であり、解釈されませんが、一部のPDFではこれらのビットが存在せず、gzuncompress()データエラーが発生する場合があります。 私はあなたを喜ばせることができます:1人の若い男性が我々のためにパッチを書きました。 ここに行って読む
そして、そのような仲間を連れて、ストリームからデータを抽出したことを意味します。
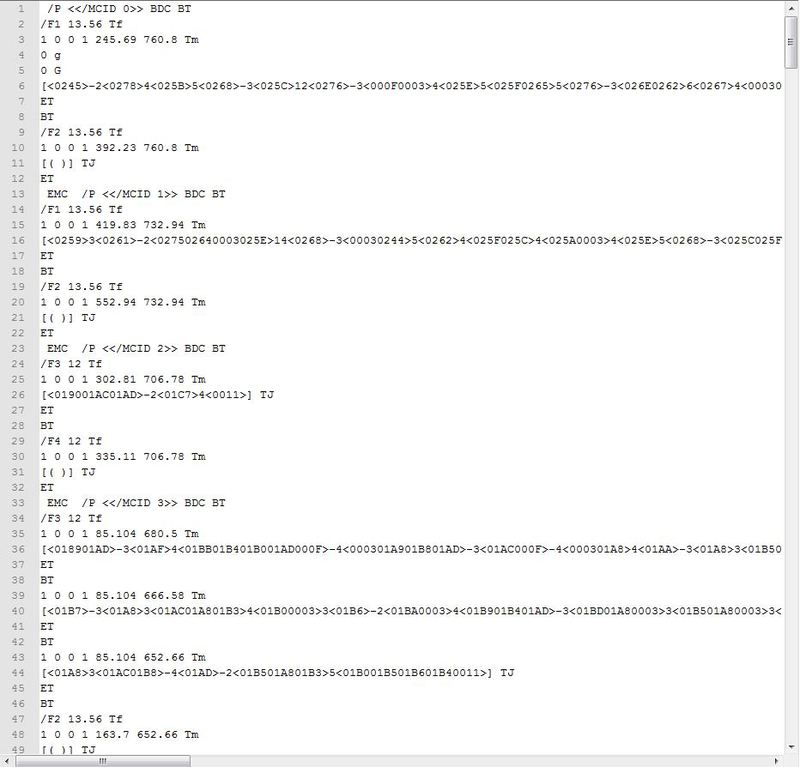
そして、テキストがあります。 次の行に興味があります。
BTで終わる行。 BTのみが参加することが判明するかもしれません
Tfで終わる行。 テキストのブロックで使用されるフォントについて説明します。
TJで終わる文字列。 その中に、テキスト自体(ほとんど)があります。
まあ、すべてのETは終了します
例をよく見てみましょう
/ P << / MCID 0 >> BDC BT
/ F1 13.56 Tf
1 0 0 1 245.69 760.8 Tm
0 g
0 g
[<0245> -2 <0278> 4 <025B> 5 <0268> -3 <025C> 12 <0276> -3 <000F0003> 4 <025E> 5 <025F0265> 5 <0276> -3 <026E0262> 6 < 0267> 4 <00030262> 6 <00030266> 7 <0268> -3 <026A> -3 <025F0011>] TJ
ET
BTとETは、テキストの始まりとテキストの終わりにすぎません。 BTの前には、テキスト内の論理構造(段落および見出し)を実際に強調するのに役立つマーカーがあります。この記事では、これについて詳しく説明しません。 このような各ブロック<< / MCID 0 >>、</ / MCID 1 >>などを段落の始まりと見なすか、556ページのドキュメントの「論理構造」セクションでそれらについて読むことができます。 誰もが興味がある場合-私は記事を補足することができます。
フォント行では、/ F1と数字に興味があります。 / F1-テキストをデコードする必要があるフォントの名前(はい、はい、私たちの苦しみはまだ終わっていません)とテキストスタイルを取得します
[]のTJの前には、切望されたテキストがあります。 これで幸運を得ることができ、テキストが表示されます。 空白のテキストは常に括弧で囲まれます。 幸運でなく、幸運な場合は、三角形の括弧で囲まれた数字のグループを見つけます。 4桁ごとに1つの文字があり、16進数の値は対応表にあり、先ほど見つけたフォントオブジェクトの対応表、アヒルのうさぎ、卵のアヒル...おっと...
文字コードのテーブルを見つけるのは難しくありません。デコードしたページには/ Resourcesプロパティがあり、その中に<< / Font << / F1 5 0 R / F2 10 0 R / F3 12 0 R…………すでに何をすべきか推測:対応するフォントのオブジェクト番号に移動し、そのオブジェクト(これは冗談ではありません)にプロパティ/ ToUnicode 98 0 Rがあります。そこにテーブルがあります。 それをどうするかは、 Habrでよく説明されていました 。 十分な情報がない場合は、添付するソースをご覧ください。
今のところすべてです。 これは単なる一般的な概要でした。 興味がある場合は、画像、カタログ、表、スタイル、その他のパンを抽出する方法について詳しく説明します。 ご質問があれば、歓迎します。 そして、はい、私はあなたにコードをあまりトロールしないでください、それは読まれるふりをしません、それは全体として本質を説明することだけです。
最後に、一般的な理解のための小さなコード。