
ユーザー(マトリックス行)が製品(マトリックス列)に割り当てた評価(いいね!、購入ファクトなど)で構成される非常にまばらなマトリックスがあることを思い出してください。

私たちのタスクはグレードを予測することです
 すでにマトリックスに配置されているいくつかの推定値を知る
すでにマトリックスに配置されているいくつかの推定値を知る  。 私たちの最高の予測は
。 私たちの最高の予測は 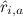 。 これらの予測を取得できる場合は、1つ以上の製品を選択する必要があります。 最大。
。 これらの予測を取得できる場合は、1つ以上の製品を選択する必要があります。 最大。
2つのアプローチに言及しました:類似ユーザーの検索-これは「ユーザーベースのコラボレーションフィルタリング」と呼ばれるか、類似製品の検索-これは論理的に「製品ベースの推奨」と呼ばれます(アイテムベースのコラボレーションフィルタリング)。 実際、どちらの場合も基本的なアルゴリズムは明確です。
- データベース内の他のユーザー(製品)がこのユーザー(製品)にどのように似ているかを調べます。
- 他のユーザー(製品)の推定によると、このユーザーがこの製品に与える評価を予測するには、このユーザーに類似するユーザー(製品)の重みが大きいと仮定します。
これをすべて行う方法を理解するだけです。
最初に、「類似」の意味を判断する必要があります。 私たちが持っているのは、各ユーザーの好みのベクトル(行列Rの行)と、各製品のユーザー評価のベクトル(行列Rの列)だけです。 まず、これらのベクトルには、両方のベクトルの値がわかっている要素のみを残します。 両方のユーザーが評価した製品のみ、または両方ともこの製品を評価したユーザーのみを残します。 結果として、実数の2つのベクトルがどれだけ似ているかを判断する必要があります。 これはもちろんよく知られた問題であり、その古典的な解決策は相関係数を計算することです:2つのユーザー選好ベクトルiとjに対して、ピアソン相関係数は
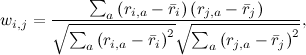
どこで
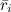 -ユーザーiによる平均評価。 ベクトル間の角度のコサインを使用して、いわゆる「コサイン類似性」を使用する場合があります。
-ユーザーiによる平均評価。 ベクトル間の角度のコサインを使用して、いわゆる「コサイン類似性」を使用する場合があります。
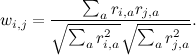
ただし、コサインが適切に機能するためには、まず各ベクトルの平均を減算することをお勧めします。したがって、実際にはこれは同じメトリックです。
たとえば、推定値のマトリックスを考えます。

好みの手動分析は読者に任せ、ユーザーベースの推奨事項については、Vasyaの好みベクトルとシステムの他の部分との相関を計算します。
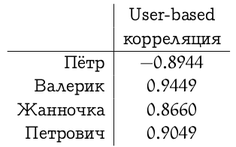
現在、ユーザーベースの推奨事項の式を提供しています。 アイテムベースのアプローチでは、状況は似ていますが、1つの注意点があります:異なるユーザーは異なる評価を持ち、誰かが5つの星を一列に並べる(すべてのサイトを一列に並べる)、そして逆に誰かがすべてに従って2つまたは3つの星(「嫌い」を押すことが多い)。 最初のユーザーにとっては、低い評価(「嫌い」)が高い評価よりもはるかに有益であり、2番目のユーザーにとっては、その逆です。 ユーザーベースのアプローチでは、相関係数がこれを自動的に処理します。 また、アイテムベースの推奨では、これを考慮するために、たとえば、各評価からユーザーの平均評価を減算し、ベクトル間の角度の相関または余弦を計算できます。 次に、コサインの式で
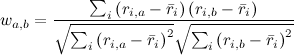 、
、
どこで
ユーザーiによる平均評価を示します。 この例では、推定の各ベクトルから平均を引くと、次のようになります。

そして、映画「Tractors」の評価ベクトルと他の映画の評価の相関関係は次のようになります(「Once Upon a Tractor」では、重複する評価が少なすぎたため、状況が悪化していることに注意してください)
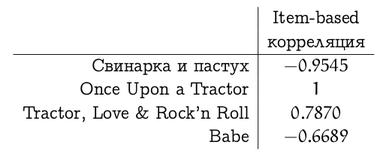
これらの類似性の測定には欠点があり、トピックに関するさまざまなバリエーションがありますが、メソッドの説明に限定しましょう。 したがって、計画の最初のポイントを見つけました。 次に、これらの類似性評価(重み
 )?
)?
単純かつ論理的なアプローチは、新しい評価を特定のユーザーの平均評価に加えて、これらの重みで重み付けされた他のユーザーの平均評価からの偏差に近似することです。
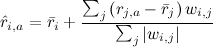 。
。
このアプローチはGroupLensアルゴリズムとも呼ばれます-これはGroupLensレコメンダーシステムの祖父が働いた方法です(ちなみに、しゃれを許して、 MovieLensの Webサイトをお勧めします)。 。 VasyaとTractor Driversの場合、この方法では約3.9の推定値が予想されるため(Petrovichはわずかに失望させます)、安全に監視できます。
アイテムベースの推奨事項については、すべてが完全に同等です。ユーザーがすでに評価した製品の加重平均を見つけるだけです。

この例の項目ベースの方法は、Vasyaが4.4の「トラクタードライバー」を提供することを前提としています。
もちろん、理論的にはこれはすべて良いことですが、実際には、各推奨事項について何百万人ものユーザーからのデータを要約することは不可能です。 したがって、この式は通常、k人の最近傍-このユーザーに最も類似しており、すでにこの製品を評価しているk人のユーザーまで粗くされます:
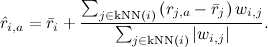
最も近い隣人をすばやく探す方法を理解するだけです。 これはすでに議論の範囲を超えているので、2つの主な方法に名前を付けます。小さな次元では、kdツリー(kdツリー、たとえば、 この紹介を参照)を使用でき、大きな次元では、ローカルセンシティブハッシュ(ローカルセンシティブ)に役立ちますハッシュ;たとえば、 こちらをご覧ください )。
そのため、今日、ユーザー(製品)と他のユーザー(他の製品)の類似性を評価し、このメトリックの最近傍の意見に基づいて推奨する最も単純な推奨アルゴリズムを調べました。 ところで、これらのメソッドが完全に時代遅れであると考えるべきではありません-多くのタスクにとって、それらは素晴らしい働きをします。 ただし、次のシリーズでは、利用可能な情報のより微妙な分析に進みます。 特に、最初から入力データを永続的に「評価マトリックス」と呼んでいましたが、ベクトルのセット(メソッドに応じて行または列のいずれか)ではなく、実際にマトリックスであるという事実を使用したことはないようです。 次回-使用します。
PS数式を含む画像のmathURLサービスに感謝します。 残念ながら、彼はロシア語の文字を理解していないため、VasyaとPetrovichについての表は手作業で作成する必要がありました。