書き方
ある冬の長い夜、私の妻はBookworm adventuresをプレイし、定期的に利用可能な手紙からより本物の言葉を構成することについて私を蹴りました。 一連の文字から単語を作成できるページをインターネット上ですばやく検索すると、サーバー側でこれを実行しようとするサイトと、Javaクライアントアプレットでこれを実行するサイトが多数あります。 サーバーの容量で単語を構成するものは、文字セットのサイズに制限があるか(通常、何らかの理由で8)、「abcdefghijklmnopqrstuvwxyz」が送信される場合は深く考えます。 ただし、Javaアプレットには12文字の制限があり、スマートに機能し、ほぼ適切でした(ゲームでは単語を作成するために16文字が提供されます)。
Javaアプレットの隣には、17万の英単語の辞書がありました。 その少し前に、プレフィクスツリーを使用して解決することになっているタスクにインタビューし、質問しました。その後、プレフィクスツリーに関するすべての知識の恥ずかしいことに、頭に名前があり、それを使用した経験はありませんでした。 したがって、このギャップを埋めることが決定されました。
私は
すべての仕組み
問題のステートメントは次のとおりです。ユーザーは文字で構成される文字列を入力します。ユーザーが入力した文字で構成されるすべての単語を辞書で検索し、各文字を複数回使用する必要はありません。 この文字が対応する回数だけ出現する単語を検索する場合、ユーザーは文字を複数回指定することを禁止されていません。
ウィキペディアが言うように( 英語はより冗長です)、プレフィックスツリーは辞書の単語のプレフィックス(つまり、最初の数文字)を格納するツリーです。 ツリーの構造は、ルートの後に続くツリーの各レベルが、前のレベルに関連するプレフィックスの次の文字を格納するようなものです。 文字を含まない空のプレフィックスは、ツリーのルートに保存されます。 ツリーのルートから緑豊かな頂点までのパスに沿って移動し、訪問した頂点の文字を左から右に書くと、パスの最後に辞書から単語が得られます。 ただし、単語は必ずしも葉の頂点で終わるわけではないことに注意してください。たとえば、単語BAD、CAB、CAD、DAB、AB、AD、BAの辞書は次のツリーで表されます。
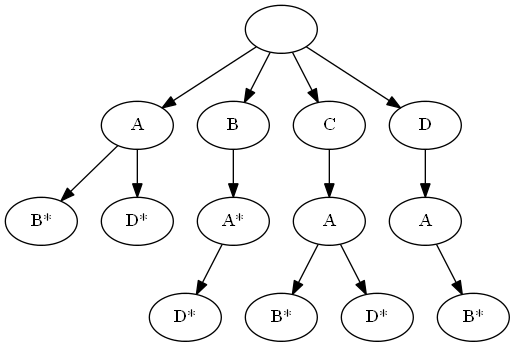
アスタリスクは、単語が終わるノードを示します。
そのため、プログラムでは、ツリーはルートノードへのリンクで表されます。各ノードは
data
フィールドを持つJavascriptオブジェクトであり、ノードに対応する文字が格納されます。 単語がこのノードで終わる場合は
terminator
。 そして、対応するレターのサブツリーを格納する子ノードへのリンクを含む、1文字の名前を持つ多数のフィールド。 つまり JSONの形式の図からのツリーの最初のレベルのノード
A
次のようになります。
{ "data" : "A", "terminator" : false, "B" : { "data" : "B", "terminator" : true }, "D" : { "data" : "D", "terminator" : true } }
辞書は、文字列の配列として提示されます。 ツリーを構築するには、空のルートノードから開始し、辞書から単語を順番に選択し、それらを文字に分割し、必要に応じてノードを作成します。
var trieRoot; function buildTrie(wordList) { trieRoot = { "data" : "", "terminator" : false }; for ( var i = 0; i < wordList.length; ++i ) { var word = wordList[i]; var letters = word.split(""); var curNode = trieRoot; for ( var j = 0; j < letters.length; ++j ) { if ( curNode[letters[j]] == undefined ) { curNode[letters[j]] = { "data" : letters[j], "terminator" : false }; } curNode = curNode[letters[j]]; } curNode.terminator = true; } }
文字のセットから単語を作成するには、1からユーザーが指定したリストの文字数までのすべてのアレンジメントを生成する必要があります。 次の配置を構築するプロセスで、既に構築されたプレフィックスが辞書にない場合、配置のそれ以上の構築を停止できます。 配置は単純な再帰関数によって生成されますが、現在のプレフィックスの存在もチェックされます。
var letters = []; var used = []; var result = []; var words = {}; function findWords(node, depth) { if ( depth > 0 ) { result[depth - 1] = node.data; if ( node.terminator ) { var word = result.slice(0, depth).join(""); words[word] = 1; } } for ( var i = 0; i < letters.length; ++i ) { var child; if ( !used[i] && (child = node[letters[i]]) != undefined ) { used[i] = true; findWords(child, depth + 1); used[i] = false; } } }
letters
配列には、ユーザーが入力した文字のリストが含まれます。
used
配列には、現在の場所にある
letters
配列のインデックスに対応する文字を使用するためのフラグが格納
used
ます。 現在の位置は
result
に
words
保存され
words
-見つかった単語は、ユーザーが同じ文字の繰り返しを複数設定する場合( "AAABBBCCCDDD")に繰り返しを除外するために連想配列として使用されるオブジェクトに保存されます。
残りのコードはすべて入出力の処理専用であり、ツリー自体とはほとんど関係がありません。
なぜそれが必要ですか
私に関して言えば、私はプレフィックスツリーが何であるかを知っていて、その実用的な実装に遭遇したと正直に言うことができます。 一般に、実際にはそのようなツリーを使用して、たとえば、入力された最初の文字に関する情報を保存してすばやく検索することができます(検索候補など)、検索は非常に高速です、検索時間はプレフィックスの長さとアルファベットのサイズのみに依存し、メモリを犠牲にする場合は、取り除くことができますアルファベットのサイズに応じて。