まえがき
ご存知のように、オフラインモードで連続した手書きテキストを認識するタスクは、未解決と見なされます。
私はこの問題を理論的かつ実用的に解決することができました。 実用的な部分は、プログラムのデモ版のようになりました。 解決策は一般的なものであり、アプリケーション、言語、辞書のサイズのいずれの分野にも限定されません。
プログラムについて
プログラムは完全に訓練されています。 学習プロセスは簡単に見えます。 オンラインモードで文字を書くと、プログラムは文字を一般化し、書き込みアルゴリズムを強調表示します。 これはトレーニングの最初の段階です。 2番目の段階は、操作中に発生します。 一般的なスペルアルゴリズムが使用可能なシンボルのいずれかに一致するシンボルが見つかり、一部のプロパティの値が最初の段階で計算された範囲を超えると、範囲が拡大します。 もちろん、ユーザーが一般的な認識結果を確認した後にのみ。 ちなみに、最初の段階では、3〜7回のシンボルの表示で十分であり、アルゴリズムの準備ができています。
理論
理論について少し。 この問題を解決するには、いくつかのアプローチがあります。 通常、構造と参照の2つのタイプに分けられます。 1つ目は、シンボルのさまざまな構造要素とその記号、プロパティの選択と分析に基づいています。 2番目の方法では、認識可能な文字と一連の定義済みパターンを比較します。 これらの方法では、一般的な方法で問題を解決することはできません。
オンライン手書きタスクは完全に成功裏に解決されました。 このソリューションは、いずれにしても、ペンの軌跡を考慮した文字作成アルゴリズムの作成に基づいています。 つまり、座標を変更するシーケンス。 オフラインモードでの認識の問題をオンラインモードでの認識に減らすための提案がありました。 これを行うには、テキストのグラフィックコピーから行を正しく読み取るだけで十分です。 しかし、これを行うことは基本的に不可能です。 交差点間の線分は考慮できますが、それらを正しく接続するには解釈が必要です。
唯一の解決策があります-テキストのデジタルグラフィックコピーから読み取る段階で取得したセグメントを解釈するプロセスで文字を復元することです。 このためには、2つのコンポーネントが必要です。これを可能にするシンボルスペルアルゴリズムの特別な表現と、考えられるすべての解釈を分析できるセグメント解釈アルゴリズムです。
練習する
これを完全に行うことができました。 ご存知のように、デモ版の主なタスクは、タスクの基本的なソリューションを実証することです。 この意味で現在利用可能なプロトタイプは何ですか? このプログラムは、白い紙に任意の連続した手書き文字で書かれた1つの単語を認識することができます。 デジタルファイルへの翻訳では、単語をスキャンするか、Webカメラまたはデジタルカメラで撮影します。 原則として、テキスト認識はすでに行われていますが、この機能には改良が必要です。
以下は、認識可能な単語の例です。 ご覧のとおり、ここには通常のスペルだけでなく、「複雑な」オプションもあります。取り消し線、セグメントに書かれた文字、余分な部分などがあります。 これは、完全に完成した形式で、プログラムが非常にノイズの多いテキストを認識できることを示しています。
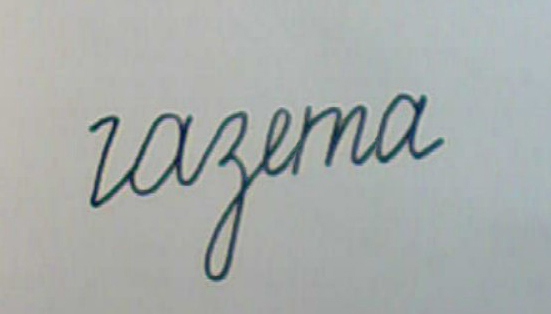
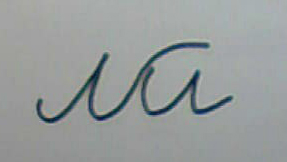
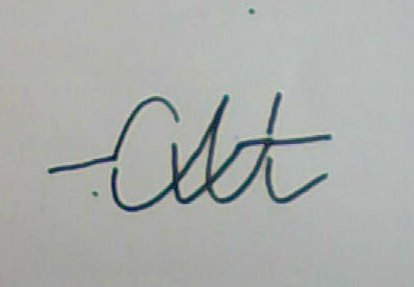

明らかに、ほぼその場所に必要なすべての部分を持っているシンボルのみが自信を持って認識できます。 欠けている部分やひどく歪んだ部分がある場合は、単語レベルでの解釈が必要です。 辞書があると認識率は上がりますが、すべての問題が解決するわけではありません。 フレーズの意味を理解しないと、一部の単語を明確に解釈できない場合があります。 これには、自然言語句の意味を理解できる人工知能システムが必要です。 最近まで、このようなシステムの市場での入手可能性に関する情報はありませんでした。 現在、ABBYYはComprenoシステムの作成を発表しました。このシステムは、特定の言語に依存しない「世界のモデル」に基づくフレーズの意味解釈を翻訳に使用します。
テキストの意味を理解できるプロトタイプのAIシステムもあります。 現在メディアに掲載されているComprenoに関する情報から判断すると、私のシステムは機能的にはるかに広いです。 彼女は訓練を受けており、情報を一般化し、タスクを完了するのに十分でない場合に積極的に知識を検索することができます。 言い換えれば、そのようなシステムは個人秘書として非常に機能します。 しかし、Comprenoに比べて重大な欠点が1つあります。一般的な準備という点では、まだデモ版には到達していません。
コマース
最後に、プロジェクトの商業面について少し説明します。 インターネットでは、 ABBYY Lingvo Aram Pakhchanyanの副社長とのインタビューがあります。 オフラインモードで連続した手書きテキストを認識するタスクに関しては、実際、この問題を解決する必要はないと述べています。 そのソリューションのコスト(おそらく非常に大きい)は報われません。 そして、主に継続的な執筆会社であるABBYY Lingvoがほとんど無関係になったためと思われます。 彼女は個別の手書きテキストを認識する問題を完全に解決し、あらゆる場合に適切なフォームを開発しました。
たぶんそれは冗談だった。 それでも、次のように言うのは理にかなっています。 通常の連続した手書きでの書き込みは、ボックスに文字を書くよりも便利で簡単です。 前者が後者よりも悪くないとコンピュータが認識する場合、後者はパンチカード、白黒テレビ、カメラ用フィルムなどの過去のものになります。
次の短いビデオでは、実行中のプログラムを見ることができます。 面白いかもしれません。
おわりに
そして別の重要なポイント-パフォーマンス指標、すなわち、時間と割合の認識。 もちろん、デモは2番目の基準に焦点を合わせました。 少なくとも70%のレベルに達しました。 完成版では、このインジケータは次のように定式化できます。人がテキストを読むことができる場合は、プログラムも同様です。 これまでのところ、認識時間については、許容値に到達できるとしか言えません。
すべてうまくいけば、テキスト認識の技術的側面やAIについての記事がさらに増えます。
ご清聴ありがとうございました。
____________
更新する
親愛なるhabravchane! フィードバックをありがとうございました。これは私たちにとって非常に重要で便利です。 一般に、トピックは積極的に満たされ、喜ばざるを得ません。
inしている人に言いたいのは、親愛なる、私たちは公正な魔術師ではないということです。 私たちは言葉で報告します。 最終製品で認識精度が100%になる傾向があると書いた場合、それは確信しています。
この記事はアナウンスと見なすことができますが、すべての技術的な詳細を詳細に明らかにするという目標はありませんでした。 しかし、示されている関心を考えると、しばらくすると、認識プロセスについてより詳細に説明する別の記事があります。
ダウンロード可能なデモ版もあります。