英語の音声を合成する最初の電子機械はニューヨークで1939年の展示会で発表され、voderと呼ばれましたが、それが再現した音は非常に曖昧でした。 音声認識の最初のデバイスは2年目に1952年に公開され、数字を認識することができました。
音声認識のプロセスでは、次の問題を区別できます。:意的で素朴なユーザー。 アグラマティズムとスピーチ「ゴミ」を伴う自発的なスピーチ。 音響ノイズと歪みの存在; 音声干渉の存在。
この記事のさまざまな方法のうち、隠れマルコフモデル(SMM)を使用して統計モデルを作成する可能性を検討します。
品詞タグ付け
自然言語を分析する場合、最初のステップは、次のことを決定することです。文の各単語がどの品詞を参照するか。 英語では、この段階でのタスクは品詞タグ付けと呼ばれます。 個々の文メンバーのスピーチの一部をどのように定義できますか? 英語の文を考えてみましょう:「缶は錆びます」。 したがって、これは明確な記事または「テーマ」の粒子です。 can-モーダル動詞、名詞、動詞の両方にすることができます。 will-モーダル動詞、名詞、動詞; 錆は名詞または動詞です。 統計的アプローチでは、各文法的意味で単語を使用する確率の表を作成する必要があります。 この問題は、手動で分析されたテストテキストに基づいて解決できます。 そして、すぐに問題の1つを特定できます。ほとんどの場合、「できる」という言葉は動詞として使用されますが、時には名詞にもなります。 この欠点を考慮して、形容詞または名詞が記事に従うという事実を考慮したモデルが作成されました。
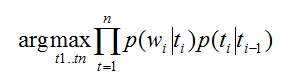
どこで:
t-タグ(名詞、形容詞など)
w-テキスト内の単語(錆、缶...)
p(w | t)は、単語wがタグtに対応する確率です。
p(t1 | t2)は、t1がt2の後になる確率です。
提案された式から、単語がタグと一致し、タグが前のタグと一致するようにタグを選択しようとしていることがわかります。 このメソッドを使用すると、「can」がモーダル動詞ではなく名詞として機能することを判別できます。
この統計モデルは、エルゴードSMMとして説明できます。

エルゴードマルコフモデル

実際のエルゴードマルコフモデル
この図の各頂点は、ペアが記述されている個別の品詞を示します(単語;単語がこの特定の品詞を参照する確率)。 トランジションは、スピーチの一部が別の部分に続く可能性を示します。 そのため、たとえば、記事が発生した場合に2つの記事が連続する確率は0.0016に等しくなります。 音声認識のこの段階は非常に重要です。なぜなら、文の文法構造の正しい定義により、再現された文の表現的な色付けに適切な文法構造を選択できるからです。
N-gramモデル
n-gram音声認識モデルもあります。 これらは、文の次の単語を使用する確率がn-1単語のみに依存するという仮定に基づいています。 今日、最も人気のあるバイグラムおよびトライグラム言語モデル。 このようなモデルの検索は、大きなテーブル(ケース)で行われます。 アルゴリズムは高速で実行されますが、依存する単語が5単語離れている場合、このようなモデルは意味的および構文的な関係をキャッチできません。 nが5より大きいn-gramモデルの使用には、非常に大きな力が必要です。
上記のように、今日最も人気のあるモデルはトライグラムモデルです。 文w1、... wnを観察する条件付き確率は、次の値に近くなります。
P(w1、...、wn)=ΠP(wi | w1、...、w2)≈ΠP(wi | wi-(n-1)、...、wi-1)
たとえば、「家に帰りたい」という文を考えてみましょう。 この提案の確率は、n-gramの頻度のカウントから計算できます(この例では、n = 3を取ります)。
P(I、want、to、go、home)≈P(I)* P(want | I)* P(to | I、want)* P(go | want、to)* P(home | to、go )
分析は、前の2つの単語だけでなく、近くにある任意の単語のペアによって実行される長距離トライグラムモデルであることは注目に値します。 このようなトライグラムモデルは、情報価値のない単語をスキップできるため、モデルの互換性の予測可能性が向上します。