分類
ウィキペディアによると、分類は情報検索のタスクの1つであり、ドキュメントの内容に基づいてドキュメントをいくつかのカテゴリの1つに割り当てることで構成されます。
これが私たちがやることです。
文書の分類は情報検索や盗作の検索などで長い間使用されているため、これが必要な理由を説明する必要はないと思います。
収集
分類器をトレーニングするには(分類器がトレーニング可能な場合)、ドキュメントのコレクションが必要です。 ただし、テストに関しては。
これを行うために、テキストのさまざまなテストコレクションがあります。これらは基本的にインターネットで簡単に見つけることができます。 RCV1コレクション(Reuters Corpus Volume 1)を使用しました。 このロイターのコレクションは、1996年8月から1997年8月までのニュースを手動でソートしました。 このコレクションには、英語で約810,000のニュース記事が含まれています。 情報検索とテキスト処理の分野で、さまざまな研究に常に使用されています。
このコレクションには、階層的なカテゴリが含まれます(1つのドキュメントが、たとえば経済と石油などの異なるカテゴリに同時に属することができます)。 各カテゴリには独自のコードがあり、これらのコードはすでにニュースに帰属しています(合計で約80のカテゴリ)。 たとえば、CCAT(企業/産業)、ECAT(経済)、GCAT(政府/社会)、およびMCAT(市場)の4つのカテゴリが階層の先頭にあります。
カテゴリの完全なリストはこちらにあります。
次に、いくつかの重要なポイントを扱います。 まず、分類子をトレーニングするには、テキストにスタンプを押してストップワードを捨てることもよいでしょう。
- ステミング。 私たちを分類するとき、「油」という言葉がどのように書かれているかは関係ありません(「油」、「油」、「油」、「油」)。 単語を1つの形式にすることをステミングと呼びます。 ポーターアルゴリズムのこの実装など、英語のテキストをスタンプするための既製のソリューションがあります 。 このライブラリは、 インディアナ大学の javaで書かれており、無料で配布されています。 私はロシア語で検索しませんでした、多分何かもあります。
- ストップワード。 ここではすべてが明確です。 「and」、「but」、「by」、「from」、「under」などの単語は、どこにでもあるため分類に影響しません。 実際には、彼らは通常、コレクションの中で最も人気のある単語をいくつか取り、それらを捨てます(数字も捨てることができます)。 ここからリストを取得できます。
このような処理は、タスクの次元を縮小し、生産性を向上させるためのすでに確立された方法です。
サポートベクター法
ここで、テキストドキュメントから抽象化し、既存の分類アルゴリズムの1つを検討します。
ここでは詳細や数学的計算をロードしません。 興味深い場合は、 WikipediaやHabrなどで見つけることができます。
簡単に説明します。
n次元空間に多くのポイントがあり、各ポイントが2つのクラスのうちの1つだけに属しているとします。 次元n-1の超平面によってそれらを何らかの方法で2つのセットに分割できる場合、これはすぐに問題を解決します。 これは常に起こるとは限りませんが、セットが線形に分離できる場合、幸運です。
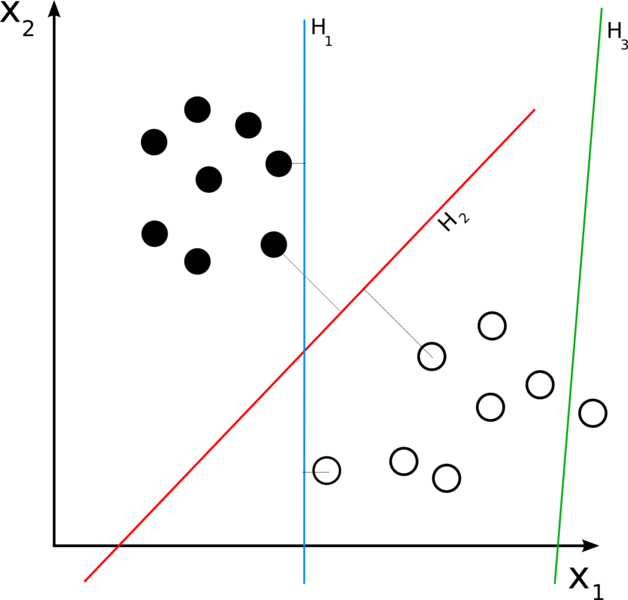
分類器は、分割する超平面からセットの最も近い点までの距離が大きいほど、うまく機能します。 すべての可能なものからまさにそのような超平面を見つける必要があります。 最適分割超平面と呼ばれます:

検索には、単純なアイデアが使用されます。2つの平行な超平面を構築し、その間にセットのポイントはありません。また、それらの間の距離を最大化します。 平行超平面に最も近いポイントはサポートメソッドと呼ばれ、メソッドに名前を付けました。
しかし、セットが線形分離可能でない場合はどうでしょうか? さらに、おそらくこれはそうです。 この場合、超平面の間にポイントが表示されるように、分類器がセットを分割することを許可します(したがって、最小化しようとしている分類器のエラー)。 このような超平面を見つけたので、分類は技術の問題になります。ベクトルが判明した超平面のどちらの側を調べる必要があり、そのクラスを決定する必要があります。
すぐに使える
もちろん、自分でアルゴリズムを実装できます。 しかし、優れた既製のソリューションがある場合、これは多くの時間の無駄につながる可能性があり、実装がより良いまたは少なくとも同じになるという事実ではありません。
SVM lightと呼ばれるサポートベクターマシンの優れた実装があります。 ドルトムント工科大学で作成され、無料で配布されています(研究目的のみ)。 実装オプションはいくつかあります(たとえば、リレーショナルデータベースから学習できるもの)が、テキストファイルで機能する最も単純なものを使用できます。 このような分類子は、2つの実行可能ファイル(トレーニングモジュールと分類モジュール)で構成されています。
トレーニング
トレーニングモジュールは、トレーニングデータが入力されたテキストファイルを受け取ります。 ファイルには、2つのクラスのどちらに属するかに応じて、+ 1または-1というラベルの付いたベクトルが含まれている必要があります。
次のようになります。
-1 0 0 0 0 0 0 6 0 0 0 6.56 0 0 0 0 0 0 0 45.56 0 0 0 0 0 0.5 0 0 0 0 0 0 0
モジュールはそのような記録も理解します:
-1 7:6 11:6.56 19:45.56 25:0.5(つまり、インデックス付きの非ゼロ値のみをリストできます)。
分類
2番目のモジュールは、入力として分類されるデータを含むテキストファイルを受け取ります。 形式はトレーニングの場合と同じです。 分類後、res.txtが作成され、結果が記録されます。
文書分類のためのsvm
次に、svmをドキュメント分類に適用する方法を見てみましょう。 どこからベクターを入手できますか? 合計で80があり、svmが2つのクラスのいずれかに属しているかどうかしか判断できない場合、ドキュメントがどのカテゴリに属しているかを判断する方法は?
ドキュメントはベクトルです
文書をベクトルとして提示することは難しくありません。 最初に、コレクション辞書を作成する必要があります-これは、このコレクションに表示されるすべての単語のリストです(RCV1コレクションの場合、47,000単語です)。 単語の数はベクトルの次元になります。 その後、ドキュメントはベクトル形式で表示されます。i番目の要素は、ドキュメント内の辞書のi番目の単語の出現の尺度です。 単語がドキュメントに含まれるかどうか、または出現回数に応じて、+ 1または-1になります。 または、ドキュメント内の単語の「共有」。 多くのオプションがあります。 その結果、ほとんどの要素がゼロである大きな次元のベクトルが取得されます。
80カテゴリ-80分類子
80個のカテゴリがある場合、分類器を80回実行する必要があります。 より正確には、ドキュメントがこのカテゴリに該当するかどうかを判断できるように、各カテゴリに80の分類子が必要です。
テスト。 指標
分類子をテストするには、分類子の結果を手動の結果と比較することにより、同じコレクションの一部を使用できます(トレーニング時にこの部分を使用しないでください)。
分類子の作業を評価するには、いくつかのメトリックが使用されます。
- 精度=((r-kr)+ kw)/ n
実際、これは正確です。
- 精度= kr / n
- リコール= kr / r
ここで、 kwは、分類器が目的のカテゴリに属さないと誤ってマークしたドキュメントの数です。
kr-分類器が目的のカテゴリに関連するものとして正しく記録したドキュメントの数。
r-分類子に応じた、目的のカテゴリに関連するドキュメントの総数。
nは、目的のカテゴリに関連するドキュメントの総数です。
これらのメトリックの中で、 PrecisionとRecallは最も重要です。これらは、ドキュメントにカテゴリを割り当てる際にどれだけ間違えたか、および分類器がランダムにどの程度機能するかを示すためです。 両方のメトリックが1つに近いほど、優れています。
そして小さな例。 ベクトルをコンパイルし、ドキュメント内の単語の尺度としてその「シェア」(ドキュメント内の単語の出現数をドキュメント内の単語の総数で割ったもの)を取り、32000ドキュメントおよび3000の分類で分類子を訓練すると、次の結果が得られました:
精度= 0.95
リコール= 0.75
良い結果が得られ、分類器を使用して新しいデータを処理できます。
参照資料
RCV1について:
RCV1について
ここでコレクションを見つけることができます。
SVMについて:
ウィキペディア
素晴らしい記事