ウイルスは、次の2つの条件が満たされているコンピューターでほぼ必然的に発生します。
1)ハードウェアレベルの実行可能コードは、実行可能コードの領域への書き込みを禁止されていません。
2)コンピューターには、システムの入出力インターフェースを独立して制御する多くのホストがあります。
コンピューターを任意のコンピューティングシステムと呼びます。 インターネットは、これらの条件が両方とも当てはまるまさにそのようなシステムであることをすでに示しました。 それらは、インターネットサブシステムの大部分、つまり それに接続されたシステムユニット-家庭用スマートフォンやラップトップから企業サーバーまで。 名義の所有者は、ネットワークに接続した瞬間から独占的に制御する能力を失い、実行可能なコードに影響を与える可能性のある何百万人もの見知らぬ人とこの特権を共有しています。

ウイルス耐性に関するコンピューターの信頼性の評価。
残念ながら、インターネット全体とインターネットに接続された一般的なコンピューターの両方が、ウイルス対策の信頼性テーブル(赤でマーク)の最後の場所を占めています。
人々がエラーなしでプログラムを書くことができれば、状況はまったく異なります。 しかし、地球上にはそのような技術はまだありません-少なくとも商用プログラムについては。 ソフトウェアのエラーを避けられない複雑な技術的および社会的理由については別の機会に説明しますが、ここでは、プログラムにエラーが含まれない世界を説明する表を見てみましょう。
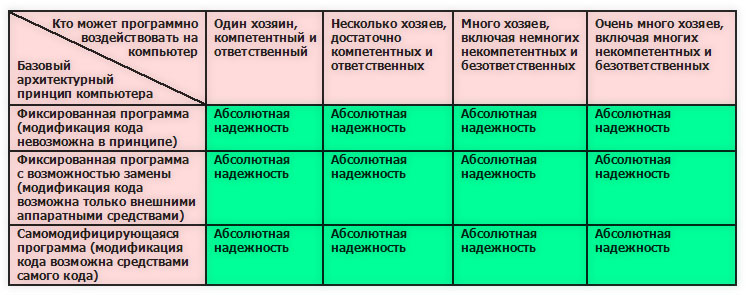
開発レベルでウイルス耐性が組み込まれているという前提で、すべてのソフトウェアにエラーが完全に存在しないという架空のケースについて、ウイルス耐性に関するコンピュータの信頼性を評価します。
すべてのオペレーティングシステム、ブラウザ、Webサーバー、およびその他のプログラムが完全に記述され、セキュリティ要件を考慮すると、任意の大規模なフォンノイマン環境が存在する可能性があり、ウイルスに感染しません。 理想的なソフトウェアでは、要素間のすべての接続は非常に慎重に考えられているため、相互作用の任意の組み合わせにより、名目上の所有者以外によるコードの変更の不可能性が数学的に保証されます。 情報セキュリティの専門家なら誰でも、大規模システムとの関係ではユートピアであることを理解しています。
それでも、コードの一部の要素が他の要素に影響を与える可能性を排除するための注意深いプログラミングは、実際に使用されているウイルス対策方法の1つです。 そして、特にコードがコンパクトな場合、良い結果をもたらします。 しかし-完璧ではありません。 多くの場合、「認証されたUNIXシステムは無敵です」などの声を聞くことができます。 それは真実に近いが、真実ではない。 このようなステートメントは数学的に正しくありません。 それらは議論の余地がなく、厳密な証明は実際には不可能です。 大量のコードの問題がないことの正式な証明は 、特にこのコードとさまざまなハードウェアとの相互作用を考慮すると、時間がかかり、非常に高価です。 コードの不変性に対する絶対的な信頼は、適切な媒体での変更に対する物理的保護(読み取り専用)によってのみ提供されます。 ちなみに、この記憶媒体はRAMである場合もあります-コード自体で変更することが不可能な場合(たとえば、外部手段によってメモリに配置され、最初の実行ビートまでこのメモリへの書き込みをブロックする場合)。
産業用オペレーティングシステムでの重要なコードの保護の有能な実装は、物理的な読み取り専用実装に近い信頼性を提供する場合があります。 しかし、多くの技術的および経済的な理由から、そのようなシステムは常に使用できるとは限りません。 情報セキュリティの専門家の仕事では、通信事業者のアセンブリの設計からタービンを制御するPLCのプログラミングまで、まったく異なる種類のタスクが発生する可能性があります。 責任あるデータベースの開発から、任意の企業システムの監査と片付けまで。 たとえば、そのようなシステムがWindowsおよび「1C:Enterprise」という複雑な製品に基づいている場合、「UNIXの脆弱性」へのすべての参照は役に立ちません。 実際には、脆弱性について判断するのが困難なクローズドプロプライエタリソフトウェアと、コマンドシステムが確実に未知であるチップに対処する必要があります。 情報技術の分野では、ほとんどすべてのプロジェクトの初期条件が異なります。 したがって、プロジェクトの有能な管理のために、専門家は一般的なコンピューターサイエンスとサイバネティックスに普遍的な技術を所有している必要があります。 それらの1つは、プログラムの修正(変更に対するハードウェア保護)です。
多くの場合、プログラムの修正はハードウェア保護をエミュレートすることにより提供されます。 エミュレーションはさまざまなレベルのアーキテクチャで実行できますが、多かれ少なかれ完全になりますが、最も重要なことは、ソフトウェアによって制御されるべきではありません。 その助けによって保護されているまさにそのコードから。 ソフトウェアで制御された保護のエミュレーション(たとえば、メモリの特定の領域への書き込みやそれらのアクセスから)は、最終的にコードを変更する機能がコード自体によって決定されるため、コンピューターの自動プログラミングプロパティを奪うことはありません。
プロセッサとチップセットの個々の存在-ソフトウェア制御! -メモリの特定の領域の「ハードウェア」保護のメカニズムは、問題を完全には解決しません。 たとえば、x86プロセッサは、保護モード、システム管理、ハードウェア仮想化モードをプログラムで制御します。 しかし、コンピューターにそのようなプロセッサーを装備しても、ウイルスに感染しないという意味ではありません。「ハードウェア」保護の適切な管理の全責任は、ソフトウェア( BIOS 、OS、および他のシステムレベルのソフトウェア)にあります。 このようなコンピューターでのコードの整合性は、プログラムの方法のみに依存します。 つまり、2つの異なるオペレーティングシステム(および同じオペレーティングシステムの2つの異なる設定でも)が同じハードウェアでコード保護のレベルが異なる場合、これは保護がハードウェアに実装されていない典型的な自動プログラムシステムがあることを意味します。しかし、プログラムで。
自動プログラマビリティのプロパティを持たないシステムでは、コンテンツに関係なくプログラムの不変性が保証されます。 プログラムを他のレベルの保護に置き換える場合、システムの設計によって保証されているため、プログラムは変更されず絶対的なままです。
ところで、記事の最初の部分に関する読者のコメントに関連して、少なくとも1つのビットがその中の任意のプログラムで置き換えられているという事実に注目します。 正式な観点からは、2つの任意のプログラムが異なると見なすには1ビットの差で十分です。 「プログラム置換」という用語は、コード全体を最初から最後まで機能の根本的な変更に置き換えることを必ずしも意味しません:)
変更に対するソフトウェアとハードウェアの両方のコード保護には、それぞれ長所と短所があります。 情報セキュリティの多くの実際的な問題を解決するには、ハードウェア保護の利点が決定的です。 主なものは、低コスト、数学的に信頼できる信頼性、直感的な証拠です。 ハードウェア保護は、コードの完全性の証明を必要とせず、エラーが発生した場合でも、適切な時間に保証された不変性を保証します。 ただし、この保護方法を適用するには、プログラムとデータの分離(固定メモリ領域外へのデータ転送)を確保する必要があり、場合によっては重大な欠点になります。
ウイルスに対する保護に加えて、プログラム(コード、アルゴリズム、情報オブジェクト全般)を修正することにより、将来のリリースで説明する情報セキュリティの他のタスクを解決できます。 その間、コンピューティングシステムの物理的および論理的構造のさまざまなレベルでオブジェクトを修正する例をいくつか示します。 不変および強制不能のフラグが各オブジェクトに示されます。 保護されたオブジェクトの外部の手段によってインストールされることを強調します。 特定のタスクと機能に応じて、フラグをハードウェア、ソフトウェア、または条件付きで実装できます(たとえば、フラグ違反イベントを監視する代わりに、操作の直接禁止がないことを意味します)。 これらの例は、行動への直接的なガイドとして受け取られるべきではありません。これらは、ウイルス保護の一般原則と、この目的で固定プログラムを使用するいくつかの特別な事例の単なる例です。
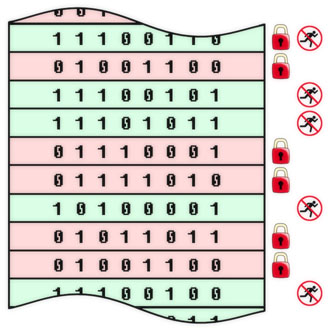
個々のバイトのレベルでのウイルス対策保護。 ROMのプログラムとRAMのデータを備えた従来のマイクロコントローラ回路に対応していますが、他の方法(共有メモリの追加ビットにフラグを設定するなど)で実装することもできます。

論理モジュールのレベルでのウイルス対策保護。 それは、プログラムとデータの分離の重要な原理をよく示しています-その実装の特定のメカニズムに関係なく。
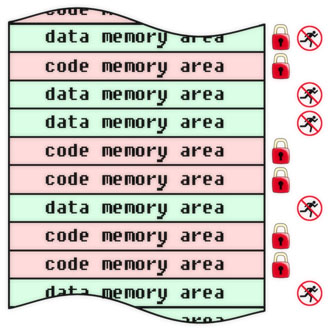
メモリ領域のレベルでのウイルス対策保護。 物理メモリデバイスは重要ではありません。ランダムアクセスメモリ、フラッシュメモリ、ディスクメモリ(ストレージ)、およびその他のものです。
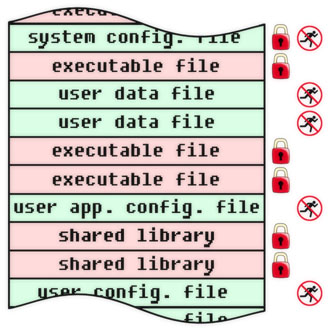
ファイルレベルのウイルス対策保護。 このレベルは非常に視覚的で、制御するのに便利です。
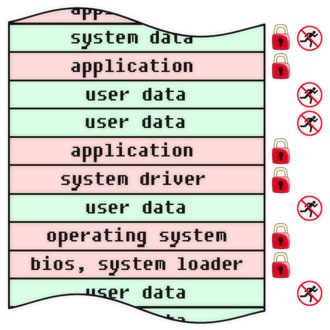
機能的に完全なソフトウェアのオブジェクトのレベルでのウイルス対策保護。 このレベルでの制御は、組織のコンピューターインフラストラクチャの長期的な信頼性の鍵です。
ヒューリスティック分析(情報オブジェクトの性質と動作の分析)の原理に基づくウイルス対策プログラムは、コンピューターのさまざまなレベルで情報オブジェクトを監視し、特定のルールに従ってそれらの一部を修正するシステムの特殊なケースであることに注意してください。 これは、情報セキュリティスペシャリストの武器として有用なツールですが、決して唯一のものではありません。
まとめると。 危機を解決する3つの方法があります。これは、ブログの最初の号で (部分的に-eg話的に)説明しました。 最も明白で、信頼性が高く、有益な方法は、コンピューティングシステムの自動プログラミングのレベルを下げることです。 非常に小さな組織や個人ユーザーにとっても困難ですが、それでも現実的です。 ウイルスの脅威だけでなく、今後数年間にわたってプログラムとデータが新しい所有者の手に徐々に移されるという脅威からも保護できます。
2番目の非常に危険な方法は、ホストの数を減らすことです。 プログラムとデータの大部分が、すべての重要な問題に関する意思決定者の小さなサークルの手に集中するまで。 残念ながら、これは最初のパスに代わる唯一の本当の選択肢です。
3番目の方法は、ソフトウェアをエラーなしで作成するための商業的に有効な技術を開発することです。 この技術の現実は非常に疑わしいです。
読者が危機を解決する他の方法を見たり、出来事を危機と見なさない場合、私たちは彼らの意見を知ってうれしいです。 ディスカッションにご招待します。
* * *
次号を読む:
コンピューターウイルスとは