
テクニカルサポートからの応答がない13:30からサーバーがあります。
clodo.ruの皆さん、どこにいますか? チケットレター/メッセージ/などはどこにありますか?


6月15日更新。 補償。
今日、1人のhabrユーザーが補償を受け取る彼の試みについて非常に興味深いメッセージを送りました:
11:55:22 06/14/2011私が書く:
こんにちは
4日間、VPS 11111-1は機能しません。
問題は何ですか? サーバーはいつ動作しますか?!
11:56:55 2011年6月14日サポートサービス(Alexandra M * shuk ***)の書き込み:
サーバーはすでに4日間「要求処理」状態になっていますか?
12:01:42 06/14/2011サポートサービス(Alexandra M * shuk ***)の書き込み:
今すぐ確認してください。 sshが利用可能であることにより、動作します。
14:23:25 06/14/2011私は書きます:
現在利用可能です。 何が問題でしたか?
14:27:27 06/14/2011サポートサービス(Alexandra M * shuk ***)の書き込み:
問題は私たちの側にありました。 ご不便をおかけして申し訳ございません。
それから私は補償について学びました:
こんにちは。
5月23日に修正された公募契約によれば、補償はClodoとのフォールトトレラントサービス契約の締結時にのみ支払われます。 残念ながら、私たちはあなたに補償を支払うことを拒否せざるを得ません。 私たちはこの事件について大変申し訳ありません。 将来、このようなことは二度と起こらないように、すべてを行いました。 2つのデータセンターに展開された高可用性ソリューションに関心がある場合は、1か月以内に提供できます。
クラウディア、クラウディア、あなたはすべてあなたのレパートリーにいます、私たちは何も負いません、私たちはすべてのために言い訳をします...契約で。 従業員は、あなた自身がそのような会社で働くことを恥じていないことを認めましたか?
更新6月14日:4日が経過しました。
事故の説明06/10/2011
ご存じのように、Clodoはクラスター管理構造の変更に取り組んでいます。 すべての悲しい経験を考えると、私たちは彼らを夜に導き、それらを原子の非破壊的行動に分解します。
インシデントの前夜、エンジニアはInfiniBandスイッチの1つをクラスターから除外するよう努めました。 一方で、このアクションは予備テストの対象となり、他方では、一度完了すると、何も違反されていないことが再度確認されました。 その後、作業は行われませんでした。
しかし、非常に長い時間の後、仮想マシンの崩壊が始まりました。 この問題は、XENノード、クラスターコントローラー、およびリレーにインストールされたSuse Linux Enterprise ServerでのIP over Infinibandドライバー(IPoIB)の障害が原因で発生しました。 残念ながら、障害は非常に致命的であり、仮想マシンは自動ではなく手動で上昇しました。 さらに、緊急の起動スクリプトを作成する必要があったため、仮想マシンの台頭は私たちが望むほど速くは起こりませんでした。 障害の結果、仮想マシンのごく一部(10〜15)が仮想マシンとディスク間の接続を失いました。 これらのマシンのパフォーマンスをより長く回復する必要がありました。
障害が原因で障害が発生しました。 その主なコンポーネント:
操作前の不十分なテスト(遅延エラーは除外されませんでした);
Suse Linux Enterprise ServerとInfiniband間の相互作用が不完全にテストされています。
事故の場合の不完全な起動スクリプト。
これらのエラーはすべて、人的要因の結果です。 加害者は、本番サーバーでのアクションを禁止されています。
小さいFAQ
サポートチームの応答が非常に遅いのはなぜですか?
答えは簡単です。事故時には、テクニカルサポートサービスの負荷が何度も増加します。 サポートサービスは事故の撲滅につながりました。被害者のリストをまとめ、トラブルシューティング後の起動を監視し、あらゆる面でシステム管理者を支援しました。
事故の際に、彼らはフォーラム/ハブラハブル/ツイッターで私と連絡を取らず、何が起こっているのかを言わなかった理由
何が起こっているかを正確に理解して説明することができたすべての人々は、結果を排除することに従事していました。 問題を解決する人々に時間を費やすことは非常に非現実的でした。
このようなことが再び起こりますか?
現時点では、すべての作業が中断されています。 行われている唯一のことは、作業中に無効にされた機能の復元です。 作業の準備のための新しい手順が承認されました。これには、ノードに対する計画的な変更後にシステム全体の正常性をテストすることが含まれます。
自分のために、あなたが私の受信箱に送ったメッセージに答えなかった人に謝罪したい。 このような手紙の流れを物理的に処理する時間はありません。
ClodoのCEO、
マキシム・デュバレフ
私は自分自身のために言いたいのですが、マキシムは本当にこれは価値のある説明だと思います...私が話していること、あなたのやり方は説明されていますが。 彼ら自身が悪化しただけです。
更新19:45:残りの2台のサーバーが異なるアカウントで実行されています。
更新19:15:物語は続きます。 私はすでにメインプロジェクトとして引っ越しましたが、コメントから判断すると、まだ問題があります。 現時点では、Claudeフォーラムは次のようになっています。
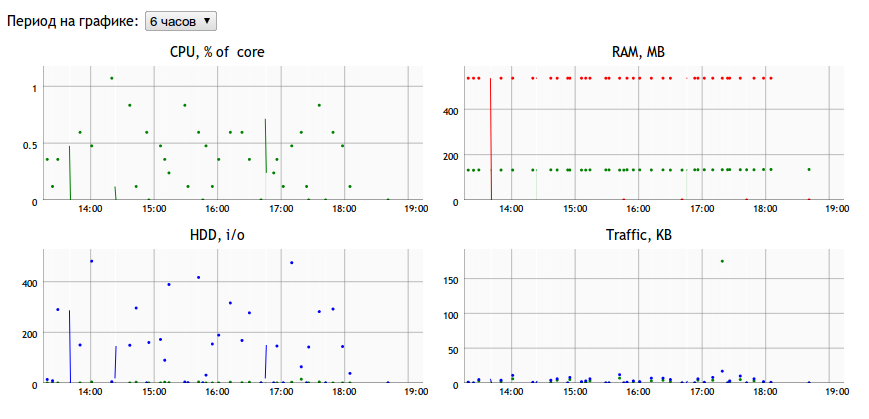
また、過去6時間にわたる私のサーバーの1つの作業スケジュールは次のとおりです。
あなたは去って、さよならさえ言わない?
更新07:10:18時間以上。 すべてのサーバーが上昇しています。 移動する時が来ました! どうやらクロドの従業員はすでに仕事に来て、よく眠り、サーバーの電源を入れました:)
更新04:30:15時間以上。 それから、秋に責任がある姓を見たいです。 午前5時に、サーバーが上がるまで待って、最新の最新のバックアップを取得します。 しかし、クロードの従業員が長い間家で寝てしまったことを教えてくれます...
更新02:00:13時間横たわっています。 親愛なるクロードの従業員、それは顧客にとってちょっと面白くて無礼です! この秋の後、あなたのすべてまたはほとんどが去ることを望みます。 すべてのサーバーでのすべてのダウンタイムに対して、ホスティング費用全体よりも多くのお金が失われます! さらに、1つのプロジェクトの評判は今では金銭的には回復できませんが、損なわれ、私はあなたのすべてのドロップに対してユーザーにできる限りの補償とボーナスを与えました。 今何をすべきか想像できません。
このアップタイムにより、クラウドサービスの費用はかかりません 。 あなたが嫌いだと言うことは、何も言わないことです。 あなたの質と態度に再びありがとう。
更新23:00:10時間横たわっています。 いいえ、まあ、これはすでに紳士です。 すべてがフォールトトレラントなので、10時間上げることはできません。
