GPUが助けになりますか?
Intelが昨年、プロセッサにグラフィックコアを追加したとき、承認された理解で受け取られましたが、彼らが言うように、ファンファーレはありませんでした。 最後に、その前にメモリコントローラーがCPUに移動した場合、ノースブリッジの残りの機能もそこに転送してみませんか? そして、統合されたグラフィックスは、Intel AtomからモバイルCore i7まで、どこにでも存在し始めました。 誰が望んでいた-それを使用し、誰が望んでいなかった-個別のアクセラレータを備えたコンピューターを選択した 一般に、概して、何も変わっていません。 そして、グラフィックコンポーネントがビデオをデコードする際にCPUをゆっくりと助けたという事実は、普通のことです。私たちはそれに慣れています。
一方、ビジネスの同僚はこのアイデアを好み、まもなくグラフィックコアもプロセッサに定着します。 ただし、これに限定されるものではありません。タスクの最大範囲で後者を使用する計画であり、チップの正式名称でさえCPUからAPUに変更されます。 一般に、AMDによると、x86コアの数を無制限に増やすことはできません。これは、「ボトルネック」が現れ始め、コアの乗算効率が低下するためです。 そしてGPU-それは非常に近いかのようですが、その非類似性のために、通常のコアに干渉せず、それが過負荷になる場合は...
一般的に、このスライドをご覧ください。
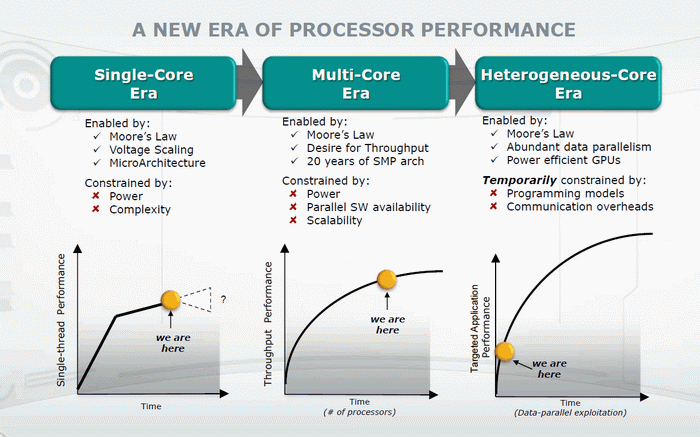
彼によると、いわゆるマルチコアプロセッサがかかとを踏んでいます。 「異種核」。これはムーアの法則に厳密に従っています。 後者には多くの利点がありますが、欠点も非常に深刻です。 おそらく最も不快な-ハイブリッドプロセッサは、馴染みのあるプログラミングモデルにはまだあまり適合していません。 そして、疲れたプログラマーに、それがどれほど難しいかを切り替えさせます。 それにもかかわらず、開発者を支援するための努力と資金がすでに投資されており、マーケティング装置がオンにされており、作業が進行中です。
現時点では、指先に魔法の水晶玉はありません。その中を見て、Intelの広範囲にわたる計画について調べることができます。 ただし、ロジックをオンにして将来のSandy Bridgeプロセッサのアーキテクチャを見ると、プロセッサのグラフィックコンポーネントが消えることはほとんどないと想定できるため、モデルからモデルへと高速化されます。 実際、今日の進歩はすでに明らかです-Sandy Bridgeでは、ターボブーストテクノロジーが統合グラフィックスソリューションに浸透し、その結果、標準の650〜850メガヘルツの周波数が負荷がかかった状態で最大1350まで増加する可能性があります。 そうだとすれば、グラフィックパワーを使用してあらゆる種類の計算を高速化することは論理的です。
グラフィックチップが今日どのように「役立つ」かについては、すでに何度も書いています。 そこでは、すべてがスムーズであるとは限りません(たとえば、ビデオ変換におけるGPUの有効性に関するこの投稿をISNで見ることができます)。 しかし、明日統合されたGPUは、あまり一般的ではないタスクではあまりスマートではないが、速度を落とすことなく精度を学習すると仮定しましょう。 そして、問題が発生します。私たちは、マルチコアプロセッサを使用する場合よりも、共通の原因をめぐる闘争に参加することで自分自身を苦しめているのではないでしょうか。
実際、コンピューター上では何も起こらず、ソフトウェア開発者の骨の折れる努力なしにはプレゼンテーションにこのような美しいテクノロジーを導入することは不可能です。 今日はどうですか? コンピューティングでのGPUの成功した使用例は個人的に好きですか? 開発者は、工業規模でCPUとGPUの友情を促進したいですか? このバンドルは実際にどれほど効果的ですか? 効果的な場合、新しいプログラミングスタイルに再学習するのにどれくらいの時間がかかりますか? そして、特定の標準的なアプローチについて話をしますか、それとも各専門家が彼自身の方法を探します(そして見つけます)?
答えよりも多くの質問がありますが、これは驚くことではありません。CPUとGPUはお互いを見ているだけで、クリスタルネイバーの違いからどのような利益が得られるのか疑問に思っています。 しかし、あなたはすでにこの同盟について考えたことがあり、あなたはあなたの予測をすることができますか?
一方、ビジネスの同僚はこのアイデアを好み、まもなくグラフィックコアもプロセッサに定着します。 ただし、これに限定されるものではありません。タスクの最大範囲で後者を使用する計画であり、チップの正式名称でさえCPUからAPUに変更されます。 一般に、AMDによると、x86コアの数を無制限に増やすことはできません。これは、「ボトルネック」が現れ始め、コアの乗算効率が低下するためです。 そしてGPU-それは非常に近いかのようですが、その非類似性のために、通常のコアに干渉せず、それが過負荷になる場合は...
一般的に、このスライドをご覧ください。
彼によると、いわゆるマルチコアプロセッサがかかとを踏んでいます。 「異種核」。これはムーアの法則に厳密に従っています。 後者には多くの利点がありますが、欠点も非常に深刻です。 おそらく最も不快な-ハイブリッドプロセッサは、馴染みのあるプログラミングモデルにはまだあまり適合していません。 そして、疲れたプログラマーに、それがどれほど難しいかを切り替えさせます。 それにもかかわらず、開発者を支援するための努力と資金がすでに投資されており、マーケティング装置がオンにされており、作業が進行中です。
現時点では、指先に魔法の水晶玉はありません。その中を見て、Intelの広範囲にわたる計画について調べることができます。 ただし、ロジックをオンにして将来のSandy Bridgeプロセッサのアーキテクチャを見ると、プロセッサのグラフィックコンポーネントが消えることはほとんどないと想定できるため、モデルからモデルへと高速化されます。 実際、今日の進歩はすでに明らかです-Sandy Bridgeでは、ターボブーストテクノロジーが統合グラフィックスソリューションに浸透し、その結果、標準の650〜850メガヘルツの周波数が負荷がかかった状態で最大1350まで増加する可能性があります。 そうだとすれば、グラフィックパワーを使用してあらゆる種類の計算を高速化することは論理的です。
グラフィックチップが今日どのように「役立つ」かについては、すでに何度も書いています。 そこでは、すべてがスムーズであるとは限りません(たとえば、ビデオ変換におけるGPUの有効性に関するこの投稿をISNで見ることができます)。 しかし、明日統合されたGPUは、あまり一般的ではないタスクではあまりスマートではないが、速度を落とすことなく精度を学習すると仮定しましょう。 そして、問題が発生します。私たちは、マルチコアプロセッサを使用する場合よりも、共通の原因をめぐる闘争に参加することで自分自身を苦しめているのではないでしょうか。
実際、コンピューター上では何も起こらず、ソフトウェア開発者の骨の折れる努力なしにはプレゼンテーションにこのような美しいテクノロジーを導入することは不可能です。 今日はどうですか? コンピューティングでのGPUの成功した使用例は個人的に好きですか? 開発者は、工業規模でCPUとGPUの友情を促進したいですか? このバンドルは実際にどれほど効果的ですか? 効果的な場合、新しいプログラミングスタイルに再学習するのにどれくらいの時間がかかりますか? そして、特定の標準的なアプローチについて話をしますか、それとも各専門家が彼自身の方法を探します(そして見つけます)?
答えよりも多くの質問がありますが、これは驚くことではありません。CPUとGPUはお互いを見ているだけで、クリスタルネイバーの違いからどのような利益が得られるのか疑問に思っています。 しかし、あなたはすでにこの同盟について考えたことがあり、あなたはあなたの予測をすることができますか?
All Articles