「タンブラー」、またはコールセンターの動作がその作業の可能な中断を除外する方法
ヘルプデスク(コールセンター)の作業には、1日24時間、週7日、1年365日、つまり24時間連続してコールを処理することが含まれます。 この要件は、商用サービスを提供するコールセンターにとって非常に望ましいものです。 ただし、この条件が必須のコールセンターがいくつかあります。 このようなコールセンターは、「09」サービスまたは緊急対応サービス「01」〜「04」および「112」です。 システムの高い信頼性と信頼性に関するコールセンタープラットフォームのサプライヤの保証にもかかわらず、ハードウェアとソフトウェアの複合体に障害が発生する状況が依然として存在します。 また、コールセンターへの着信コールの処理が不可能になります。 この低下がソフトウェアの問題によるものか、ハードウェアの問題によるものかは、もはや重要ではありません。サービス呼び出しの中断は、それ自体ですでに重要です。
すべてのコールセンタープラットフォームが完全な「ホット」冗長性の可能性を想定しているわけではありませんが、完全な「ホット」予約を含む多くのプラットフォームでは、2番目のコールセンターの購入に匹敵します。
そのため、コールセンターアーキテクチャが「ホット」な冗長性の作成または冗長性スキームの編成コストの最適化を許可していない場合でも、コールセンターの容量を予約できるようにする方法。 すぐに予約しますが、このソリューションは主に大規模なコールセンターに焦点を当てていますが、場合によっては少数のオペレーターにも役立つことがあります。
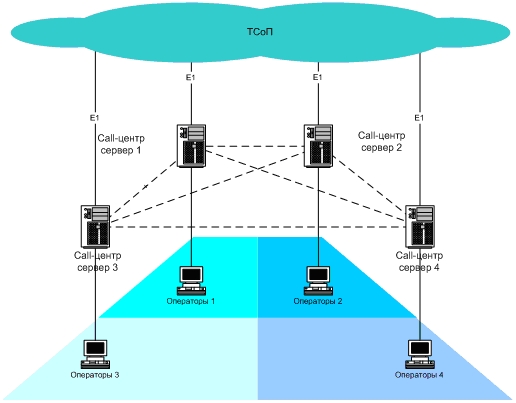
最近、実際のコールセンターにホットスタンバイスキームを実装しましたが、既存のコールセンタープラットフォームはホットスタンバイスキームを提供していませんでした。 オペレーターの総数は75であり、公衆交換電話網(PSTN)への接続は、1つの電気通信オペレーターから4ユニットの量でE1(edss1)です。 NNNの回線の最大負荷は、システムでの同時呼び出しが90以下です(オペレーターとの会話+インラインで待機)。
私たちの戦略的な仕事は、電話サービスの中断を防ぐことでした。 CNNでさえ、コールを処理するとき、1つのE1ストリームの損失は不快ではありますが、怖くないということを理解することから始めました。 既存のコールセンタープラットフォームのフレームワークでは問題を解決できなかったため、独立してインストールされた2つのコールセンターサーバーを構築し、その数を4に増やすというフレームワークで範囲を拡大して問題を解決することにしました。 理想的には、E1ストリームを独立して設置された4つの異なるコールセンターに配信することが望ましいでしょう。 つまり、独立したコールセンターのいずれかが「クラッシュ」した場合、他のプラットフォームはコールのサービスを継続する必要があり、オペレーターの職場はコールセンターサーバーとの接続を失い、自動的に別のサーバーに切り替わり、コールセンターシステム全体が電話のサービスを継続しますコールセンターの1つのサーバーと1つのE1ストリームで最小限の損失を被っただけです。
独立して確立されたコールセンターのいずれかの「フォール」は、このコールセンターと通信事業者にもたらされるフローのE1接続の中断を伴います。 したがって、イベント「コールセンターのドロップ」と「E1フローでの通信ブレークダウン」は同等であると考えています。
通信事業者の側で作業します。 通信事業者の機器を使用すると、メインの宛先が利用できない場合に、別の宛先にコールをルーティングできます。 つまり、特定のE1ストリームにコールをルーティングするときに現在の方向が使用できない場合(「E1ストリームでの通信の損失」)、通信事業者は同じコールを別の方向にルーティングします(他のE1フロー)。 電気通信事業者側でE1フローのコールの「クロスルーティング」を設定することにより、この問題を電気通信事業者と一緒に解決しました。 つまり、操作中に通信事業者のスイッチがE1ストリームとの切断を修正した場合、コールは他のE1フローにルーティングされ、通信復旧の場合、初期ルーティングスキームが再開されます。 さらに、テレコムオペレータと、コールを受信するためのE1フローの優先順位を決定しました。 ルーティングと通話分配のタスクが解決された後、ヘルプデスク内で通話サービスを編成する必要がありました。
E1ストリームでのコールのクロスルーティングにより、コールセンターのいずれかが落ちたときにコールの処理が拒否される可能性を完全に排除することができました。
ヘルプデスクのサイトで働きます。 ヘルプデスクへの電話を受ける問題が解決された後(E1ストリームのいずれかが「落ちた」場合でも)、独立したコールセンター間に多数のルーティングタスクを設定する必要がありました。 コールセンターに接続されているオペレーターの数を制御することは管理上困難であることを提案しました。 したがって、コールセンターのいずれかでシステムにログインするオペレーターの数は規制されていません。 つまり、コールセンターの任意の時点で、オペレーターの数は、ゼロであっても、ゼロであってもかまいません。 さらに、オペレーターに均一な負荷をかける必要があります。 つまり、同じ時間間隔で、コールセンターのいずれかに接続している各オペレーターは、ほぼ同じ数のコールを受信する必要があります。 さらに、オペレーターの職場が別のコールセンターに自動的に切り替わる必要があります(現在のコールセンターが該当する場合)。 実際、すべてのコールセンターからのコール処理の統計情報を組み合わせて、各コールセンターのリアルタイム統計情報インジケータを個別に表示する必要があります。
まず、すべてのコールセンターを、各コールセンターが他のVoIPチャネルに接続されるように組み合わせ、30の音声接続の処理を提供しました。 このような冗長性により、必要に応じて、E1ストリームで受信した30のすべてのコールを隣接するコールセンターのいずれかに「渡す」ことができました。 次のタスクは、コールセンターオペレーター間の負荷を分散し、コールセンターの1つでサービスキューが表示されないようにするコールセンター間のコールルーティングのロジックを実装することでした。
次のステップは、コールセンターオペレーターの負荷を分散する要件が満たされるように、コールセンター間でコールを交換するためのロジックを開発することでした。 それはそのように行われました。 (E1ストリームからの)各コールセンターへの各コールを受信すると、コールセンターは外部データベースのストアドプロシージャを呼び出し、それにパラメータを渡します。
-番号A(AON)
-番号B(ダイヤル番号)
-無料のオペレーター(Fi)の数、つまり、システム内のステータスおよび「コールを処理する準備ができている」状態のオペレーターの数
-コールを処理するオペレーター(Ni)の総数、つまり、ステータス「break」を除く、任意のステータス(「準備完了」、「ビジー」、「ポストコール処理」)のシステム内のオペレーターの数。
-キュー内のサブスクライバーの数(Qi)
-呼び出しがこのサーバーに配信される場合の推定応答タイムアウト(Ti)。
ストアドプロシージャは、出力パラメーターとして、呼び出しのリダイレクト先となるサーバーの名前を返します。 次の定数がストアドプロシージャで使用されます。関連するサーバーから受信した情報を考慮する時間間隔(P)。 エラー(E)。これは、オペレーターの負荷が同じであると想定しているものを超えていません。
どのサーバーにコールを送信するかを決定するロジックは、各サーバーのオペレーターの作業負荷(Ri)のインジケーターを考慮します。 オペレーターのワークロードのインスタントインジケーターとして次の値を使用します:a)キューがある場合、これはキュー内の推定顧客待機時間(Ti)またはシステム内のオペレーターの総数(Ni)に対するキューの長さ(Qi)の比率です。 b)キューがない場合、空きオペレーターの数の逆数(1 / Fi)は、オペレーターの作業負荷の指標として機能します。 キューがない場合にインスタントロードインジケーターが疑わしい場合、キューの場合にどのインジケーターを選択するかという質問は、さらに調査する必要があります。 さまざまなコールセンタープラットフォーム間で負荷を分散するために、システム内のオペレーターの総数に対するキューの長さの比率(Qi / Ni)を使用することで最良の結果が得られることが実験的にわかっています。 このインジケーターの信頼性が高い理由は、異なるコールセンタープラットフォーム(および2つのメーカーの2つの異なるプラットフォームがあった場合)がキュー内の予想待機時間を計算するために独自のアルゴリズムを使用しているという事実にもあります。値の異なる離散化。 2つの同一のコールセンタープラットフォーム間で負荷を分散するためにバランシングメカニズムが使用される場合、予期される応答タイムアウトの使用がより正当化されます。
したがって、コールセンターサーバーごとに、オペレーターの作業負荷のインスタントインジケーターが計算されました。 計算では、フリーオペレーターの数がゼロの場合、オペレーターの総数がゼロの場合の例外的な状況を処理します。 指定された時間間隔(P)より前に受信したサーバー負荷インジケーター(Ri)を遮断します。
通話を送信するサーバーを決定する最後の手順は、負荷の最も少ないコールセンターサーバーを選択することです。 同時に、サーバー間のワークロードの差が指定されたエラー(実際には10%またはE = 0.10に等しい)を超えない場合、サーバーコールセンターへの呼び出しの循環配信のメカニズム(最初のサーバーへの最初の呼び出し、2番目から2番目への呼び出しなど)。
ここでは、実際には、すべてが呼び出しの分布に従っています。 ストアドプロシージャの結果に応じてターゲットサーバーとして指定されたサーバーに呼び出しを転送できない場合は、データベースにこれを書き留めて、次のサーバーに呼び出しを転送することを追加する必要があります。
ヘルプデスクのサイトでのジョブの編成。 すべてのヘルプデスクジョブは、論理的に4つのゾーンに分割されました。 各ゾーンのワークステーションは、このゾーンのワークステーションのメインのコールセンターであるコールセンターに接続されていました(図を参照)。 同時に、職場の設定で代替(追加)コールセンターサーバーが示されました。ワークステーションとコールセンターの間に切断があり、コールセンターがクライアントワーカーの要求に応答しない場合、オペレーターのワークステーションに接続する必要があります場所。
対処する必要がある別の問題は、単一の場所での統計の収集でした。 しかし、そこにはすべてが非常に単純で、データを1つの一般的なビューに削減して、さまざまなデータベースから通常の統計を1つに収集します。 一般に、説明するものはありません。
その結果、ヘルプデスクでは、コールセンターサーバーのいずれかの「ドロップ」によってわずか25%の電力損失しか生じなかった場合に、このような仕事の組織ができました。 着信コールのフローは引き続き処理され、オペレーターは別の動作中のコールセンターサーバーに自動的に切り替えます。
サハブトディノフ・アイラット
PS:現時点では、異なるメーカーの2つの異なるコールセンター(負荷分散や統計収集など)向けにこのような分散システムを構築するタスクは解決され、機能しています。 作業中-あるメーカーのコールセンターソリューションに基づいた4 e1フローの完全な分散システムの構築
すべてのコールセンタープラットフォームが完全な「ホット」冗長性の可能性を想定しているわけではありませんが、完全な「ホット」予約を含む多くのプラットフォームでは、2番目のコールセンターの購入に匹敵します。
そのため、コールセンターアーキテクチャが「ホット」な冗長性の作成または冗長性スキームの編成コストの最適化を許可していない場合でも、コールセンターの容量を予約できるようにする方法。 すぐに予約しますが、このソリューションは主に大規模なコールセンターに焦点を当てていますが、場合によっては少数のオペレーターにも役立つことがあります。
最近、実際のコールセンターにホットスタンバイスキームを実装しましたが、既存のコールセンタープラットフォームはホットスタンバイスキームを提供していませんでした。 オペレーターの総数は75であり、公衆交換電話網(PSTN)への接続は、1つの電気通信オペレーターから4ユニットの量でE1(edss1)です。 NNNの回線の最大負荷は、システムでの同時呼び出しが90以下です(オペレーターとの会話+インラインで待機)。
私たちの戦略的な仕事は、電話サービスの中断を防ぐことでした。 CNNでさえ、コールを処理するとき、1つのE1ストリームの損失は不快ではありますが、怖くないということを理解することから始めました。 既存のコールセンタープラットフォームのフレームワークでは問題を解決できなかったため、独立してインストールされた2つのコールセンターサーバーを構築し、その数を4に増やすというフレームワークで範囲を拡大して問題を解決することにしました。 理想的には、E1ストリームを独立して設置された4つの異なるコールセンターに配信することが望ましいでしょう。 つまり、独立したコールセンターのいずれかが「クラッシュ」した場合、他のプラットフォームはコールのサービスを継続する必要があり、オペレーターの職場はコールセンターサーバーとの接続を失い、自動的に別のサーバーに切り替わり、コールセンターシステム全体が電話のサービスを継続しますコールセンターの1つのサーバーと1つのE1ストリームで最小限の損失を被っただけです。
独立して確立されたコールセンターのいずれかの「フォール」は、このコールセンターと通信事業者にもたらされるフローのE1接続の中断を伴います。 したがって、イベント「コールセンターのドロップ」と「E1フローでの通信ブレークダウン」は同等であると考えています。
通信事業者の側で作業します。 通信事業者の機器を使用すると、メインの宛先が利用できない場合に、別の宛先にコールをルーティングできます。 つまり、特定のE1ストリームにコールをルーティングするときに現在の方向が使用できない場合(「E1ストリームでの通信の損失」)、通信事業者は同じコールを別の方向にルーティングします(他のE1フロー)。 電気通信事業者側でE1フローのコールの「クロスルーティング」を設定することにより、この問題を電気通信事業者と一緒に解決しました。 つまり、操作中に通信事業者のスイッチがE1ストリームとの切断を修正した場合、コールは他のE1フローにルーティングされ、通信復旧の場合、初期ルーティングスキームが再開されます。 さらに、テレコムオペレータと、コールを受信するためのE1フローの優先順位を決定しました。 ルーティングと通話分配のタスクが解決された後、ヘルプデスク内で通話サービスを編成する必要がありました。
E1ストリームでのコールのクロスルーティングにより、コールセンターのいずれかが落ちたときにコールの処理が拒否される可能性を完全に排除することができました。
ヘルプデスクのサイトで働きます。 ヘルプデスクへの電話を受ける問題が解決された後(E1ストリームのいずれかが「落ちた」場合でも)、独立したコールセンター間に多数のルーティングタスクを設定する必要がありました。 コールセンターに接続されているオペレーターの数を制御することは管理上困難であることを提案しました。 したがって、コールセンターのいずれかでシステムにログインするオペレーターの数は規制されていません。 つまり、コールセンターの任意の時点で、オペレーターの数は、ゼロであっても、ゼロであってもかまいません。 さらに、オペレーターに均一な負荷をかける必要があります。 つまり、同じ時間間隔で、コールセンターのいずれかに接続している各オペレーターは、ほぼ同じ数のコールを受信する必要があります。 さらに、オペレーターの職場が別のコールセンターに自動的に切り替わる必要があります(現在のコールセンターが該当する場合)。 実際、すべてのコールセンターからのコール処理の統計情報を組み合わせて、各コールセンターのリアルタイム統計情報インジケータを個別に表示する必要があります。
まず、すべてのコールセンターを、各コールセンターが他のVoIPチャネルに接続されるように組み合わせ、30の音声接続の処理を提供しました。 このような冗長性により、必要に応じて、E1ストリームで受信した30のすべてのコールを隣接するコールセンターのいずれかに「渡す」ことができました。 次のタスクは、コールセンターオペレーター間の負荷を分散し、コールセンターの1つでサービスキューが表示されないようにするコールセンター間のコールルーティングのロジックを実装することでした。
次のステップは、コールセンターオペレーターの負荷を分散する要件が満たされるように、コールセンター間でコールを交換するためのロジックを開発することでした。 それはそのように行われました。 (E1ストリームからの)各コールセンターへの各コールを受信すると、コールセンターは外部データベースのストアドプロシージャを呼び出し、それにパラメータを渡します。
-番号A(AON)
-番号B(ダイヤル番号)
-無料のオペレーター(Fi)の数、つまり、システム内のステータスおよび「コールを処理する準備ができている」状態のオペレーターの数
-コールを処理するオペレーター(Ni)の総数、つまり、ステータス「break」を除く、任意のステータス(「準備完了」、「ビジー」、「ポストコール処理」)のシステム内のオペレーターの数。
-キュー内のサブスクライバーの数(Qi)
-呼び出しがこのサーバーに配信される場合の推定応答タイムアウト(Ti)。
ストアドプロシージャは、出力パラメーターとして、呼び出しのリダイレクト先となるサーバーの名前を返します。 次の定数がストアドプロシージャで使用されます。関連するサーバーから受信した情報を考慮する時間間隔(P)。 エラー(E)。これは、オペレーターの負荷が同じであると想定しているものを超えていません。
どのサーバーにコールを送信するかを決定するロジックは、各サーバーのオペレーターの作業負荷(Ri)のインジケーターを考慮します。 オペレーターのワークロードのインスタントインジケーターとして次の値を使用します:a)キューがある場合、これはキュー内の推定顧客待機時間(Ti)またはシステム内のオペレーターの総数(Ni)に対するキューの長さ(Qi)の比率です。 b)キューがない場合、空きオペレーターの数の逆数(1 / Fi)は、オペレーターの作業負荷の指標として機能します。 キューがない場合にインスタントロードインジケーターが疑わしい場合、キューの場合にどのインジケーターを選択するかという質問は、さらに調査する必要があります。 さまざまなコールセンタープラットフォーム間で負荷を分散するために、システム内のオペレーターの総数に対するキューの長さの比率(Qi / Ni)を使用することで最良の結果が得られることが実験的にわかっています。 このインジケーターの信頼性が高い理由は、異なるコールセンタープラットフォーム(および2つのメーカーの2つの異なるプラットフォームがあった場合)がキュー内の予想待機時間を計算するために独自のアルゴリズムを使用しているという事実にもあります。値の異なる離散化。 2つの同一のコールセンタープラットフォーム間で負荷を分散するためにバランシングメカニズムが使用される場合、予期される応答タイムアウトの使用がより正当化されます。
したがって、コールセンターサーバーごとに、オペレーターの作業負荷のインスタントインジケーターが計算されました。 計算では、フリーオペレーターの数がゼロの場合、オペレーターの総数がゼロの場合の例外的な状況を処理します。 指定された時間間隔(P)より前に受信したサーバー負荷インジケーター(Ri)を遮断します。
通話を送信するサーバーを決定する最後の手順は、負荷の最も少ないコールセンターサーバーを選択することです。 同時に、サーバー間のワークロードの差が指定されたエラー(実際には10%またはE = 0.10に等しい)を超えない場合、サーバーコールセンターへの呼び出しの循環配信のメカニズム(最初のサーバーへの最初の呼び出し、2番目から2番目への呼び出しなど)。
ここでは、実際には、すべてが呼び出しの分布に従っています。 ストアドプロシージャの結果に応じてターゲットサーバーとして指定されたサーバーに呼び出しを転送できない場合は、データベースにこれを書き留めて、次のサーバーに呼び出しを転送することを追加する必要があります。
ヘルプデスクのサイトでのジョブの編成。 すべてのヘルプデスクジョブは、論理的に4つのゾーンに分割されました。 各ゾーンのワークステーションは、このゾーンのワークステーションのメインのコールセンターであるコールセンターに接続されていました(図を参照)。 同時に、職場の設定で代替(追加)コールセンターサーバーが示されました。ワークステーションとコールセンターの間に切断があり、コールセンターがクライアントワーカーの要求に応答しない場合、オペレーターのワークステーションに接続する必要があります場所。
対処する必要がある別の問題は、単一の場所での統計の収集でした。 しかし、そこにはすべてが非常に単純で、データを1つの一般的なビューに削減して、さまざまなデータベースから通常の統計を1つに収集します。 一般に、説明するものはありません。
その結果、ヘルプデスクでは、コールセンターサーバーのいずれかの「ドロップ」によってわずか25%の電力損失しか生じなかった場合に、このような仕事の組織ができました。 着信コールのフローは引き続き処理され、オペレーターは別の動作中のコールセンターサーバーに自動的に切り替えます。
サハブトディノフ・アイラット
PS:現時点では、異なるメーカーの2つの異なるコールセンター(負荷分散や統計収集など)向けにこのような分散システムを構築するタスクは解決され、機能しています。 作業中-あるメーカーのコールセンターソリューションに基づいた4 e1フローの完全な分散システムの構築
All Articles