वर्गीकरण के लिए चींटी कॉलोनी एल्गोरिथ्म का आवेदन पहली बार 2002 में आर। परपिनेली द्वारा पेश किया गया था। एक चींटी एल्गोरिथ्म पर आधारित वर्गीकरण नियमों को निकालने की विधि को एंटीमाइनर कहा जाता है।
विधि का उद्देश्य फॉर्म के सरल नियमों को प्राप्त करना है यदि स्थिति एक परिणाम है ।
सभी विशेषताओं को श्रेणीबद्ध माना जाता है। यानी शब्दों को गुण = मूल्य के रूप में प्रस्तुत किया जाता है, उदाहरण के लिए लिंग = पुरुष। AntMiner क्रमिक रूप से नियमों की एक आदेशित सूची बनाता है। गणना नियमों के एक खाली सेट के साथ शुरू होती है और पहले एक के बनने के बाद, इस नियम द्वारा कवर की गई सभी परीक्षण डेटा इकाइयां परीक्षण सेट से हटा दी जाती हैं।
एल्गोरिथ्म काम करते समय एक निर्देशित ग्राफ का उपयोग करता है, जहां प्रत्येक विशेषता को परीक्षण सेट में ले जाने वाले संभावित मानों के रूप में मैप किया जाता है। तदनुसार, यह माना जाता है कि एल्गोरिथ्म शुरू होने से पहले, विशेषताओं के सेट और उनके संभावित मूल्यों, साथ ही साथ कई संभावित वर्गों को परीक्षण सेट से चुना जाता है।
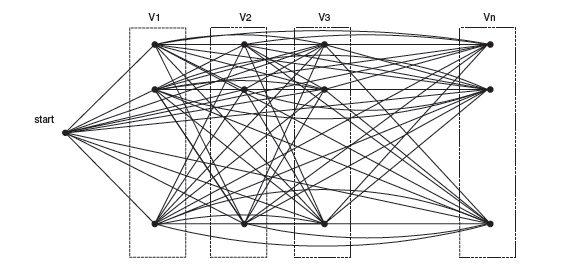
एल्गोरिथ्म का छद्म कोड निम्नानुसार है:
testSet = संपूर्ण परीक्षण सूट अलविदा (| testSet |> max_number_of खुला_शिकायतें) i = 0; PERFORM i = i + 1; I-th चींटी क्रमिक रूप से एक वर्गीकरण नियम बनाता है; I-th चींटी के शासन द्वारा दर्शाए गए मार्ग के साथ फेरोमोन को अद्यतन करना; अलविदा (i <Ant_number) सभी नियमों में से सर्वश्रेष्ठ चुनें; testSet = सर्वश्रेष्ठ नियम द्वारा कवर नहीं किए जाने वाले मामले; चक्र की समाप्ति
क्रमिक रूप से एल्गोरिथ्म के चरणों पर विचार करें।
फेरोमोन मूल्यों की शुरुआत
ग्राफ के सभी किनारों को प्रारंभिक फेरोमोन मान के साथ निम्नलिखित सूत्र के अनुसार तैयार किया गया है:
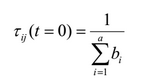
, जहाँ a कुल विशेषताओं की संख्या है, b i , i-th विशेषता के संभावित मानों की संख्या है।
नियम निर्माण
AntMiner एल्गोरिथ्म में प्रत्येक नियम में एक पूर्ववर्ती (शर्तों का एक गुण = मान) होता है और वह वर्ग जिसका प्रतिनिधित्व करता है। मूल एल्गोरिथ्म में, स्रोत डेटा में केवल स्पष्ट गुण होते हैं। मान लें कि शब्द ij = Ai = V ij , जहां A i i-th विशेषता है, और V ij A का j-th मान है।
चींटी द्वारा बनाए गए वर्तमान आंशिक नियम में इस शब्द को जोड़ा जाएगा इसकी संभावना निम्नलिखित सूत्र द्वारा निर्धारित की गई है:
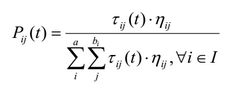
, जहां beij हेरीस्टिक मान है (बाद में निर्धारित किया जाना है), the आईजे ग्राफ के इस किनारे पर फेरोमोन मान है, और मैं वर्तमान चींटी द्वारा अभी तक उपयोग नहीं किए गए विशेषताओं का सेट हूं।
अनुमानी
परिवहन समस्या को हल करने के लिए पारंपरिक चींटी कॉलोनी एल्गोरिथ्म में, किनारे के वज़न का उपयोग फेरोमोन मान के साथ अगले शीर्ष पर तय करने के लिए किया जाता है। AntMiner में, अनुमानी सूचना की राशि है - सूचना सिद्धांत में प्रयुक्त एक शब्द। दूसरों के ऊपर कुछ नियमों को वरीयता देने के लिए यहां की गुणवत्ता को एंट्रोपी की मदद से मापा जाता है:
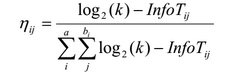
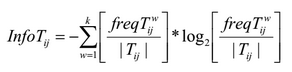
जहाँ k कक्षाओं की संख्या है, T ij सभी डेटा इकाइयों वाला सबसेट है, जहाँ ऐ की विशेषता है i ij ; | T ij | Tij में तत्वों की संख्या, freq (T w ij ) वर्ग w वाले डेटा इकाइयों की संख्या है, और विशेषताओं की कुल संख्या है, b i ith विशेषता के संभावित मूल्यों की संख्या है।
सूचना टी आईजे मूल्य जितना अधिक होगा, उतनी ही कम चींटी दी गई अवधि का चयन करेगी।
फेरोमोन मूल्यों को अद्यतन करना
प्रत्येक चींटी नियम के निर्माण को पूरा करने के बाद, फेरोमोन को निम्न सूत्र के अनुसार अपडेट किया जाता है:
τ ij (t +1) = t ij (t) + ( ij (t) .Q ∈termije वर्तमान नियम
जहां Q नियम की गुणवत्ता है, जिसकी गणना निम्न सूत्र द्वारा की जाती है:
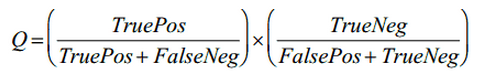
यहां, TruePos नियम द्वारा कवर की जाने वाली डेटा इकाइयों की संख्या है और जिनकी कक्षा नियम द्वारा दर्शाई गई कक्षा से मेल खाती है, FaslePos उन डेटा इकाइयों की संख्या है जो नियम से आच्छादित हैं, लेकिन जिनकी कक्षा नियम द्वारा दर्शाई गई कक्षा से भिन्न है, TrueNeg उन डेटा इकाइयों की संख्या है जो नियम द्वारा कवर नहीं किए गए हैं और जिसका वर्ग नियम के प्रतिनिधित्व वाली कक्षा से मेल नहीं खाता है, फाल्सेनेग - उन डेटा इकाइयों की संख्या, जो नियम से आच्छादित नहीं हैं, लेकिन जिनकी कक्षा नियम से प्रतिनिधित्व वाली कक्षा से मेल खाती है।
इसके वाष्पीकरण का अनुकरण करते हुए फेरोमोन की एक मात्रा को पूरा करना भी आवश्यक है। यह फेरोमोन के अद्यतन मूल्य को ध्यान में रखते हुए सरल सामान्यीकरण द्वारा किया जा सकता है।
बेहतर फेरोमोन अपडेट
एल्गोरिथ्म निष्पादन की अधिक लचीली ट्यूनिंग के लिए, वर्तमान नियम से संबंधित किनारों की संभावनाओं को अद्यतन करने के लिए निम्न सूत्र का उपयोग किया जाता है:
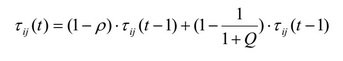
जहाँ p वाष्पीकरण गुणांक है (आमतौर पर ~ 0.1 का मान निर्धारित होता है), Q ऊपर वर्णित नियम की गुणवत्ता है। वर्तमान नियम द्वारा पसलियों को सामान्य रूप से कवर नहीं किया जाता है। यह विधि कम क्यू में फेरोमोन में कमी और उच्च (मूल विधि के विपरीत) में वृद्धि प्रदान करती है।
कुलीन चींटियों
यह तथाकथित "कुलीन" चींटियों को पेश करके एल्गोरिथ्म के अभिसरण में सुधार करना भी संभव है जो एक शब्द चुनते हैं जिसके लिए पी = अधिकतम पीज।
मूल एल्गोरिथ्म में, शब्द का चयन निम्नलिखित एल्गोरिथम के अनुसार किया जाता है:
सभी के लिए (i, j) j जी IF q term TH Pij THEN एक शब्द चुनें
जहाँ q एक समान वितरण वाला एक यादृच्छिक चर [0..1] है। यानी शब्दों की प्रायिकता घनत्व का उपयोग किया जाता है।
अभिजात वर्ग चींटियों को पेश करने के लिए, शब्द चयन एल्गोरिथ्म को निम्नानुसार बदला गया है:
यदि q1 ≤ ≤ है सभी के लिए (i, j) j जी IF q2 term TH Pij THEN एक शब्द चुनें अन्यथा पी = अधिकतम पीज के साथ एक शब्द चुनें
यहाँ q 1 और q 2 एक समान वितरण के साथ यादृच्छिक चर [0..1] हैं।
कुछ अवलोकन
AntMiner का एक एनालॉग जाने-माने Naive Bayes एल्गोरिथम है। उनकी तुलना पर मेरे प्रयोगों के अनुसार, AntMiner या तो Naive Bayes से थोड़ा बेहतर है, या यहां तक कि विभिन्न डेटा सेटों पर इससे हीन है। तुलना के लिए, हमने यहां प्रस्तुत AntMiner कार्यान्वयन और WEKA पुस्तकालय से Naive Bayes कार्यान्वयन का उपयोग किया। इसके अलावा, AntMiner गणना समय में काफी नीच है। शायद ऐसी परिस्थितियां या कुछ पूर्व शर्त हैं जिनके तहत AntMiner वास्तव में सबसे अच्छा विकल्प है।