तंत्रिका नेटवर्क पर क्या हो रहा है, इस बारे में मेरे पिछले लेख की टिप्पणियों में , वाक्यांश फिसल गया, दुर्भाग्य से, बड़े डेटा के साथ वास्तविक समस्याओं पर सीखने की प्रक्रियाओं का विज़ुअलाइज़ेशन शायद ही कभी संभव है। वास्तव में वास्तव में क्षमा करें। इसे ठीक करने का प्रयास करें। कटौती के तहत, मैं एक सरल और, आश्चर्यजनक रूप से, एक तंत्रिका नेटवर्क सीखने की प्रक्रिया के बारे में जानकारीपूर्ण दृश्य प्रदान करता हूं, जो कार्य की प्रकृति या स्वयं नेटवर्क के गुणों पर निर्भर नहीं करता है, जो कि एक मनमाने ढंग से जटिल कार्य के लिए उपलब्ध है।
ट्रेनिंग
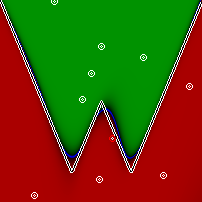
नेटवर्क को हल करने का कार्य पिछले लेख से लिया गया है। तंत्रिका नेटवर्क को दो संख्याओं - दो निर्देशांक के साथ आपूर्ति की जाती है, और यह निर्धारित करने का प्रस्ताव है कि यह बिंदु ग्राफ से ऊपर है या नहीं। आउटपुट -1, +1 या 0 (यदि बिंदु बिल्कुल चार्ट पर स्थित है) होने की उम्मीद है। इस बार कार्य को सममित किया जाएगा। निर्देशांक सीमा से लिया जाता है [-0.5; +0.5], बिंदु 0.0 बिल्कुल चित्र के केंद्र में होगा और ग्राफ भी इससे गुजरता है, इसलिए इस बिंदु पर अपेक्षित मान भी 0. है ग्राफ के ऊपर का क्षेत्र और ग्राफ के नीचे का क्षेत्र बराबर है। तो, औसतन, हमारे पास प्रत्येक इनपुट पर 0 है, और आउटपुट पर औसतन 0 की उम्मीद है।
हम एक नेटवर्क लेंगे जिसमें 15 न्यूरॉन्स की 3 परतें होंगी (प्रत्येक सक्रियण फ़ंक्शन - हाइपरटेन्जेंट) और हम इसे धीरे-धीरे धीमी गति के साथ बैक प्रचार और स्टोचस्टिक ग्रेडिएंट वंश की शास्त्रीय विधि का उपयोग करके प्रशिक्षित करेंगे। हम देखेंगे कि नेटवर्क ने क्या सीखा है, जैसा कि ऊपर चित्र में दिखाया गया है। रेंज के सभी बिंदुओं को नेटवर्क की पेशकश की जाएगी, और इस उत्तर के आधार पर, बिंदु हरे रंग के अलग-अलग रंगों में रंगा जाएगा (यदि नेटवर्क की प्रतिक्रिया 0 से अधिक है), लाल रंग के शेड्स (यदि मूल्य 0 से कम है), और अंत में, नीले रंग के शेड्स (यदि नेटवर्क द्वारा दिया गया उत्तर 0 है या इसका उत्तर है) पड़ोस)। ऊपर दी गई तस्वीर 0.22 की मानक त्रुटि के साथ पूरी तरह से प्रशिक्षित नेटवर्क के परिणामों को दिखाती है, यदि आप केवल सही उत्तरों के संकेत को देखते हैं तो यह 99% से अधिक होगा
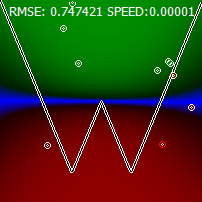
मैं इस तरह से ध्यान देता हूं, कि एक बहुत ही सामान्य तंत्रिका नेटवर्क बस इस सरल कार्य के साथ सामना नहीं कर सकता है। यह हमेशा कुछ इस तरह से निकलता है:
इस समस्या को हल करने के लिए, जैसा कि पिछले लेख में सुझाया गया है, हम नेटवर्क को तीन इनपुट बनाएंगे और लगातार 1 से तीसरी जमा करेंगे। उसके बाद, कार्य नेटवर्क के लिए संभव हो जाता है।
सत्यापन और स्वतंत्र प्रयोगों के लिए सभी कोड पिछले लेख में पाए जा सकते हैं।
दृश्य
अब विज़ुअलाइज़ेशन का मुख्य विचार। इसलिए, हमारे पास कुल 510 सिनैप्स के साथ एक नेटवर्क है। इस नेटवर्क की सीखने की प्रक्रिया इन सिनेप्स के भार में एक बदलाव है। यह लगभग 510-आयामी अंतरिक्ष में भटकने के रूप में सोचा जा सकता है। और इस स्थान पर हर बिंदु पर, नेटवर्क में एक या दूसरी दक्षता है। इस दक्षता से राहत मिलती है। जैसे चित्र में, केवल 2-आयामी चित्र नहीं है, बल्कि 510-आयामी एक है। यह कल्पना करना कठिन है, मैं सहमत हूं। लेकिन यह एक राहत है, जिसका अर्थ है कि इस राहत के साथ यात्रा करने वाला नेटवर्क उसी तरह से व्यवहार करेगा जैसे हम तब करते हैं जब हम स्पर्श द्वारा रास्ता खोजते हैं। मानव मस्तिष्क ऐसी समस्याओं को हल करने के लिए अनुकूलित है, जिसका अर्थ है कि नेटवर्क का व्यवहार शायद हमारे लिए सहज होगा।
ऐसे क्षेत्र हैं जहां राहत चिकनी है, लेकिन मूल रूप से यह बहुत बीहड़ है, जैसा कि एक चक्करदार क्षेत्र में है। हालांकि, भले ही राहत बहुत दांतेदार हो और इसमें बड़ी संख्या में स्थानीय मैक्सिमा शामिल हों, इसमें काफी चिकना लिफाफा हो सकता है।
शिक्षण एल्गोरिथ्म, व्यक्तिगत प्रशिक्षण उदाहरणों से आवेगों को प्राप्त कर सकता है, इस ग्राफ के कोप के साथ सरपट दौड़ सकता है, लेकिन सामान्य तौर पर यह नीचे गिर जाएगा। इस तरह के एक आंदोलन को देखते हुए, हम देखेंगे कि 510-आयामी अंतरिक्ष में एक बिंदु लगभग दौड़ता है, लेकिन औसतन यह एक दिशा में कम या ज्यादा रेंगता है। इन आंदोलनों का पालन करें।
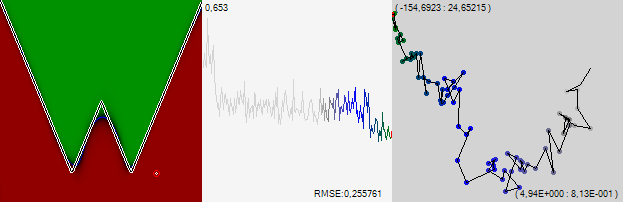
बेशक, हर कोई 510-आयामी अंतरिक्ष में सीधे एक बिंदु के आंदोलन का पालन नहीं कर सकता है, इसलिए हम धोखा देते हैं। हम इस 510-आयामी स्थान को दो-आयामी स्क्रीन स्थान पर बेतरतीब ढंग से प्रोजेक्ट करते हैं। हम प्रत्येक सिंक पर एक यादृच्छिक इकाई वेक्टर असाइन करेंगे, और हम सिंक के वजन से गुणा किए गए इन सभी वैक्टरों को संक्षेप में प्रस्तुत करेंगे। बड़ी संख्या के कानून के अनुसार, योग बिंदु 0 के करीब होगा। शुरुआत के लिए, एक यादृच्छिक अप्रशिक्षित नेटवर्क लें और देखें कि प्रक्षेपवक्र कैसा दिखेगा यदि आप प्रत्येक व्यक्तिगत प्रशिक्षण उदाहरण के बाद एक बिंदु को चिह्नित करते हैं।
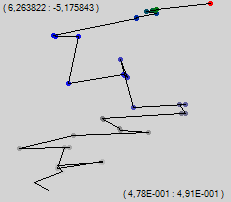
ऊपरी बाएँ कोने में संख्या चित्र के ऊपरी बाएँ कोने के स्थान की स्थिति है, और निचले दाएँ में संख्याएँ प्रदर्शित क्षेत्र के आयाम हैं।
हम "ब्राउनियन" आंदोलन देखते हैं, जिसमें सामान्य प्रवृत्ति ऊपर की ओर है। चलते-चलते एल्गोरिथ्म बदल देते हैं। हम त्रुटि के एक ही पिछड़े प्रसार का उपयोग करेंगे, केवल प्रशिक्षण परिवर्तन एक ही बार में लागू नहीं किया जाएगा, लेकिन धीरे-धीरे, कई चरणों में। मेरे कार्यक्रम में, मैं इस पद्धति को "धीमी सीखने की ढाल" कहता हूं। उसी प्रशिक्षण गति पर, हमें 35 अंक मिलते हैं।

हम देखते हैं कि इस एल्गोरिथ्म में बहुत चिकनी सवारी है। हम कुछ दर्जन बिंदुओं को साबित करेंगे और एक बड़े परिमाण के साथ, हम देखेंगे कि कैसे अंतरिक्ष में नेटवर्क रेंगता है, एक चिकनी राहत में रास्ता खोज रहा है।

यह तुरंत स्पष्ट हो जाता है कि दूसरी एल्गोरिथ्म में मिलीमा के यादृच्छिक नुकसान के लिए कम संभावना क्यों है। यह दिलचस्प है कि कुछ क्षेत्रों में नेटवर्क धीरे-धीरे रेंगता है, और कुछ में - यह दिशा बदलता है जैसे कि यह माथे पर प्राप्त हुआ था। यह देखना दिलचस्प है कि ये बिंदु कैसे भिन्न हैं।

पहली तस्वीर में हम देखते हैं कि नेटवर्क धीरे-धीरे लेकिन निश्चित रूप से एक दिशा में रेंग रहा है। नए बिंदु उस क्षेत्र में आते हैं जहां नेटवर्क पहले से ही सही उत्तर प्राप्त करता है। इसके अलावा, यह एक शुद्ध रूप से हरा क्षेत्र है जिसमें नेटवर्क के आउटपुट पर मूल्य इनपुट डेटा पर बहुत कम निर्भर है। त्रुटि से व्युत्पन्न छोटा है, और तदनुसार, नेटवर्क पर नियंत्रण प्रभाव छोटा है। लेकिन दूसरी तस्वीर में, अगला बिंदु शून्य के करीब आता है, जहां नेटवर्क में त्रुटि के व्युत्पन्न का एक बड़ा मूल्य है। इसके अलावा, बिंदु ग्राफ के नीचे है, -1 वहां अपेक्षित है, और नेटवर्क ने हरे रंग को दिखाया, रंग से देखते हुए, +0.8 के बारे में। एक बहुत बड़ी गलती एक बड़ी व्युत्पत्ति के साथ हुई, नेटवर्क को नीचे से एक किक मिली और ऊपर एक नए रास्ते पर चला गया। अंतिम (तीसरे) चित्र से पता चलता है कि पूरा नीला क्षेत्र ऊंचा हो गया है। तथ्य यह है कि सीखने की राह के साथ नेटवर्क की दिशा और चित्र पारी की दिशा निश्चित रूप से, एक दुर्घटना, लेकिन सुंदर है।
हम कार्यक्रम को 50 अंक नहीं, बल्कि 200 बताते हैं और नेटवर्क लर्निंग पथ का आनंद लेते हैं। 510-आयामी अंतरिक्ष के ऊपर की राहत हमें दिखाई नहीं देती है, लेकिन एक अदृश्य भूलभुलैया के माध्यम से अंधा नेटवर्क के क्रॉलिंग में, समस्या क्षेत्रों को स्पष्ट रूप से समझा जाता है - अदृश्य दीवारें, जो नेटवर्क यहां और वहां दस्तक देता है, और एक नई दिशा में ढोंगी।
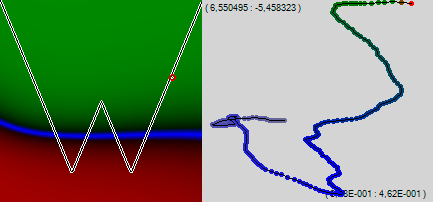
हम देखते हैं कि केवल 200 प्रशिक्षण के कुछ उदाहरणों के बाद, हमारी विभाजित नीली रेखा का बायाँ हिस्सा थोड़ा-थोड़ा ऊपर की ओर झुकना शुरू हुआ। आइए हम त्रुटि के पीछे प्रसार ("मरोड़ते") के शास्त्रीय एल्गोरिदम पर लौटें और एक और 200 अंक जोड़ें।
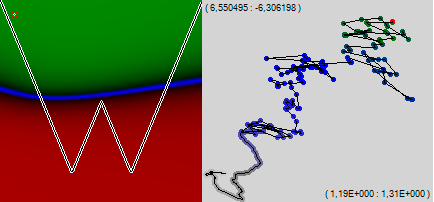
हम देखते हैं, इस तथ्य के बावजूद कि नेटवर्क पागल की तरह चिकोटी लेना शुरू कर दिया, यह एक ही दिशा में, सिद्धांत रूप में, एक ही दिशा में और सिद्धांत रूप में, एक ही अंतिम गति से आगे बढ़ना जारी रखा। आप काफी स्पष्ट रूप से घाटी की कल्पना कर सकते हैं जिसके साथ नेटवर्क दीवारों को महसूस करते हुए एक बेहतर जीवन के लिए रेंगता है। इसकी 510-आयामीता के बावजूद, राहत बहुत अच्छी तरह से पता लगाया गया है। और तस्वीर में, न केवल बाएं, बल्कि ग्राफ के दाहिने किनारे भी झुकना शुरू कर दिया।
हम इस नीरस आंदोलन को क्यों देखते हैं? यह स्पष्ट है कि नेटवर्क तब तक सीखेगा जब तक कि नीली रेखा के किनारों को दोनों तरफ तेजी से ऊपर की ओर देखो। इसके लिए, कुछ समानताओं के पैमानों को बहुत अधिक बदलना होगा, जो अब से बहुत बड़ा हो जाएगा। व्यक्तिगत उदाहरण केवल उन्हें थोड़ा आगे बढ़ाते हैं, और महत्वपूर्ण बनने से पहले बहुत सारे उदाहरणों की आवश्यकता होगी। यह ऐसे सिनेप्स के वजन में धीरे-धीरे वृद्धि है जो नेटवर्क के प्रशिक्षण पथ को एक अच्छी तरह से चिह्नित प्रवृत्ति के साथ खींचता है, इस दिशा में जो हमने शुरुआत में ही इस सिंकैप को सौंपा था। सिनैप्स, प्रशिक्षण प्रक्रिया के दौरान जिन मूल्यों को एक संकीर्ण सीमा में बदलती है, वे प्रक्षेपवक्र पर शायद ही ध्यान देने योग्य हैं।
तो हम क्या समझते हैं?
राहत को देखा नहीं जा सकता है, कम से कम होम कंप्यूटर पर करना मुश्किल है, लेकिन नेटवर्क के व्यवहार से आप समझ सकते हैं कि यह क्या है।
गैस जोड़ें
आइए नेटवर्क को प्रशिक्षित करना जारी रखें, लेकिन सीखने के पथ पर प्रत्येक बाद के बिंदु को प्रत्येक एक मामले के अध्ययन के बाद नहीं, बल्कि 1000 के बाद जारी रखें।
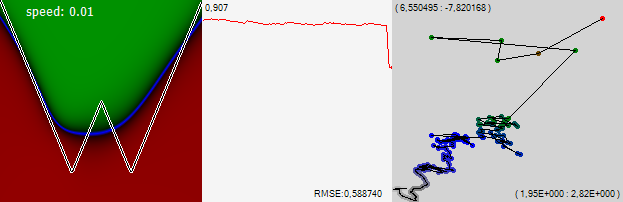
यह देखा जा सकता है कि एक पूरे के रूप में नेटवर्क ऊपर और दाईं ओर रेंगना जारी रखा, ग्राफ के किनारों को झुकाते हुए। आकृति के बीच में ग्राफ पिछले 1000 उदाहरणों के लिए मानक त्रुटि है। इस ग्राफ का एक बिंदु सही चित्र में सीखने के मार्ग पर एक बिंदु से मेल खाता है। जब आप गति में जुड़ जाते हैं तो आप स्पष्ट रूप से देख सकते हैं कि त्रुटि कैसे तेजी से घटने लगी। ग्राफ़ के ऊपरी बाएँ कोने में संख्या वह पैमाना है जिसमें ग्राफ़ प्रदर्शित होता है, और निचले दाएँ कोने में त्रुटि मान स्वयं प्रदर्शित होता है।
इसलिए, हम बहुत ही बहुआयामी अंतरिक्ष के माध्यम से अपनी यात्रा जारी रखते हैं।
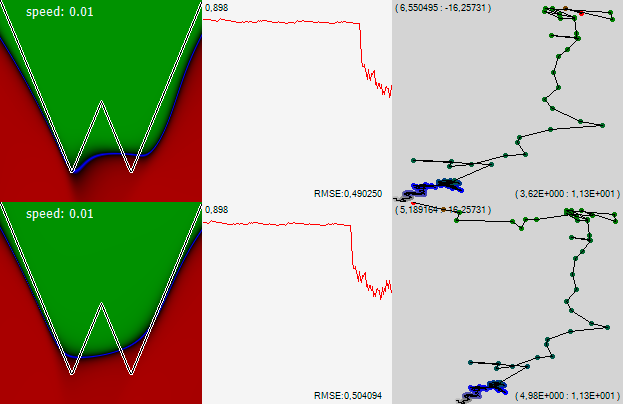
ध्यान दो! कुछ बिंदु पर, नेटवर्क ने एक दिशा में नीरस बहती रोक दी और एक क्षेत्र में बाहर लटका दिया। लेकिन फिर एक और तेज आंदोलन ने नेटवर्क को इस इंप्रोमेटू तालाब से बाहर धकेल दिया, और यह बहुत जल्दी बाईं ओर आगे बढ़ गया। त्रुटि का ग्राफ बताता है कि प्रक्षेपवक्र के इस खंड में त्रुटि थोड़ी कम थी। लेकिन स्पष्ट रूप से कोई निर्णय लेने के लिए पर्याप्त नहीं है। और, इस बीच, बाईं तस्वीर को देखते हुए, आप देख सकते हैं कि इस झील में नेटवर्क ने यह समझना सीख लिया है कि यह जिस ग्राफ का अध्ययन करता है वह दो चढ़ाव है। फिर, बाईं ओर भागते हुए, नेटवर्क ने यह ज्ञान खो दिया। मान लेते हैं कि अगली बार जब नेटवर्क एक ही तरीके से नीरस बहना बंद कर देता है और इसके लिए एक दिलचस्प जगह को ध्यान से महसूस करना शुरू कर देता है, तो हम यह मान लेंगे कि यह कुछ उपयोगी पाया गया है, और इसकी गति को कम करता है, जिससे यह पाया गया स्थान ध्यान से जांचने का अवसर देता है।
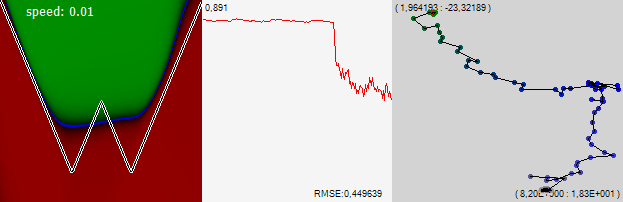
और अब नेटवर्क फिर से एक नई अच्छी जगह का सावधानीपूर्वक निरीक्षण करना शुरू कर देता है। हमें यह पसंद है, हम गति को 3 गुना कम कर देते हैं। जैसा कि आप देख सकते हैं, हमारी अंतर्दृष्टि के लिए, हमें त्रुटि में तेज सुधार के साथ पुरस्कृत किया गया था, और नेटवर्क ने खुद को पहले से ही अंतरिक्ष के एक सीमित क्षेत्र में एक नया समाधान खोजना शुरू कर दिया था, जिसमें, जाहिर है, एक अच्छा स्थानीय न्यूनतम है।
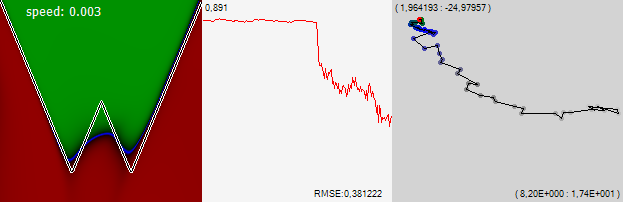
प्राथमिकता तय करने के लिए, मैं उसे अपना नाम: "विज़ुअलाइज़ेशन कोर्डिकी" कहूंगा, जब तक कि कोई कम सामंजस्यपूर्ण और इसके लिए व्यक्तित्व नाम की कमी के साथ नहीं आता।
तो हमारे निष्कर्ष क्या हैं?
- नेटवर्क के प्रशिक्षण पथ को देखते हुए, कोई स्पष्ट रूप से अंतर कर सकता है जब नेटवर्क स्थानीय मिनीमा के कनेक्टेड कॉम्पैक्ट क्षेत्र में होता है, और जब यह एक घाटी से ढाल या एक क्षेत्र से दूसरे क्षेत्र में ढाल के साथ चलता है। संभवतः, नेटवर्क का अवलोकन करने के बाद, आप अदृश्य इलाके की अन्य विशेषताओं को अलग कर सकते हैं, जिसके साथ नेटवर्क यात्रा करता है।
- अंतर इतना ध्यान देने योग्य है कि इसका उपयोग नेटवर्क के प्रशिक्षण मोड को बदलने के बारे में निर्णय लेने के लिए किया जा सकता है। राहत की इन विशेषताओं के साथ जुड़े माध्य-वर्ग त्रुटि में परिवर्तन भी देखे गए हैं, लेकिन वे बहुत मामूली हैं, शोर की पृष्ठभूमि के खिलाफ भेद करना मुश्किल है और सभी संभावना में, निर्णय लेने के आधार के रूप में कार्य नहीं कर सकते हैं। कभी-कभी आप उन क्षेत्रों को भी देख सकते हैं जहां नेटवर्क त्रुटि बढ़ रही है। लेकिन दोनों प्रकार के विज़ुअलाइज़ेशन से पता चलता है कि नेटवर्क चुने हुए दिशा में जाता है, और वहाँ बहुत बेहतर समाधान पाता है, जिसका प्रभाव बाद में ध्यान देने योग्य हो जाएगा, जैसे कि, उदाहरण के लिए, हमारी समस्या में दो चढ़ाव।
- मेरा एल्गोरिथ्म इस प्रकार है: यदि नेटवर्क घाटी के साथ चलना बंद कर देता है और एक सीमित क्षेत्र का अध्ययन करना शुरू कर देता है, तो आपको यह देखने की आवश्यकता है कि क्या इस क्षेत्र में पाए जाने वाले समाधान अच्छे से फिसलते हैं, इस क्षेत्र के रास्ते पर मिलने की तुलना में वे बेहतर हैं। यदि ऐसा है, तो नेटवर्क को इस क्षेत्र का अधिक बारीकी से अध्ययन करने की अनुमति देकर गति को कम करें, और संभवतः इसमें एक अच्छा समाधान ढूंढें। यदि अच्छे समाधान नहीं मिलते हैं, तो आप तब तक इंतजार कर सकते हैं जब तक कि नेटवर्क खुद ही क्षेत्र को छोड़कर कुछ घाटी के माध्यम से छोड़ देता है, या, यदि खोज में देरी हो रही है, तो इसे बाहर बढ़ाएं, गति बढ़ाना।
- लेख में वर्णित नेटवर्क को सीखने की प्रक्रिया की कल्पना करने की विधि अप्रत्याशित रूप से सूचनात्मक है। स्पष्ट रूप से औसत त्रुटि को देखने से अधिक है, और कभी-कभी मूल कार्य के साथ अर्जित ज्ञान के नक्शे की तुलना करने से भी अधिक।
- विज़ुअलाइज़ेशन विधि कार्य की प्रकृति या नेटवर्क टोपोलॉजी पर निर्भर नहीं करती है, इसका उपयोग सीखने की प्रक्रिया को कल्पना करने के लिए किया जा सकता है, जिसमें जटिल रूप से संगठित नेटवर्क शामिल हैं, मुश्किल कार्यों के साथ जो खराब दृश्यमान हैं।
अंत में, मेरा सुझाव है कि आप एक सीखने के नेटवर्क का आनंद लें। 1:26 पर, आप देख सकते हैं कि मैं नेटवर्क द्वारा पाए जाने वाले न्यूनतम क्षेत्र से कैसे खुश नहीं था, और मैंने इसे एक और देखने के लिए भेजा, बस सीखने की गति को जोड़ते हुए।
UPD: विज़ुअलाइज़ेशन में एक कमी है। सभी सिनैप्स को महत्व में समान माना जाता है। जबकि वास्तव में, यह, ऐसा नहीं है। कुछ सिनैप्स अंतिम परिणाम को बहुत प्रभावित करते हैं, कुछ लगभग कोई भूमिका नहीं निभाते हैं। महत्व से गुणा करना अच्छा होगा। महत्व का एक अच्छा उपाय किसी दिए गए सिनेप्स की भार त्रुटि का व्युत्पन्न है। लेकिन समस्या यह है कि विभिन्न मामलों के अध्ययन के लिए यह बहुत भिन्न होता है। यह पूरे प्रशिक्षण नमूने पर औसत करने के लिए आवश्यक होगा, लेकिन मेरे कार्य में प्रशिक्षण नमूना हर बार अलग होता है और महत्व चलता है और पिछले 1000 प्रशिक्षण उदाहरणों पर औसत होने पर भी चित्र बहुत अधिक शोर करता है। अब तक, मुझे नहीं पता है कि इस समस्या को कैसे हल किया जाए।
UPD 2: समस्या का समाधान। मैं प्रशिक्षण के पूरे समय के लिए व्युत्पन्न के आरएमएस मूल्य लेता हूं। सैकड़ों हजारों उदाहरणों में, synapses का महत्व स्थिर हो जाता है और विभिन्न synapses के लिए परिमाण के लगभग तीन आदेशों से भिन्न होता है। हालांकि, यह अजीब नहीं है, इस तरह के एक दृश्य कम जानकारीपूर्ण है। या किसी अन्य तरीके से जानकारीपूर्ण, मैं यह भी नहीं जानता कि यह कैसे कहना है।
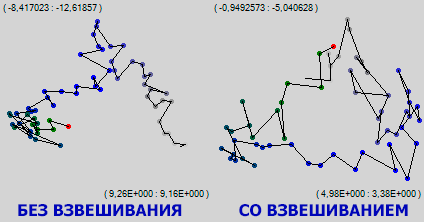
आकृति में, नेटवर्क प्रशिक्षण का एक ही खंड दर्शाया गया है। यह देखा जा सकता है कि जहां साधारण दृश्य में स्थानीय मिनिमा का एक क्षेत्र दिखाई देता था जिसमें नेटवर्क लंबे समय तक लटका रहता था, सिनैप्स विज़ुअलाइज़ेशन के महत्व से भारित ट्रैम्पलिंग का दृश्य एक स्थान पर नहीं था, इसके अलावा, एक स्थिर बहाव और दाईं ओर प्रक्षेपवक्र के हरे भाग पर दिखाई देता है। जाहिर है, जबकि एक पूरे के रूप में नेटवर्क एक छोटे से क्षेत्र में मुद्रांकन कर रहा है, यह बहुत गहन और सार्थक रूप से अपने सबसे अच्छे synapses को स्थानांतरित कर रहा है। जैसा कि वे कहते हैं, सेलुलर स्तर पर मैं बहुत व्यस्त हूं।