Since the last publication in the Julia language world, many interesting things have happened:
- She took all the first places in terms of growth of support packages. For this I love statistics - the main thing is to choose a convenient unit of measurement, for example, percentages as in the given resource
- Version 1.3.0 has been released - of the most large-scale innovations there are the modernization of the package manager and the emergence of multi-threaded concurrency
- Julia Gets Nvidia Support
- The American Department of Advanced Studies in the field of energy allocated a lot of money to solve optimization problems
At the same time, there is a noticeable increase in interest from developers, which is expressed by abundant benchmarking:
- International Energy Agency checks multidimensional optimization packages
- Datasayantists test work with GPU
- Not a bit biased guys compare integrators for diffurs
- And enthusiasts compare languages on basic tasks .
We just rejoice at new and convenient tools and continue to study them. Tonight will be devoted to text analysis, the search for hidden meaning in presidents' speeches and text generation in the spirit of Shakespeare and a Julia programmer, and for dessert, we feed a recursive network of 40,000 pies.
Recently here on Habré the review of packages for Julia was carried out allowing to carry out researches in the field of NLP - Julia NLP. We process texts . So let's get down to business immediately and start with the TextAnalysis package.
TextAnalisys
Let some text be given, which we represent as a string document:
using TextAnalysis str = """ Ich mag die Sonne, die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher. Ich mag den kalten Mond, wenn der Vollmond rund, Und ich mag dich mit einem Knebel in dem Mund. """; sd = StringDocument(str)
StringDocument{String}("Ich mag die ... dem Mund.\n", TextAnalysis.DocumentMetadata(Languages.Default(), "Untitled Document", "Unknown Author", "Unknown Time"))
For convenient work with a large number of documents, it is possible to change fields, for example, titles, and also, to simplify processing, we can remove punctuation and capital letters:
title!(sd, "Knebel") prepare!(sd, strip_punctuation) remove_case!(sd) text(sd)
"ich mag die sonne die palmen und das meer \nich mag den himmel schauen den wolken hinterher \nich mag den kalten mond wenn der vollmond rund \nund ich mag dich mit einem knebel in dem mund \n"
which allows you to build uncluttered n-grams for words:
dict1 = ngrams(sd) Dict{String,Int64} with 26 entries: "dem" => 1 "himmel" => 1 "knebel" => 1 "der" => 1 "schauen" => 1 "mund" => 1 "rund" => 1 "in" => 1 "mond" => 1 "dich" => 1 "einem" => 1 "ich" => 4 "hinterher" => 1 "wolken" => 1 "den" => 3 "das" => 1 "palmen" => 1 "kalten" => 1 "mag" => 4 "sonne" => 1 "vollmond" => 1 "die" => 2 "mit" => 1 "meer" => 1 "wenn" => 1 "und" => 2
It is clear that punctuation marks and words with capital letters will be separate units in the dictionary, which will interfere with a qualitative assessment of the frequency occurrences of the specific terms of our text, therefore we got rid of them. For the application of n-grams, it is easy to find many all kinds of interesting applications, for example, with their help you can carry out a fuzzy search in the text , well, since we are just tourists, we will do with toy examples, namely the generation of text using Markov chains
Procházení modelového grafu
A Markov chain is a discrete model of a Markov process consisting in a change in a system that takes into account only its (model) previous state. Figuratively speaking, one can perceive this construction as a probabilistic cellular automaton. N-grams quite get along with this concept: any word from the lexicon is associated with every other connection of different thickness, which is determined by the frequency of occurrence of specific pairs of words (grams) in the text.

Markov chain for string "ABABD"
The implementation of the algorithm itself is already a great activity for the evening, but Julia already has a wonderful Markovify package, which was created just for these purposes. After carefully scrolling through the manual in Czech , we proceed to our linguistic executions.
Breaking text into tokens (e.g. words)
using Markovify, Markovify.Tokenizer tokens = tokenize(str, on = words) 2-element Array{Array{String,1},1}: ["Ich", "mag", "die", "Sonne,", "die", "Palmen", "und", "das", "Meer,", "Ich", "mag", "den", "Himmel", "schauen,", "den", "Wolken", "hinterher."] ["Ich", "mag", "den", "kalten", "Mond,", "wenn", "der", "Vollmond", "rund,", "Und", "ich", "mag", "dich", "mit", "einem", "Knebel", "in", "dem", "Mund."]
We compose a first-order model (only the nearest neighbors are taken into account):
mdl = Model(tokens; order=1) Model{String}(1, Dict(["dich"] => Dict("mit" => 1),["den"] => Dict("Himmel" => 1,"kalten" => 1,"Wolken" => 1),["in"] => Dict("dem" => 1),["Palmen"] => Dict("und" => 1),["wenn"] => Dict("der" => 1),["rund,"] => Dict("Und" => 1),[:begin] => Dict("Ich" => 2),["Vollmond"] => Dict("rund," => 1),["die"] => Dict("Sonne," => 1,"Palmen" => 1),["kalten"] => Dict("Mond," => 1)…))
Then we proceed to implement the function of the generating phrase based on the provided model. It takes, in fact, a model, a workaround, and the number of phrases that you want to get:
function gensentences(model, fun, n) sentences = [] # Stop only after n sentences were generated # and passed through the length test while length(sentences) < n seq = fun(model) # Add the sentence to the array iff its length is ok if length(seq) > 3 && length(seq) < 20 push!(sentences, join(seq, " ")) end end sentences end
The developer of the package provided two bypass functions: walk
and walk2
(the second works longer, but gives more unique designs), and you can always determine your option. Let's try it:
gensentences(mdl, walk, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher." "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund." gensentences(mdl, walk2, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag dich mit einem Knebel in dem Mund." "Ich mag den Himmel schauen, den kalten Mond, wenn der Vollmond rund, Und ich mag den Wolken hinterher." "Ich mag die Sonne, die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund."
Of course, the temptation is great to try on Russian texts, especially on white verses. For the Russian language, due to its complexity, most of the phrases are unreadable. Plus, as already mentioned , special characters require special care, therefore we either save the documents from which the text encoded in UTF-8 is collected, or we use additional tools .
On the advice of his sister, after cleaning a couple of Oster’s books from special characters and any separators and setting a second order for n-grams, I got the following set of phraseological units:
", !" ". , : !" ", , , , ?" " !" ". , !" ". , ?" " , !" " ?" " , , ?" " ?" ", . ?"
She assured that it was precisely by such a technique that thoughts were constructed in the female brain ... ahem, and who am I to argue ...
Analyze it
In the directory of the TextAnalysis package you can find examples of textual data, one of which is a collection of speeches by American presidents before Congress

using TextAnalysis, Clustering, Plots#, MultivariateStats pth = "C:\\Users\\User\\.julia\\packages\\TextAnalysis\\pcFQf\\test\\data\\sotu" files = readdir(pth)
29-element Array{String,1}: "Bush_1989.txt" "Bush_1990.txt" "Bush_1991.txt" "Bush_1992.txt" "Bush_2001.txt" "Bush_2002.txt" "Bush_2003.txt" "Bush_2004.txt" "Bush_2005.txt" "Bush_2006.txt" "Bush_2007.txt" "Bush_2008.txt" "Clinton_1993.txt" ⋮ "Clinton_1998.txt" "Clinton_1999.txt" "Clinton_2000.txt" "Obama_2009.txt" "Obama_2010.txt" "Obama_2011.txt" "Obama_2012.txt" "Obama_2013.txt" "Obama_2014.txt" "Obama_2015.txt" "Obama_2016.txt" "Trump_2017.txt"
After reading these files and forming a corps from them, as well as cleaning it from punctuation, we will review the general vocabulary of all performances:
crps = DirectoryCorpus(pth) standardize!(crps, StringDocument) crps = Corpus(crps[1:29]);
remove_case!(crps) prepare!(crps, strip_punctuation) update_lexicon!(crps) update_inverse_index!(crps) lexicon(crps)
Dict{String,Int64} with 9078 entries: "enriching" => 1 "ferret" => 1 "offend" => 1 "enjoy" => 4 "limousines" => 1 "shouldn" => 21 "fight" => 85 "everywhere" => 17 "vigilance" => 4 "helping" => 62 "whose" => 22 "'" => 725 "manufacture" => 3 "sleepless" => 2 "favor" => 6 "incoherent" => 1 "parenting" => 2 "wrongful" => 1 "poised" => 3 "henry" => 3 "borders" => 30 "worship" => 3 "star" => 10 "strand" => 1 "rejoin" => 3 ⋮ => ⋮
It may be interesting to see in which documents there are specific words, for example, take a look at how we deal with promises:
crps["promise"]' 1×24 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 1 2 3 4 6 7 9 10 11 12 15 … 21 22 23 24 25 26 27 28 29 crps["reached"]' 1×7 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 12 14 15 17 19 20 22
or with pronoun frequencies:
lexical_frequency(crps, "i"), lexical_frequency(crps, "you") (0.010942182388035081, 0.005905479339070189)
So probably scientists and rape journalists and there is a perverse attitude towards the data being studied.
Matrices
Truly distributional semantics begins when texts, grams, and tokens turn into vectors and matrices .
A term document matrix ( DTM ) is a matrix that has a size where - the number of documents in the case, and - corpus dictionary size i.e. the number of words (unique) that are found in our corpus. In the i- th row, the j- th column of the matrix is a number - how many times in the i- th text the j- th word was found.
dtm1 = DocumentTermMatrix(crps)
D = dtm(dtm1, :dense) 29×9078 Array{Int64,2}: 0 0 1 4 0 0 0 0 0 0 0 0 0 … 1 0 0 16 0 0 0 0 0 0 0 1 4 0 0 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 3 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 5 8 0 0 0 0 0 0 0 0 0 0 0 0 10 38 0 0 0 0 0 3 0 0 0 0 0 0 0 0 5 0 … 0 0 0 22 0 0 0 0 0 0 0 12 4 2 0 0 0 0 0 1 3 0 0 0 0 41 0 0 0 0 0 0 0 1 1 2 1 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 44 0 0 0 0 0 0 0 2 1 1 0 0 0 0 0 0 2 0 0 0 67 0 0 14 1 1 31 2 0 8 2 1 1 0 0 0 0 0 4 0 … 0 0 0 50 0 0 0 0 0 2 0 3 3 0 2 0 0 0 0 0 2 1 0 0 0 11 0 0 0 0 0 0 0 8 3 6 3 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 1 11 5 3 3 0 0 0 1 0 1 0 1 0 0 44 0 0 0 0 0 0 0 11 5 4 5 0 0 0 0 0 1 0 1 0 0 48 0 0 0 0 0 0 0 18 6 8 4 0 0 0 0 0 0 1 1 0 0 80 0 0 0 0 0 0 0 1 2 0 0 0 0 0 0 0 0 0 … 0 0 0 26 0 0 0 0 0 1 0 4 5 5 1 0 0 0 0 0 1 0 0 0 45 0 0 0 0 0 1 1 0 8 2 1 3 0 0 0 0 0 2 0 0 0 47 0 0 170 11 11 1 0 0 7 1 1 1 0 0 0 0 0 0 0 0 0 3 2 0 208 2 2 0 1 0 5 2 0 1 1 0 0 0 0 1 0 0 0 41 0 0 122 7 7 1 0 0 4 3 4 1 0 0 0 0 0 0 0 … 0 0 62 0 0 173 11 11 7 2 0 6 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 3 0 3 0 0 0 0 0 0 0 0 0 0 0 35 0 0 0 0 0 1 0 2 2 0 2 0 0 0 0 0 1 0 0 0 0 30 0 0 0 0 0
Here the original units are terms
m.terms[3450:3465] 16-element Array{String,1}: "franklin" "frankly" "frankness" "fraud" "frayed" "fraying" "fre" "freak" "freddie" "free" "freed" "freedom" "freedoms" "freely" "freer" "frees"
Wait a moment ...
crps["freak"] 1-element Array{Int64,1}: 25 files[25] "Obama_2013.txt"
It will be necessary to read in more detail ...
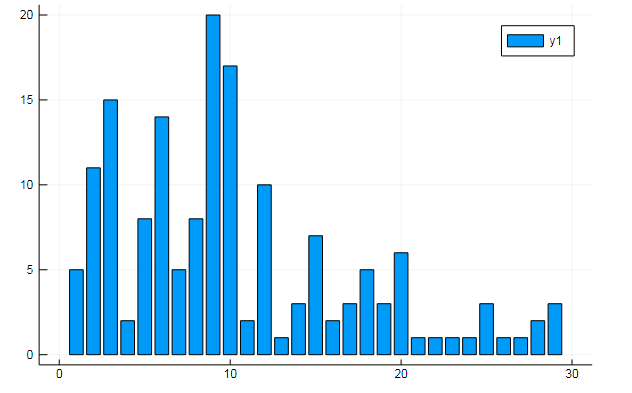
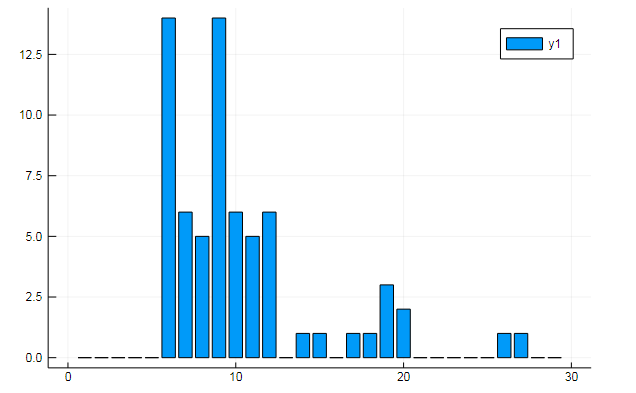
You can also extract all sorts of interesting data from the term matrices. Say the frequency of occurrence of specific words in documents
w1, w2 = dtm1.column_indices["freedom"], dtm1.column_indices["terror"] (3452, 8101)
D[:, w1] |> bar
D[:, w1] |> bar
or similarity of documents on some hidden topics:
k = 3 # iterations = 1000 # number of gibbs sampling iterations α = 0.1 # hyper parameter β = 0.1 # hyper parameter # Latent Dirichlet Allocation ϕ, θ = lda(m, k, iterations, α, β) # Latent Dirichlet Allocation plot(θ', line = 3)

The graphs show how each of the three topics is revealed in the speeches
or clustering words by topic, or for example, the similarity of vocabulary and the preference of certain topics in different documents
T = tf_idf(D) cl = kmeans(T, 5) # assign = assignments(cl) # clc = cl.centers # clsize = counts(cl) # 5-element Array{Int64,1}: 1 1784 36 1 7280
s1 = scatter(T[10, 1:10:end], assign, yaxis = "Bush 2006") s2 = scatter(T[29, 1:10:end], assign, yaxis = "Obama 2016") s3 = scatter(T[30, 1:10:end], assign, yaxis = "Trump 2017") plot(s1, s2, s3, layout = (3,1), legend=false )
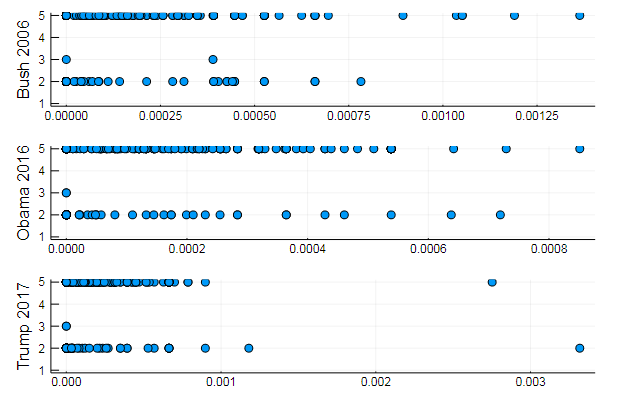
Quite natural results, performances of the same type. In fact, NLP is quite an interesting science, and you can extract a lot of useful information from correctly prepared data: you can find many examples on this resource ( Recognizing the author in the comments , using LDA , etc.)
Well, so as not to go far, we will generate phrases for the ideal president:
function loadfiles(filenames) return ( open(filename) do file text = read(file, String) # Tokenize on words (we could also tokenize on letters/lines etc.) # That means: split the text to sentences and then those sentences to words tokens = tokenize(text; on=letters) return Model(tokens; order=N) end for filename in filenames ) end pth = "C:\\Users\\User\\.julia\\packages\\TextAnalysis\\pcFQf\\test\\data\\sotu" FILENAMES = readdir(pth) N = 1 MODEL = combine(loadfiles(FILENAMES)...) gensentences(MODEL, walk2, 7)
7-element Array{Any,1}: "I want harmony and fathers, sons and we mark the jobkilling TransPacific Partnership." "I am asking all across our partners must be one very happy, indeed." "At the health insurance and terrorismrelated offenses since my Inauguration, and the future and pay their jobs, their community." "Millions lifted from this Nation, and Jessica Davis." "It will expand choice, increase access, lower the Director of our aspirations, not working." "We will defend our freedom." "The challenges we will celebrate the audience tonight, has come for a record."
Long short term memory
Well, how could it be without neural networks! They collect laurels in this field with increasing speed, and the environment of the Julia language contributes to this in every way. For the curious, you can advise the Knet package, which, unlike the Flux that we previously examined , does not work with neural network architectures as a constructor from modules, but for the most part works with iterators and streams. This can be of academic interest and contribute to a deeper understanding of the learning process, and also gives high performance computing. By clicking on the link provided above, you will find guidance, examples and material for self-study (for example, it shows how to create a Shakespearean text generator or juliac code on recurrent networks). However, some functions of the Knet package are implemented only for the GPU, so for now, let's continue to run around Flux.
- Examples performed using Flux - from markup in parts of speech to identifying emotional tonality
- RNN to Flux
- RNN in Knet
- Article about LSTM and the Russian version
- TPU nets
One of the typical examples of the operation of recurrence networks is often the model that Shakespeare’s sonnets are fed symbolically:
QUEN: Chiet? The buswievest by his seld me not report. Good eurronish too in me will lide upon the name; Nor pain eat, comes, like my nature is night. GRUMIO: What for the Patrople: While Antony ere the madable sut killing! I think, bull call. I have what is that from the mock of France: Then, let me? CAMILLE: Who! we break be what you known, shade well? PRINCE HOTHEM: If I kiss my go reas, if he will leave; which my king myself. BENEDICH: The aunest hathing rouman can as? Come, my arms and haste. This weal the humens? Come sifen, shall as some best smine? You would hain to all make on, That that herself: whom will you come, lords and lafe to overwark the could king to me, My shall it foul thou art not from her. A time he must seep ablies in the genely sunsition. BEATIAR: When hitherdin: so like it be vannen-brother; straight Edwolk, Wholimus'd you ainly. DUVERT: And do, still ene holy break the what, govy. Servant: I fearesed, Anto joy? Is it do this sweet lord Caesar: The dece
If you squint and do not know English, then the play seems quite real .

It's easier to understand in Russian
But it’s much more interesting to try on the great and powerful, and although it is lexically very difficult, you can use more primitive literature as data, namely, more recently known as the avant-garde current of modern poetry - rhyme-pies.
Data collection
Pies and powders - rhythmic quatrains, often without rhyme, typed in lower case and without punctuation marks.
The choice fell on the site poetory.ru on which admin comrade hior . The long lack of response to the request for data was the reason for starting to study site parsing. A quick look at the HTML tutorial gives you a rudimentary understanding of the design of web pages. Next, we find the means of the Julia language for working in such areas:
- HTTP.jl - HTTP client and server functionality for Julia
- Gumbo.jl - parsing html-layouts and not only
- Cascadia.jl - Gumbo Support Package

Then we implement a script that flips through the pages of the poetry and saves the pies into a text document:
using HTTP, Gumbo, Cascadia function grabit(npages) str = "" for i = 1:npages url = "https://poetory.ru/por/rating/$i" # https://poetory.ru/pir/rating/$i res = HTTP.get(url) body1 = String(res.body) htmlka = parsehtml(body1) qres = eachmatch(sel".item-text", htmlka.root) for elem in qres str *= (elem[1].text * "\n\n") end print(i, ' ') end f = open("poroh.txt","w") write(f, str) close(f) end grabit(30)
In more detail, it is disassembled in a Jupiter notebook . Let's collect the pies and gunpowder in a single line:
str = read("pies.txt", String) * read("poroh.txt", String); length(str) # 7092659
And look at the alphabet used:
prod(sort([unique(str)..., '_']) ) # "\n !\"#\$&'()*+,-./012345678:<>?@ABCDEFGHIKLMNOPQRSTUV[]^__abcdefghijklmnopqrstuvwxyz«\uad°º»¾¿ÐÑßàáãäåæçèéêëìíîðñóõöùûüýþÿıņōŏƍǝǹɐɓɔɯɹʁʎʚʞ́εєіїўѣҺאבהוחטיךלםמעףצקרשתئاةتجدرزسعكلمنهوپچڑکگںھہیے \u200b–—…€║╛╨█□ \ufeff"

Check the downloaded data before starting the process.
Ay-ah-ah, what a disgrace! Some users break the rules (sometimes people just express themselves by making noise in these data). So we will clean our symbol case from garbage
str = lowercase(str) # # str = replace(str, r"|" => s"" ); trash = "!\"#\$&'()*+,-./012345678:<>?@ABCDEFGHIKLMNOPQRSTUV[]^__abcdefghijklmnopqrstuvwxyz«\uad°º»¾¿ÐÑßàáãäåæçèéêëìíîðñóõöùûüýþÿıņōŏƍǝǹɐɓɔɯɹʁʎʚʞ́εєіїўѣһҺאבהוחטיךלםמעףצקרשתئاةتجدرزسعكلمنهوپچڑکگںھہیے\u200b–—…€║╛╨█□\ufeff" for c in collect(trash) str = replace(str, c => ""); end for c in " " str = replace(str, c => " "); end alstr = str |> unique |> sort |> prod #alstr = prod(sort(unique(str)) ) # # "\n "
$ & '() * +, - / str = lowercase(str) # # str = replace(str, r"|" => s"" ); trash = "!\"#\$&'()*+,-./012345678:<>?@ABCDEFGHIKLMNOPQRSTUV[]^__abcdefghijklmnopqrstuvwxyz«\uad°º»¾¿ÐÑßàáãäåæçèéêëìíîðñóõöùûüýþÿıņōŏƍǝǹɐɓɔɯɹʁʎʚʞ́εєіїўѣһҺאבהוחטיךלםמעףצקרשתئاةتجدرزسعكلمنهوپچڑکگںھہیے\u200b–—…€║╛╨█□\ufeff" for c in collect(trash) str = replace(str, c => ""); end for c in " " str = replace(str, c => " "); end alstr = str |> unique |> sort |> prod #alstr = prod(sort(unique(str)) ) # # "\n "
^ __ abcdefghijklmnopqrstuvwxyz «\ uad ° º» str = lowercase(str) # # str = replace(str, r"|" => s"" ); trash = "!\"#\$&'()*+,-./012345678:<>?@ABCDEFGHIKLMNOPQRSTUV[]^__abcdefghijklmnopqrstuvwxyz«\uad°º»¾¿ÐÑßàáãäåæçèéêëìíîðñóõöùûüýþÿıņōŏƍǝǹɐɓɔɯɹʁʎʚʞ́εєіїўѣһҺאבהוחטיךלםמעףצקרשתئاةتجدرزسعكلمنهوپچڑکگںھہیے\u200b–—…€║╛╨█□\ufeff" for c in collect(trash) str = replace(str, c => ""); end for c in " " str = replace(str, c => " "); end alstr = str |> unique |> sort |> prod #alstr = prod(sort(unique(str)) ) # # "\n "
? str = lowercase(str) # # str = replace(str, r"|" => s"" ); trash = "!\"#\$&'()*+,-./012345678:<>?@ABCDEFGHIKLMNOPQRSTUV[]^__abcdefghijklmnopqrstuvwxyz«\uad°º»¾¿ÐÑßàáãäåæçèéêëìíîðñóõöùûüýþÿıņōŏƍǝǹɐɓɔɯɹʁʎʚʞ́εєіїўѣһҺאבהוחטיךלםמעףצקרשתئاةتجدرزسعكلمنهوپچڑکگںھہیے\u200b–—…€║╛╨█□\ufeff" for c in collect(trash) str = replace(str, c => ""); end for c in " " str = replace(str, c => " "); end alstr = str |> unique |> sort |> prod #alstr = prod(sort(unique(str)) ) # # "\n "
Got a more acceptable character set. The biggest revelation of today is that, from the point of view of machine code, there are at least three different spaces - it’s hard for data hunters to live.

Now you can connect Flux with the subsequent presentation of data as onehot vectors:
using Flux using Flux: onehot, chunk, batchseq, throttle, crossentropy using StatsBase: wsample using Base.Iterators: partition texta = collect(str) println(length(texta)) # 7086899 alphabet = [unique(texta)..., '_'] texta = map(ch -> onehot(ch, alphabet), texta) stopa = onehot('_', alphabet) println(length(alphabet)) # 34 N = length(alphabet) seqlen = 128 nbatch = 128 Xs = collect(partition(batchseq(chunk(texta, nbatch), stopa), seqlen)) Ys = collect(partition(batchseq(chunk(texta[2:end], nbatch), stopa), seqlen));
We set the model from a couple of LSTM layers, a fully connected perceptron and softmax, as well as everyday little things, and for the loss function and the optimizer:
m = Chain( LSTM(N, 256), LSTM(256, 128), Dense(128, N), softmax) # m = gpu(m) function loss(xs, ys) l = sum(crossentropy.(m.(gpu.(xs)), gpu.(ys))) Flux.truncate!(m) return l end opt = ADAM(0.01) tx, ty = (Xs[5], Ys[5]) evalcb = () -> @show loss(tx, ty)
The model is ready for training, so by running the line below, you can go about your own business, the cost of which is selected in accordance with the power of your computer. In my case, these are two lectures on philosophy, which, for some damn thing, were delivered to us late at night ...
@time Flux.train!(loss, params(m), zip(Xs, Ys), opt, cb = throttle(evalcb, 30))
Having assembled a sample generator, you can begin to reap the benefits of your labors.
function sample(m, alphabet, len) #m = cpu(m) Flux.reset!(m) buf = IOBuffer() c = rand(alphabet) for i = 1:len write(buf, c) c = wsample(alphabet, m( onehot(c, alphabet) ).data ) end return String(take!(buf)) end sample(m, alphabet, 1000) |> println
Slight disappointment due to slightly higher expectations. Although the network has only a sequence of characters at the input and can only operate with the frequencies of their meeting one after another, it completely caught the structure of the data set, singled out some semblance of words, and in some cases even showed the ability to maintain rhythm. Possibly, identification of semantic affinity will help in improving.

The weights of a trained network can be saved to disk, and then easily read
weights = Tracker.data.(params(model)); using BSON: @save # https://github.com/JuliaIO/BSON.jl @save "Pies_34x128.bson" weights # : using BSON: @load @load "mymodel1.bson" weights Flux.loadparams!(m, weights)
With prose, too, only abstract cyber psychedelia comes out. There have been attempts to improve the quality of the width and depth of the network, as well as the diversity and abundance of data. For the given text corps, special thanks to the greatest popularizer of the Russian language

! . ? , , , , , , , , . , , , , . , . ? , , , , , ,
But if you train a neural network on the source code of the Julia language, then it comes out pretty cool:
# optional _ = Expr(expMreadcos, Expr(:meta, :stderr), :n, :default, ex, context[oeex, ex.args[1] -typeinfo + Int]) isprint((v), GotoNode(e)) end for (fname, getfield) do t print(io, ":") new() end end if option quote bounds end end @sprintf("Other prompt", ex.field, UV_REQ) == pop!(bb_start_off+1, i) write(io, take!(builder_path)) end Base.:Table(io::IOContext) = write(io, position(s)) function const_rerror(pre::GlobalRef) ret = proty(d) if !rel_key && length(blk) return htstarted_keys(terminal(u, p)) end write(io, ("\\\\" => "\n\n\n\n") ? "<username>\n>\n" p = empty(dir+stdout) n = MD(count_ok_new_data(L) : n_power while push!(blks[$ur], altbuf) end function prec_uninitual(p, keep='\n') print(io, "1 2") else p = blk + p0 out = Mair(1) elseif occursin(".cmd", keep=ks) != 0 res = write(io, c) end while take!(word)
Added to this the possibility of metaprogramming , we get a program that writes and executes, maybe even our own, code! Well, or it will be a godsend for movie designers about hackers .
In general, the beginning has been made, and then already as the fantasy indicates. Firstly, you should get high-quality equipment so that long calculations do not stifle the desire to experiment. Secondly, we need to study methods and heuristics more deeply, which will allow us to construct better and more optimized models. On this resource, it’s enough to find everything related to Natural Language Processing, after which it is quite possible to teach your neural network how to generate poetry or go to a hackathon for text analysis .
On this, let me take my leave.Data for training in the cloud , listings on the github , fire in the eyes, an egg in a duck, and good night everyone!