
My main job is, for the most part, the deployment of software systems, that is, I spend a lot of time trying to answer these questions:
- This software works for a developer, but not for me. Why?
- Yesterday this software worked for me, but not today. Why?
This is a kind of debugging that is slightly different from regular software debugging. Normal debugging is about code logic, but deployment debugging is about code and environment interaction. Even if the root of the problem is a logical mistake, the fact that everything works on one machine and not on another means that the matter is somehow in the environment.
Therefore, instead of the usual debugging tools like gdb , I have a different set of debugging tools for deployment. And my favorite tool for dealing with a problem like "Why doesn’t it plow this software?" called strace .
What is strace?
strace is a tool for tracing a system call. Initially created under Linux, but the same debugging chips can be rotated with tools for other systems ( DTrace or ktrace ).
The main application is very simple. You just need to run strace with any command and it will send all system calls to the dump (though, first, you probably have to install strace itself):
$ strace echo Hello ...Snip lots of stuff... write(1, "Hello\n", 6) = 6 close(1) = 0 close(2) = 0 exit_group(0) = ? +++ exited with 0 +++
What are these system calls? It is a kind of API for the kernel of the operating system. Once upon a time, the software had direct access to the hardware on which it worked. If, for example, you had to display something on the screen, it played with ports and / or memory registers for video devices. When multitasking computer systems became popular, chaos reigned because various applications fought for hardware. Errors in one application could bring down the work of others, if not the entire system. Then privilege modes (or "ring protection") appeared in the CPU. The kernel became the most privileged: it received full access to the hardware, creating less privileged applications that already had to request access from the kernel to interact with the hardware through system calls.
At the binary level, a system call is slightly different from a simple function call, however most programs use a wrapper in the standard library. Those. the POSIX C standard library contains a call to the write () function, which contains all architecture-specific code for the write system call.
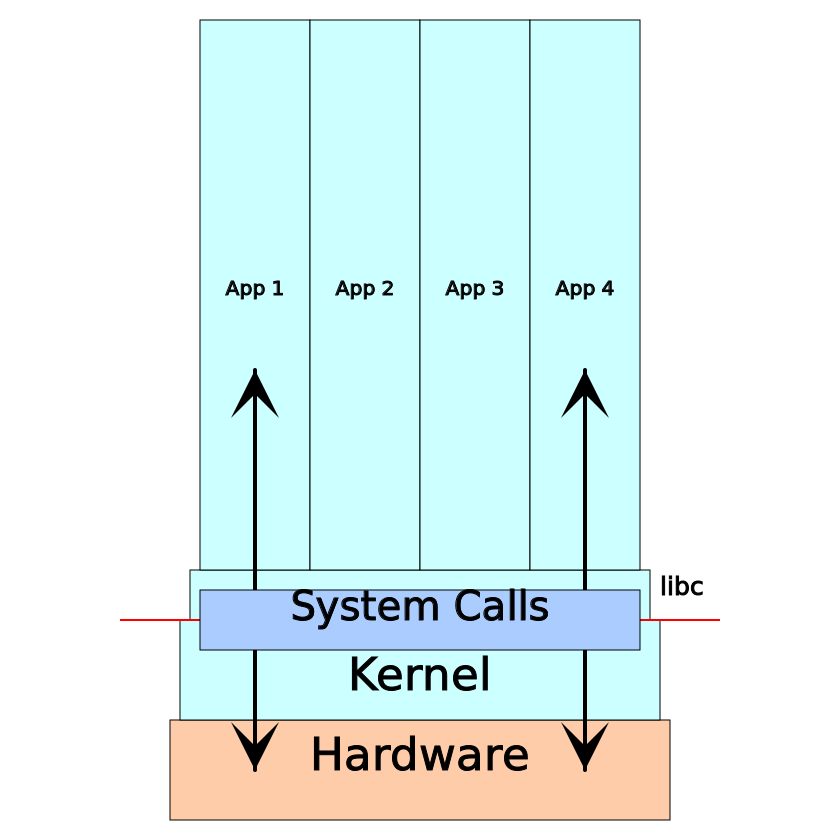
In short, any interaction between the application and its environment (computer systems) is carried out through system calls. Therefore, when the software works on one machine and not on another, it would be nice to look at the results of tracing system calls. More specifically, here is a list of typical points that can be analyzed using system call tracing:
- Console I / O
- Network input / output
- File System Access and File I / O
- Process / thread lifetime management
- Low level memory management
- Access to specific device drivers
When to use strace?
In theory, strace is used with any programs in user space, because any program in user space should make system calls. It works more efficiently with compiled, low-level programs, but it also works with high-level languages like Python if you can get through the extra noise from the runtime and the interpreter.
In all its splendor, strace manifests itself during debugging of software that works well on one machine, and suddenly stops working on another, giving slurred messages about files, permissions or unsuccessful attempts to execute some commands or something ... It's a pity, but not so good it is combined with high-level issues like certificate validation error. This usually requires a combination of strace , sometimes ltrace, and higher-level tools (like the openssl command-line tool for debugging a certificate).
For example, we take work on a stand-alone server, but tracing system calls can often be performed on more complex deployment platforms. You just need to choose the right toolkit.
Simple Debugging Example
Let's say you want to run the awesome foo server application, but this is what you get:
$ foo Error opening configuration file: No such file or directory
Obviously, he could not find the configuration file you wrote. This happens because sometimes, when package managers compile an application, they override the expected location of the files. And if you follow the installation guide for one distribution kit, in another you find the files completely not where I expected. It would be possible to solve the problem in a couple of seconds if the error message said where to look for the configuration file, but it does not say. So where to look?
If you have access to the source code, you can read it and find out. A good backup plan, but not the fastest solution. You can resort to a step-by-step debugger like gdb and see what the program does, but it’s much more efficient to use a tool that is specially designed to show interaction with the environment: strace .
The conclusion of strace may seem redundant, but the good news is that most of it can be safely ignored. It is often useful to use the -o operator to save trace results to a separate file:
$ strace -o /tmp/trace foo Error opening configuration file: No such file or directory $ cat /tmp/trace execve("foo", ["foo"], 0x7ffce98dc010 /* 16 vars */) = 0 brk(NULL) = 0x56363b3fb000 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=25186, ...}) = 0 mmap(NULL, 25186, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f2f12cf1000 close(3) = 0 openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3 read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\260A\2\0\0\0\0\0"..., 832) = 832 fstat(3, {st_mode=S_IFREG|0755, st_size=1824496, ...}) = 0 mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2f12cef000 mmap(NULL, 1837056, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f2f12b2e000 mprotect(0x7f2f12b50000, 1658880, PROT_NONE) = 0 mmap(0x7f2f12b50000, 1343488, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x22000) = 0x7f2f12b50000 mmap(0x7f2f12c98000, 311296, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x16a000) = 0x7f2f12c98000 mmap(0x7f2f12ce5000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1b6000) = 0x7f2f12ce5000 mmap(0x7f2f12ceb000, 14336, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f2f12ceb000 close(3) = 0 arch_prctl(ARCH_SET_FS, 0x7f2f12cf0500) = 0 mprotect(0x7f2f12ce5000, 16384, PROT_READ) = 0 mprotect(0x56363b08b000, 4096, PROT_READ) = 0 mprotect(0x7f2f12d1f000, 4096, PROT_READ) = 0 munmap(0x7f2f12cf1000, 25186) = 0 openat(AT_FDCWD, "/etc/foo/config.json", O_RDONLY) = -1 ENOENT (No such file or directory) dup(2) = 3 fcntl(3, F_GETFL) = 0x2 (flags O_RDWR) brk(NULL) = 0x56363b3fb000 brk(0x56363b41c000) = 0x56363b41c000 fstat(3, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x8), ...}) = 0 write(3, "Error opening configuration file"..., 60) = 60 close(3) = 0 exit_group(1) = ? +++ exited with 1 +++
About the entire first page of strace output is usually a low-level preparation for launch. (There are many mmap , mprotect , brk calls for things like detecting low-level memory and displaying dynamic libraries.) In fact, during debugging, strace outputs are best read from the very end. At the bottom is a call to write , which displays an error message. We look above and see the first erroneous system call - an openat call that throws an ENOENT error ("file or directory not found"), trying to open /etc/foo/config.json . Here, here the configuration file should lie.
It was just an example, but I would say that 90% of the time that I use strace , nothing is much more difficult to do and does not have to. Below is a complete step-by-step debugging guide:
- Frustrated by a slurred system-y error message from a program
- Restart the program with strace
- Find error message in trace results
- Go higher until you bump into the first failed system call
It is very likely that the system call in step 4 will show what went wrong.
Tips
Before showing an example of more complex debugging, I’ll tell you a few tricks for using strace effectively:
man is your friend
On many * nix systems, a complete list of kernel system calls can be obtained by running man syscalls . You will see things like brk (2) , which means you can get more information by running man 2 brk .
Small rake: man 2 fork shows me a page for the fork () shell in GNU libc , which turns out to be implemented using the clone () call. The semantics of the fork call remain the same if you write a program that uses fork () and start tracing - I will not find fork calls, instead of them there will be clone () . Such a rake is only confused if you start comparing the source with the output of strace .
Use -o to save the output to a file
strace can generate extensive output, so it is often useful to store trace results in separate files (as in the example above). And it helps not to confuse program output with strace output in the console.
Use -s to view more argument data
You probably noticed that the second half of the error message is not shown in the above trace example. This is because strace only shows the first 32 bytes of the string argument by default. If you want to see more, add something like -s 128 to the strace call.
-y facilitates tracking files \ sockets \ and so on.
“Everything is a file” means that * nix systems perform all I / O using file descriptors, whether it applies specifically to a file or network, or to interprocess channels. This is convenient for programming, but it makes it difficult to keep track of what actually happens when you see the general read and write in the trace results of a system call.
By adding the -u operator, you force strace to annotate each file descriptor in the output with a note of what it points to.
Attach to an already running process with -p **
As will be seen from the example below, sometimes you need to trace a program that is already running. If you know that it is running as process 1337 (say, from the conclusions of ps ), then you can trace it like this:
$ strace -p 1337 ...system call trace output...
Perhaps you need root privileges.
Use -f to keep track of child processes
strace by default traces only one process. If this process spawns child processes, then you can see the system call to spawn the child process, but the system calls of the child process will not be displayed.
If you think that the error is in the child process, use the -f operator, this will enable its tracing. The downside of this is that the conclusion will confuse you even more. When strace traces one process or one thread, it shows a single stream of call events. When it traces several processes at once, then you will probably see the beginning of the call interrupted by the <unfinished ...> message, then a bunch of calls for other execution branches, and only then the end of the first with <... foocall resumed> . Or, separate all the trace results into different files using the -ff operator as well ( see the strace manual for details).
Filter the trace with -e
As you can see, the trace result is a real bunch of all possible system calls. With the -e flag, you can filter the trace (see strace manual ). The main advantage is that running trace with filtering is faster than doing a full trace, and then grep . To be honest, I almost always don't care.
Not all mistakes are bad
A simple and common example is a program looking for a file in several places at once, like a shell looking for, in which the basket / directory contains an executable file:
$ strace sh -c uname ... stat("/home/user/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory) stat("/usr/local/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory) stat("/usr/bin/uname", {st_mode=S_IFREG|0755, st_size=39584, ...}) = 0 ...
A “last failed request before error message” heuristic is good at finding relevant errors. Be that as it may, it is logical to start from the very end.
C Programming Guides Help Understand System Calls
Standard calls to C libraries are not system calls, but only a thin surface layer. So, if you understand at least a little how and what to do in C, it will be easier for you to understand the results of tracing a system call. For example, if you have trouble debugging calls to networked systems, check out the same classic Bij's "Network Programming Guide" .
More complicated debugging example
I have already said that an example of simple debugging is an example of something with which, for the most part, I have to deal with strace . However, sometimes a real investigation is required, so here's a real example of debugging more complicated.
bcron is a task processing scheduler, another implementation of the * nix cron daemon . It is installed on the server, but when someone tries to edit the schedule, this is what happens:
# crontab -e -u logs bcrontab: Fatal: Could not create temporary file
Okay, so bcron tried to write a certain file, but it didn’t work out and he doesn’t admit why. Uncover strace :
# strace -o /tmp/trace crontab -e -u logs bcrontab: Fatal: Could not create temporary file # cat /tmp/trace ... openat(AT_FDCWD, "bcrontab.14779.1573691864.847933", O_RDONLY) = 3 mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000 read(3, "#Ansible: logsagg\n20 14 * * * lo"..., 8192) = 150 read(3, "", 8192) = 0 munmap(0x7f82049b4000, 8192) = 0 close(3) = 0 socket(AF_UNIX, SOCK_STREAM, 0) = 3 connect(3, {sa_family=AF_UNIX, sun_path="/var/run/bcron-spool"}, 110) = 0 mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000 write(3, "156:Slogs\0#Ansible: logsagg\n20 1"..., 161) = 161 read(3, "32:ZCould not create temporary f"..., 8192) = 36 munmap(0x7f82049b4000, 8192) = 0 close(3) = 0 write(2, "bcrontab: Fatal: Could not creat"..., 49) = 49 unlink("bcrontab.14779.1573691864.847933") = 0 exit_group(111) = ? +++ exited with 111 +++
At the very end, there is a write error message, but this time something is different. Firstly, there is no relevant system call error that usually occurs before this. Secondly, it is clear that somewhere someone has already read the error message. It seems like the real problem is somewhere else, and bcrontab just plays the message.
If you look at man 2 read , you can see that the first argument (3) is the file descriptor that * nix uses for all I / O processing. How to find out what file descriptor 3 represents? In this particular case, you can run strace with the -u operator (see above), and it will automatically tell you, however, in order to calculate such things, it is useful to know how to read and analyze the trace results.
The source of the file descriptor can be one of many system calls (it all depends on what the descriptor is for the console, network socket, the file itself, or something else), but be that as it may, we are looking for calls returning 3 (t .e. look for "= 3" in the trace results). As a result, there are 2 of them: openat at the very top and socket in the middle. openat opens the file, but close (3) after that will show that it closes again. (Rake: file descriptors can be reused when they open and close). The socket () call is suitable, since it is the last before read () , and it turns out that bcrontab works with something through the socket. The next line shows that the file descriptor is associated with the unix domain socket along the path / var / run / bcron-spool .
So, you need to find the process attached to the unix socket on the other hand. There are a couple of nifty tricks for this purpose, and both come in handy for debugging server deployments. The first is to use netstat or newer ss (socket status). Both commands show the active network connections of the system and take the -l operator to describe listening sockets, and the -p operator to display programs connected to the socket as a client. (There are many more useful options, but these two are enough for this task.)
# ss -pl | grep /var/run/bcron-spool u_str LISTEN 0 128 /var/run/bcron-spool 1466637 * 0 users:(("unixserver",pid=20629,fd=3))
This suggests that the listener is an inixserver command that works with process ID 20629. (And, coincidentally, it uses file descriptor 3 as a socket.)
The second really useful tool for finding the same information is called lsof . It lists all open files (or file descriptors) in the system. Or you can get information about one specific file:
# lsof /var/run/bcron-spool COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME unixserve 20629 cron 3u unix 0x000000005ac4bd83 0t0 1466637 /var/run/bcron-spool type=STREAM
The 20629 process is a long-lived server, so you can attach strace to it using something like strace -o / tmp / trace -p 20629 . If we edit the cron task in another terminal, we get the output of the trace results with an error. And here is the result:
accept(3, NULL, NULL) = 4 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21181 close(4) = 0 accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set) --- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21181, si_uid=998, si_status=0, si_utime=0, si_stime=0} --- wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 0}], WNOHANG|WSTOPPED, NULL) = 21181 wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes) rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0 rt_sigreturn({mask=[]}) = 43 accept(3, NULL, NULL) = 4 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21200 close(4) = 0 accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set) --- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21200, si_uid=998, si_status=111, si_utime=0, si_stime=0} --- wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 111}], WNOHANG|WSTOPPED, NULL) = 21200 wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes) rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0 rt_sigreturn({mask=[]}) = 43 accept(3, NULL, NULL
(The last accept () will not be completed when tracing.) And again, sadly, this result does not contain the error we are looking for. We do not see any messages that bcrontag would send to or receive from a socket. Instead, complete control of the process ( clone , wait4 , SIGCHLD , etc.) This process spawns a child process, which, as you might guess, does the real work. And if you need to catch her trace, add strace -f to the call. Here's what we find by looking for the error message in the new result with strace -f -o / tmp / trace -p 20629 :
21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied) 21470 write(1, "32:ZCould not create temporary f"..., 36) = 36 21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84 21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory) 21470 exit_group(111) = ? 21470 +++ exited with 111 +++
Now, this is something. Process 21470 receives an "access denied" error when trying to create a file on the path tmp / spool.21470.1573692319.854640 (referring to the current working directory). If we just knew the current working directory, we would have known the full path and could figure out why the process cannot create its own temporary file in it. Unfortunately, the process has already exited, so you can’t just use lsof -p 21470 to find the current directory, but you can work in the opposite direction - look for PID 21470 system calls that change the directory. (If there are none, PID 21470 must have inherited them from the parent, and this cannot be figured out through lsof -p .) This system call is chdir (which is easy to find out with the help of modern network search engines). And here is the result of reverse searches based on the trace results, up to the PID 20629 server itself:
20629 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21470 ... 21470 execve("/usr/sbin/bcron-spool", ["bcron-spool"], 0x55d2460807e0 /* 27 vars */) = 0 ... 21470 chdir("/var/spool/cron") = 0 ... 21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied) 21470 write(1, "32:ZCould not create temporary f"..., 36) = 36 21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84 21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory) 21470 exit_group(111) = ? 21470 +++ exited with 111 +++
(If you get lost, you might want to read my previous post on * nix process control and shells .) So, the PID 20629 server did not get permission to create a file along the path /var/spool/cron/tmp/spool.21470.1573692319.854640 . Most likely, the reason for this is the classic file system permission settings. Check:
# ls -ld /var/spool/cron/tmp/ drwxr-xr-x 2 root root 4096 Nov 6 05:33 /var/spool/cron/tmp/ # ps u -p 20629 USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND cron 20629 0.0 0.0 2276 752 ? Ss Nov14 0:00 unixserver -U /var/run/bcron-spool -- bcron-spool
! cron, root /var/spool/cron/tmp/ . chown cron /var/spool/cron/tmp/ bcron . ( , — SELinux AppArmor, dmesg .)
Total
, , , , — . , bcron , .
, , , strace , , . , strace . , .