
It is difficult to organize the joint work of a large team, especially on a common code base, such as Shopify. Our monolith changes 40 times a day. We track development in a trunk-based workflow and pour 400 commits into the master daily. We have three rules for a safe deployment, but with the development scale, it became increasingly difficult to comply with them. Small conflicts broke the main branch, slow deployments widened the gap between it and production, and the deployment speed of critical changes slowed down due to lag pool requests. To solve these problems, we updated Merge Queue (our tool for automating and controlling the speed of merges in the main branch). Now it is integrated with GitHub, starts continuous integration (CI) before merging with the main branch, deletes requests that are not included in the CI, and increases the speed of deployment.
Our three basic rules for safe deployment and maintenance of the main branch (masters):
- The wizard must always be green (via CI) so that it is possible to deploy from it at any time. Green master - this means that the main branch is always successfully compiled and goes through all the stages of assembly. Otherwise, developers cannot inject changes into the branch, slowing down the process throughout the company.
- The master should be close to production . Going too far ahead increases the risks.
- Emergency mergers should be fast . In the event of an emergency, we should be able to make corrections quickly.
Merge Queue v1
Two years ago, we rolled out the first iteration of the queue in our open-source Shipit continuous deployment tool . Our goal was to prevent the main branch from going too far from production. Instead of directly merging with the master, developers add pool requests to the Merge Queue on their behalf.

Merge Queue v1
Pool requests do not merge immediately with the main branch, but accumulate in the queue. Merge Queue v1 controlled the size of the queue and prevented merging when the wizard had too many changes that had not yet been rolled out in production. This reduced the risk of crashes and possible production lag. During incidents, we blocked the queue, providing space for emergency fixes.
Browser extension Merge Queue v1
Through the browser extension Merge Queue v1, developers sent pool requests to the merge queue in the GitHub interface. It also made it possible to quickly roll corrections during emergencies, bypassing the queue.
Problems with Merge Queue v1
Merge Queue v1 tracked pool requests, but the CI system did not work on the pool requests that are in the queue. On some unlucky days — when incidents had to suspend deployments — more than 50 pool requests were piling up in the merger queue. Combining and deploying a queue of this size can take several hours. There is also no guarantee that the pool request in the queue will go through the CI after merging with the main branch, since there may be soft conflicts between requests in the queue (two independent pool requests go through the CI separately, but not together).
The main headache was the browser extension. New developers sometimes forgot to install it, sometimes they merged directly to the main branch instead of sending the pool request to the queue. This threatened with devastating consequences if the deployment was already far behind or the queue was paused due to the incident.
Merge Queue v2
This year we released the second version of the queue - Merge Queue v2. We focused on optimizing throughput by reducing queue downtime and improving the UI, replacing the browser extension with a more integrated interface. We also wanted to solve problems that we could not solve with the previous version of the system: to keep the wizard green and faster to roll emergency fixes. In addition, our solution was to withstand untrustworthy tests that fail with unpredictable results.
Opt out of browser extension
Merge Queue v2 implemented a new interface. I wanted it to be intuitive to developers familiar with GitHub. We drew inspiration from the Atlantis system that we already used in our Terraform installation and made a comment-based interface.
Merge Queue v2 with Comment Based Interface
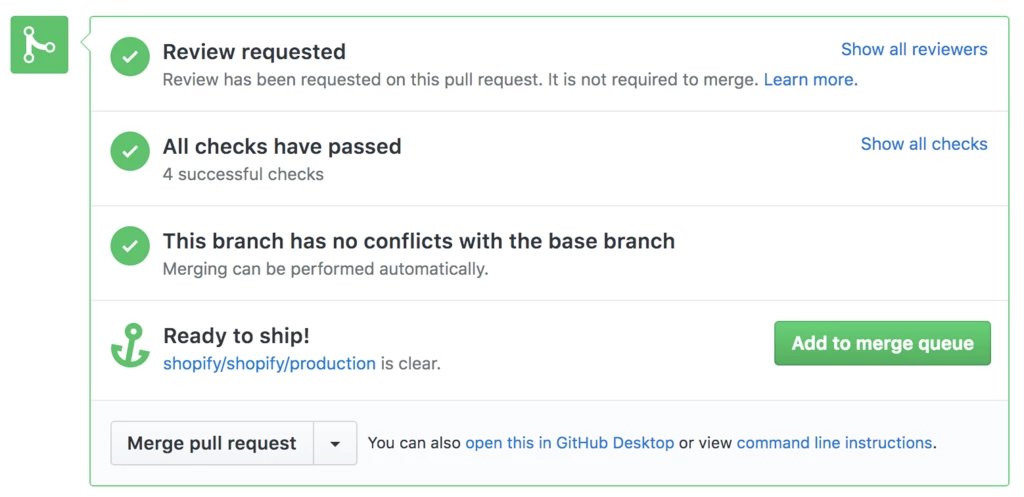
A welcome message with instructions for using the merge queue is issued for each pool request. Each merge now begins with a
/shipit
. He sends a web hook to our system, reporting a new pool request. We verify that the pool request has passed the CI and is approved by the reviewer before adding it to the queue. If successful, this comment is answered with a positive emoji through addReaction from GitHub GraphQL .
addReaction(input: { subjectId: $comment_id content: thumbs_up })
Other pool request comments report errors, such as an invalid branch or missing reviews.
addComment(input: { subjectId: $pr_id body: $error_message })
Merging directly into the master bypassing the queue reduces overall throughput, so we programmatically disabled the ability to merge directly into the master using the GitHub branch protection feature, which is part of the queue integration process.
createBranchProtectionRule(input: { repositoryId: $repository_id pattern: 'master' # This is how we disable to merge pull request button for non-admins. restrictsPushes: true # Admins should be able to use the merge button in case merge queue is broken # The app also depends on this to merge directly in emergencies isAdminEnforced: false })
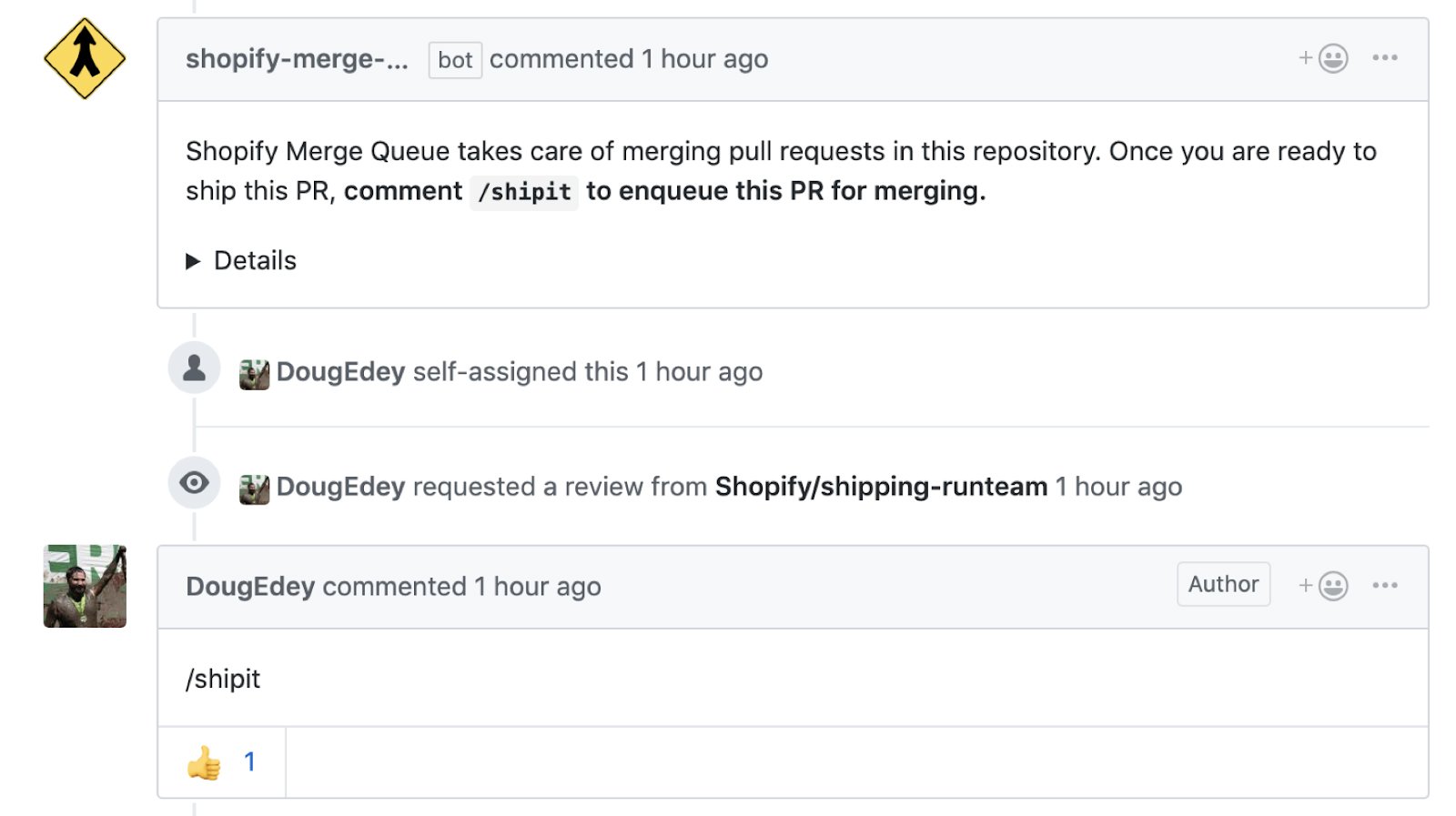
However, we still need the possibility of direct mergers bypassing the queue when an emergency occurs. For these cases, we added a separate command
/shipit --emergency
, which blocks any checks, and the code flows directly into the master. This helps to convey to the developers that direct mergers are reserved only for emergencies, and we have the opportunity to check each such pool request.
Keep the main branch green
To keep the main branch green, we once again looked at how and when we make changes to it. If we run CI before merging into the master, then we guarantee merging only green changes. This improves the quality of local development by eliminating the number of calls to the broken master and speeding up the deployment without worrying about delays due to unsuccessful builds.
Here we decided to create the so-called “predictive branch”, where pool requests are combined and CI is launched. This is a possible future version of the wizard, however this branch can still be freely manipulated. We avoid the local checkout so as not to support a stateful system and risk synchronization, and instead interact with this branch through the GraphQL GitHub API.
To ensure that the predictive branch on GitHub is consistent with our desired state, we use a template similar to React's Virtual DOM . The system creates a representation of the desired state in the memory and runs the matching algorithm we developed, which performs the necessary mutations into the state on GitHub. The reconciliation algorithm synchronizes our desired state with GitHub in two steps. The first step is to discard the deprecated merge commits. These are commits created in the past that are no longer needed for the desired state of the tree. The second step is to create the missing merge commits. Once they are created, a corresponding CI launch is initiated.
This scheme allows you to freely change the desired state when changing the queue and is resistant to desynchronization.
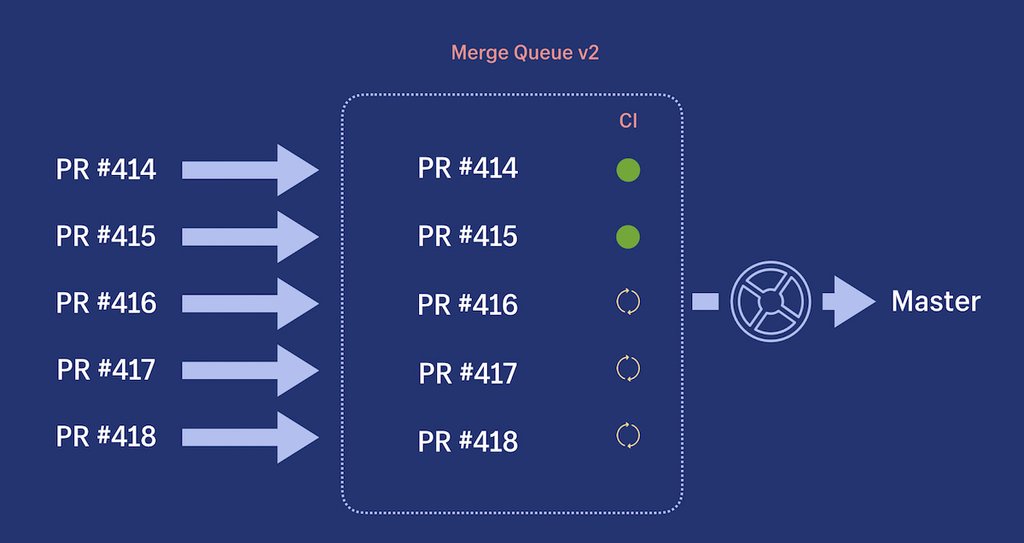
Merge Queue v2 launches CI on commit queue
To keep the main branch in a ready state (green), you also need to remove from the queue pool requests that do not pass CI to prevent cascading failures for subsequent pool requests. However, our main monolith Shopify, like many other large codebases, suffers from unreliable tests. Because of this, we lack the confidence to remove or not remove the pool request from the queue. Although we continue to refine tests, the situation is as it is, and the system must cope with it.
We have added a fault tolerance threshold and remove pool requests only if the number of consecutive failures exceeds this threshold. The idea is that real failures will persist on subsequent launches, and a false alarm will not be confirmed. A high threshold will increase accuracy, but takes more time. To find a compromise, you can analyze the data with the results of unreliable tests. Suppose that the probability of a false positive is 25%. We calculate the probability of several consecutive false positives.
| Fault tolerance threshold | Probability |
|---|---|
| 0 | 25% |
| one | 6.25% |
| 2 | 1.5% |
| 3 | 0.39% |
| 4 | 0.097% |
From these figures it is clear that with increasing threshold the probability is significantly reduced. It will never drop exactly to zero, but at threshold 3 already close enough brings us closer to this. This means that in the fourth consecutive failure, we will remove the pool request from the queue that does not pass CI.
Bandwidth increase
Another important task of Merge Queue v2 is to increase throughput. Deployment should go on continuously, while ensuring that each deployment contains the maximum number of pool requests that have passed the test.
To guarantee a constant stream of ready pool requests, Merge Queue v2 immediately launches CI for all pool requests that are added to the queue. This prudence is very useful during incidents when the queue is blocked. Since CI is executed before merging with the main branch, even before resolving the incident and unlocking the queue, we already have pool requests ready for deployment. The following graph shows that the number of pool requests in the queue increases during blocking the queue, and then decreases as it is unlocked and the ready pool requests are immediately merged.

In order to optimize the number of pool requests for each deployment, we divide them into queues into packages. A package refers to the maximum number of pool requests that can be processed in a single deploy. Theoretically, large packets increase queue throughput, but also increase risk. In practice, raising too much risk reduces throughput, causing failures that are harder to isolate, and increases the number of rollbacks. For our application, we chose a package size of 8 pool requests. This is a kind of balance between bandwidth and risk.
At each point in time, CI works on three pool requests from the queue. Having a limited number of packages ensures that CI resources are spent only on what is needed soon, and not the entire set of pool requests. This helps reduce costs and resource use.
conclusions
Due to the introduction of Merge Queue v2, we have improved usability, improved security and deployment throughput in production. Although all goals have been achieved for the current scale, we will have to revise our models and assumptions as we grow further. We will focus the next steps on the convenience and providing developers with a context for decision-making at every stage. Queue Merge Queue v2 gave us the flexibility to continue development, and this is only the beginning of our plans to scale the deployment.